To demystify Zero Downtime Deployment
In the patterns associated with the web giants, the Zero Downtime Deployment (ZDD) shares a characteristic with auto-scaling: it is talked about even more because it is implemented so little.
The ZDD is victim of a vicious circle: it looks very complex because it is not very practiced, and as it is little practiced, it is thought to be very complex.
To get out of this impasse, this article presents a practical case, code with support.
The goal is not to make everyone ZDD, because it will add more work and complexity, but provide you a clear vision of how to achieve it. This will allow you to decide whether or not it is worth doing.
Our example approaches the one described in the first article.
An application exposed via a REST API.
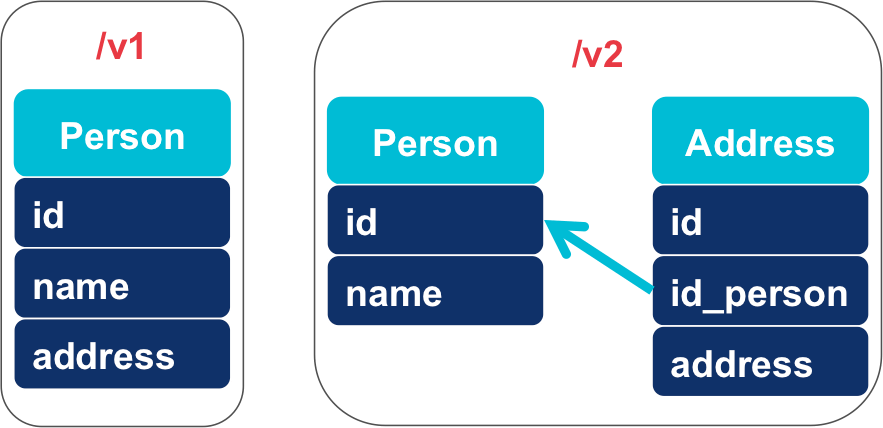
Initially this application manages people, each person having zero or one address. This version is exposed on the prefix /v1 using a unique resource type /person.
The next version of the application will associate multiple addresses to a person, and will be exposed on the /v2 prefix using two resources, /person and /address.
This application highlights its high availability, so it is essential that all operations are carried out without interruption of service.
The API is public, so we do not control the use of it. It is therefore impossible to make a toggle from /v1 to /v2 at one time. The two versions will therefore have to work together to allow the migration of all users. This period may be very long depending on the case.
Customers consume APIs via intermediaries, so it is possible that during this period they use both versions /v1 and /v2.
In the rest of the article, /v1 and /v2 correspond to the versions of the services, and v1 and v2 correspond to the two ways in which the data will be stored in the database.
It is possible to do this without a migration script in the traditional sense: you expose services in /v2, and when called for data still in /v1 format, you migrate the data on the fly. This allows data to be migrated gradually as service users call the APIs /v2. This is the approach that is often taken with NoSQL databases.
Unfortunately, by doing so, the migration may never end, or else it may take a very long time (if you purge older data). During this time, you must maintain the additional code to support this case.
The other approach is to use a script. This ensures that migration takes place quickly. This is the same type of script you use for your usual migrations, except that it must take into account the fact that it runs at the same time as the code. Thus, all operations that create locks for more than a few milliseconds should not be used, and you must ensure that you do not create deadlocks.
Migration must be done in a transactional way, to avoid inconsistencies in the data. In case of problems, the script must also be able to be interrupted and restarted without disrupting the execution of the program.
In the article it is this approach that we will use.
Without ZDD, the migration process is conventionally the following :
In ZDD, there is no longer any question of closing the service: the migration of data takes place "hot".
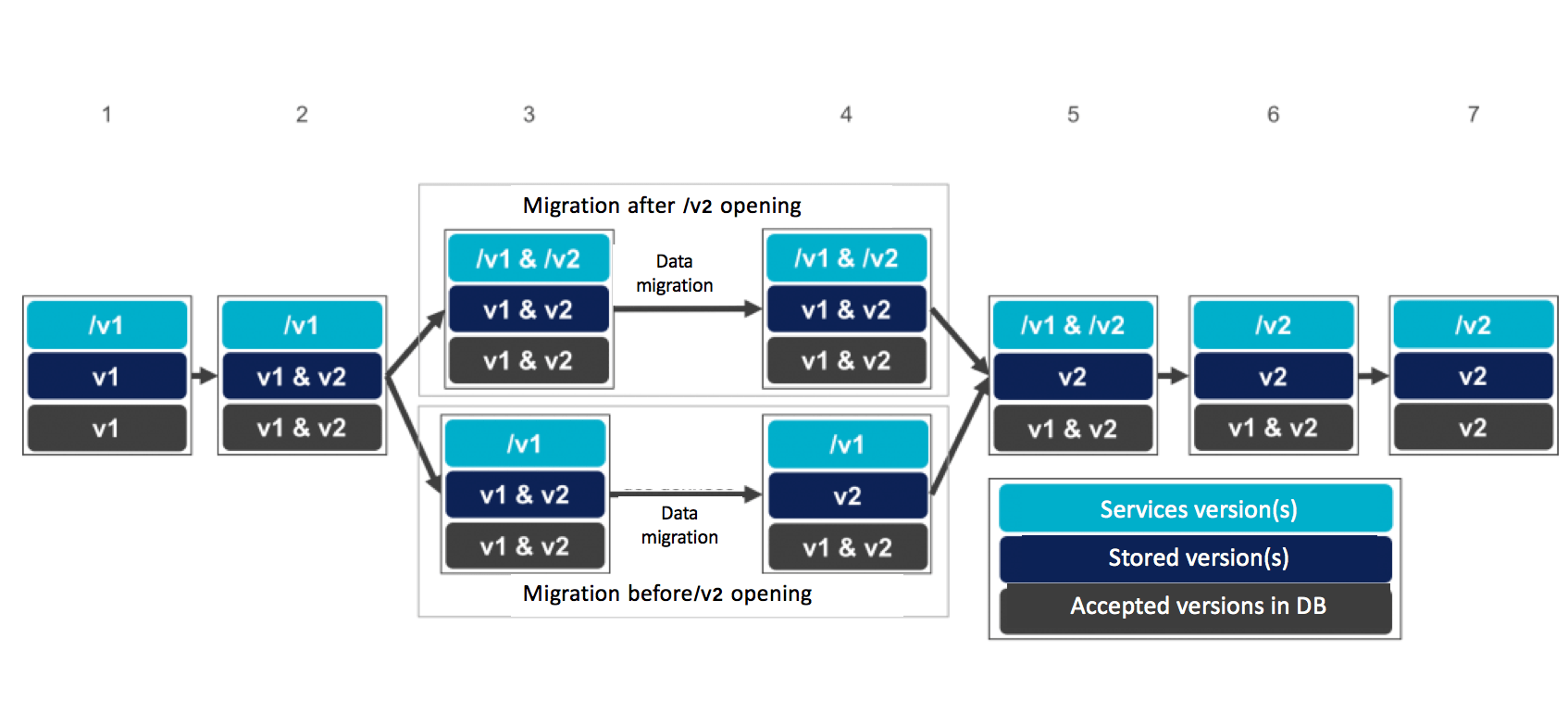
There are two possible ways to do this, depending on whether the migration takes place before or after the services are opened /v2 :
| Number of the stage | Code version | Migration after the opening of /v2 | Migration before the opening of /v2 |
|---|---|---|---|
| 1 | 1 | Application serving /v1 with a data model v1 | |
| 2 | 1 | Change the BDD schema to allow storing the necessary data to /v2 | |
| 3 | 2 | Deploy a new version of the exposed application /v1 and /v2 on the v1 or v2 data model | Deploy a new version of the exposed application /v1 on the v1 or v2 data model |
| 4 | 2 | Migrate data to v2 without disruption, taking into account code /v1 and /v2 | Migrate data to v2 without disruption, considering the code that serves /v1 |
| 5 | 3 | Deploy a new version of the exposed application /v1 and /v2 on the v2 data model | |
| 6 | 3 | Clean BDD Schema of Artifacts v1 | |
| 7 | 4 | Deploy a new version of the manager /v2 application on the data model v2 |
The first approach opens services /v2 faster because there is no need to wait for the data migration.
The second approach is simpler :
v1 and v2 only exposes the services /v1, so you do not need to worry about when a service /v2 call accesses data v1 ;/v2 are not yet exposed, this means fewer data access patterns to consider when designating a migration that avoids data inconsistencies and deadlocks.Unless your migration process is extremely long, the second approach is preferred, and this is the one that will be used in the rest of the article.
/v1 and /v2 are in a boat …Migrations of open APIs pose two business problems and a technical problem.
The first problem, also valid for closed APIs, is how to migrate the data from /v1 to /v2. I do not speak from a technical point of view but from a business point of view: the semantics changes between the two versions, so we must determine how to transform the data from /v1 to /v2 in a logical way, and in a way that does not surprise the users of the API.
In our case the solution is immediate : /v1 has at most only one address, and /v2 can have several addresses, the address of /v1 thus becomes one of the addresses of /v2.
The other problem is how to interpret data /v1 in /v2. If the API is open, your users can call your services /v1 while the data is already in the/v2 model.
It is often more complicated than the first car as the evolutions, the API tend to become richer. Accessing richer data from the /v2 through the narrower prism of the API /v1 can be a real headache.
If this is the only way that this transition happens, it is sometimes necessary to adapt the design of the API /v2.
It is a balance to be found between the transition facility, possible restrictions to add for IPA callers, and the time to invest.
The technical problem is to achieve the various services, including compatibility, while making sure to always have consistent data and without penalizing performance (too much). If, between the two versions, the data is no longer structured in the same way, the compatibility management can request to cross the data of several tables.
So in our example, in v1 the addresses are stored in the person table while in v2 they are in a separate adress table. During the compatibility period, calls to v1 that update the person's name and address change the two tables in a transactional manner to prevent a v1 reading that would occur at the same time from returning inconsistent data . Additionally, you have to be able to do this without having to put too many locks in the database, because otherwise it will make data accesses too rude..
The best strategy is to focus on an approach that you have mastered well and that gives acceptable results rather than a more efficient or faster but more complex solution.
In all cases, tests are absolutely essential.
To serve both versions of the API, you can use a single application or choose to separate your code into two applications, one per service version. This question is not relevant for the question of the ZDD, we choose not to consider it here. In our example, we chose to have only one application.
Without ZDD the situation is clear: we stop the application, the data is migrated, and we restart the application in the new version. So there is a before and an after.
With ZDD the migration takes place while the services are available, so there is an intermediate situation.
During this period, the data can still be stored in /v1 format or migrated to /v2.
It is then necessary to determine in which state the data is: in order to know which code is to be called, it is necessary to know whether the data has been migrated or not. In addition, the piece of code in charge of this will be run very often, so it must be very effective.
In case of difficulty, the solution that should work in all cases is to add to the tables involved a number indicating the "schema version" of the corresponding data, and which will be incremented when the data is migrated. In this case the verification operation is very simple and fast. The column addition operation is then done in advance of phase, which increases the work necessary for the migration.
If you choose to migrate data after opening /v2, the case where an api /v2 is called while the data is still stored in v1 format is added. It is then necessary to migrate the data hot, in a transactional manner by limiting the induced slowdown.
To summarize, there are four situations :
Call/v1 | Call/v2 | |
|---|---|---|
Data stored in format v1 | Reply as before | (Only if migration after opening /v2) Migrate hot data |
Data stored in format v2 | Compatibility v1 | Reply with the new semantics |
/v2, and properly decomission /v1When you open /v2 for the first time, pay attention to how the toggle to the new version is made.
Before making the new endpoints accessible, make sure that all servers use the latest version of the application. Otherwise, if you call a /v1 when the corresponding data has been migrated to v2 the code will not be able to read it correctly and may crash or return false information.
Another problem is the way you have implemented the data changes when you call an API /v1.
The first case is to save the data in v2 format, but this means that the previous versions of the application will not be able to read it again. The easiest solution is to use feature flipping to switch the code.
Otherwise, your code must detect in which format the data is stored, and re-save it in the same format: a piece of data in v1 remains in v1, and a piece of data v2 remains in v2. The feature flipping is avoided, but in exchange the code is more complex.
In order to decommission /v1 it is enough to make the endpoints inaccessible, the deletion of the code can be done later.
As we have seen, the ZDD relies heavily on the use of the database, and in particular its concurrent access features. If your business requirements are simple, you are using an ORM, and you have automated performance tests, this is an area you do not often need to consider. If you do not do it right, it's easy to block the database, return errors (in case of deadlock), or inconsistent results.
Our advice is to document your upstream or even to make POCs to avoid having to redo a design because your database does not work as you imagined. Do not trust memories or rumours: read in detail the documentation for the version of the tool you are using, and most of all ensure that you test !
If you have never dug into these topics or are rusty, the first migration will surely require a lot of work, and will give you a few cold sweats when you run it. But tell yourself that all the subsequent operations will deal with the same concepts, and will therefore go much better.
REST has two features that make it an ideal candidate for the ZDD :
If your services are exposed in any other way, you will need to be interested in these topics. Sessions, like all cache types, may require special attention if the data they contain is subject to a change in version structure.
We assume that the data model directly follows the resources to be exposed. The address is initially a field of the person table, and is migrated to a separate address table.
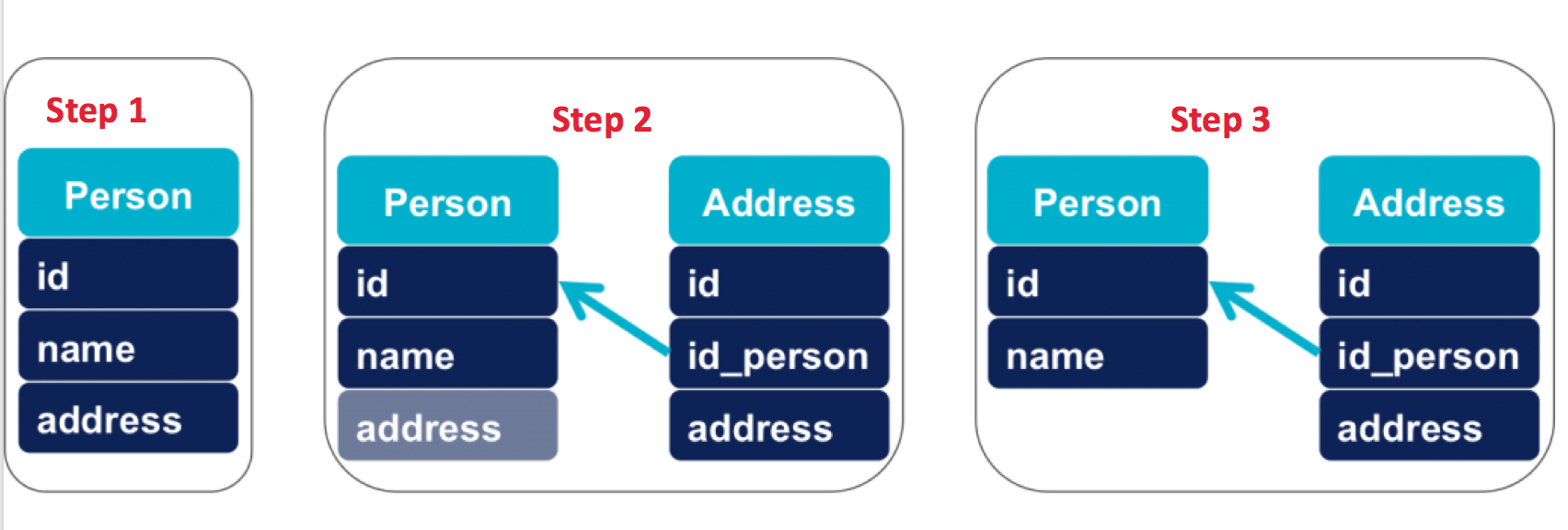
We do not use a specific column to store the "schema version" of the objects. Instead we will check in the database to see how the data is stored: if the person table contains an address, it is because it is in version v1, otherwise it is necessary to check the existence of an address in the dedicated table . This avoids adding to the SQL schema, but increases the number of queries executed.
Steps to follow for migration :
address column of theperson table, the code only works in this way.address in the database, at this stage the code does not yet know this table./v1 and that is compatible with both ways of storing the address./v1 and /v2 and which is compatible with the new way to store the address, the address column of the person table is no longer used by the code..address column of the table person table.The ZDD adds code versions and migrations of intermediate schemas. In an environment where deployments are not automated, this means an increase in workload and therefore the risk of error. So it's better to equip and have a reliable delivery pipeline before you get started.
In our example the problem of compatibility is the following: once a person migrated, it can have several addresses. What do you do when you retrieve that same person through the API /v1 ?
Here there is no obvious answer: there is no notion of preferred address, or last address used that would provide a way of discriminating the different possibilities. Since the response affects the behaviour of the API, it is a decision to be made by those skilled in the art.
The solution chosen here is to return an address from the one in the list. It is not perfect, but it can be acceptable according to the use made of it: it is up to the persons skilled in the art to decide.
To solve the question of transactionality, we chose the simplest solution: put a lock on the corresponding entries of the person table.
If all the operations follow the same principle, this lock acts as a mutex by making sure that the calls are executed one after the other: when an operation poses a risk, it begins by asking for access to this lock, and for this she must wait her turn.
Example with a call to PUT /v1/people/127 while the corresponding person is stored in format v2 but has not yet an address.
Example without lock :
| Execution thread 1 | Execution thread 2 |
|---|---|
PUT /v1/people/127/addresses | PUT /v1/people/127/addresses |
BEGIN | BEGIN |
SELECT * from person where id = 127 to retrieve the person, verifies that there is no address and that the other fields are not to be modified | SELECT * from person where id = 127 to retrieve the person, verifies that there is no address and that the other fields are not to be modified |
SELECT * from address where id_person = 127 to retrieve an address to be updated, does not find it and deduces therefore that it is necessary to insert one | SELECT * from address where id_person = 127 to retrieve an address to be updated, does not find it and deduces therefore that it is necessary to insert one |
INSERT INTO address … to insert the address | INSERT INTO address … to insert the address |
commit | commit |
Result: the person ends up with two addresses !
Example with lock :
| Fil d’exécution 1 | Fil d’exécution 2 |
|---|---|
PUT /v1/people/127/addresses | PUT /v1/people/127/addresses |
BEGIN | BEGIN |
SELECT address from person where id = 127 FOR UPDATE to retrieve the person, verifies that there is no address and that the other fields are not to be modified and locks the line | |
SELECT * from address where id_person = 127 to retrieve an address to be updated, does not find it and deduces therefore that it is necessary to insert one | |
INSERT INTO address … to insert the address | |
commit which releases the lock on person | |
SELECT address from person where id = 127 FOR UPDATE to retrieve the person, verifies that there is no address and that the other fields are not to be modified and locks the line, waiting for the lock on person to be available | |
SELECT id, address FROM address WHERE id_person = 127 retrieves address | |
SELECT * from address where id_person = 127 to retrieve an address to be updated, finds the address inserted by the other thread | |
UPDATE address set address = … where id = 4758 updates address | |
commit which releases the lock on person |
Result: a single address.
The migration script moves the data in blocks of person to address.
In our example, once the code is switched to the new version, all data is written in v2 format, whether it is creatives or changes..
Migration is therefore irreversible, we know that it is enough to migrate all the data once for the work to be done.
It starts by retrieving the highestid of the person . As the script is launched after the new version is deployed, all people created after that time are created with an address stored in address. This means that the script can stop at this value.
The script iterates in groups of person from 0 to the id that it has just recovered. The step of the iteration is to be determined experimentally: a larger step makes it possible to make fewer requests thus to decrease the total time of the migration, to the detriment of the unit time of each iteration, and thus the time when the locks exist in base.
id of people who have an address, and locks them.address with an INSERT … SELECT …`.address field of these entries in theperson table .If the script is stopped, the already migrated data is not lost, and restarting the script does not cause any problems, since the migrated data is not reprocessed.
/v1 and where the address is stored in the address column of the persontable.address table, not yet used by the code. Creating a table does not normally have any impact on the database, but it must be verified./v1, stores the address in the address table and knows how to read it in both places. During a reading in /v1 on a data item /v1 the data is not migrated to v2 to keep the code simpler.address table./v1 and /v2, and only reads it in v2 format, removing the address column from the person table of the code, then the column is always in base.address column of the person table. In some databases, deleting a column triggers the rewriting of the entire table and therefore can not be done in ZDD. We are therefore satisfied with a logical deletion, for example by adding an underscore in front of its name, and by "recycling" it when a new column is needed.The implementation is on GitHub. The code is open source under MIT license, so you can use it..
Each step of the migration is in a separate module, it allows to easily examine what happens without having to handle git.
The code is in Java and references the Dropwizard library. The database is PostgreSQL, access is via Hibernate, and SQL migrations utilize Liquibase.
Some highlights :
address because PostgreSQL simply makes it invisible, and retrieves the space later.Doing ZDD is not magic: it takes work and rigor. If you can do without, so much better for you, but if you need it, you should now have a little more precise idea of what it represents. Remember that the example developed here is a simple case: use it to get an idea of what to do, and not as a guide to measuring effort.
The first migration will surely be a bit of a challenge, but the next ones will be easier. In any case, do not forget to test, test, and still test !