Redis is an in-memory database that I really love. It’s one of the rare technologies that make both devs and ops happy. For those who don't know Redis already, here is a small introduction.
There are four main topologies of Redis, and each one has and uses different and incompatible features. Therefore, you need to understand all the trade-offs before choosing one.
Here we go:
The old classic. One big bag of RAM. Scale vertically, easy as pie, no availability, no resilience.
There is a master and there are replicas. The master pushes data to replicas. Replicas don’t talk between themselves.
They are Read-Only and will tell you so if you try to do a SET on them (or any Write operation for what it’s worth).
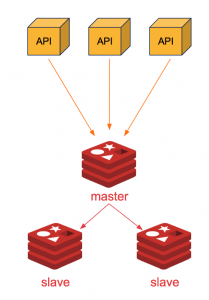
This setup is so easy, you have no excuse to deploy in production a Redis instance without replication.
It's a cheap way to keep your service running when things have gone awry, with just a bit of manual operations. If you are a little to medium-sized organization and it's your first Redis deployment, this may be the best trade-off for you.
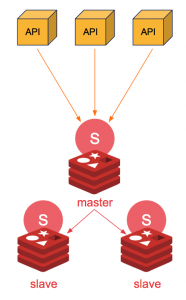
Ok, a bit of history: Antirez, the Redis author, started to work on a concept for Redis clustering some years ago. It turns out, distributed systems are complex and the right tradeoff is hard to reach.
There are two problems with standalone Redis: Resilience, and Scaling. Ok, how about we only solve one?
Redis-sentinel is the solution to resilience, and it’s quite brilliant. It’s a monitoring system on a Redis replicated system (so, a master and N replicas) which aims to answer two questions:
(actually, it also takes care of reconfiguring the Redis instances on the fly so that the newly promoted master actually knows it can accept Write operations)
But, hey, and if we loose the Sentinel? We want resilience after all, so the Sentinels should also be resilient!
That’s why the Sentinels should always be used as a cluster. They have a built-in election system to track who is the master Sentinel (which can elect the master Redis when the current master is down). As it’s a quorum system, you need 3 nodes to support losing 1 (you need the majority of the cluster to be up for a successful election).
Recap: you have 3 nodes with Redis-Sentinel in a cluster, and 2 or more Redis in replicated mode.
You are smart, so you most likely have 3 machines, each hosting both a Redis instance and its Sentinel. This is my preferred topology. You need to deploy your sentinels first, and then you deploy your Redis instances, they register, and it works.
This setup is less easy to put in place. Don’t do it if you are not ready to pay the price. Sadly, Twemproxy is not easier so if you need automated Resilience, this is still your best bet.
This is the Big Gun. The One we waited for so long. It aims to help large deployments, when you need both resilience AND scaling (up to 1000 nodes).
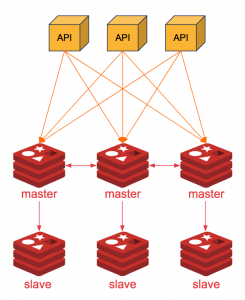
It’s a multi-master architecture: the data is partitioned (sharded) into 16k buckets, each bucket with an assigned master in the cluster, and typically replicated twice. It’s the same design as Kafka or CouchBase. When you SET mykey myvalue, to a Redis-Cluster node:
There is a catch, though. A node is either a master node (it owns a subset of the 16k buckets, monitors other nodes of the cluster, and votes for a new master if one fails), or a replica node (exactly like a Redis replicated, but specific for exactly one master).
Thus, for a reliable cluster, you will need at least 6 nodes. 3 or more master nodes and 3 or more replicas nodes. You need to have the same number of replicas per master if you want to have homogeneous resiliency.
In practice, if you have a Write-heavy workload, keep 2 replicas per master and increase the master count, and if you have a Read-heavy workload increase the replicas per master and use a smart client that can load-balance between replicas (like lettuce).
So there you have it. You may have variations on these deployments but the meat will stay the same. I hope your future Redis deployment will at least be replicated!
Thanks to Sebastian Caceres, Florent Jaby, and Simon Denel for the review.
{kind=link}