Dans sa première version, Rancher était un projet d’orchestration de conteneurs. Cependant, devant la popularité de Kubernetes, l’éditeur est reparti de zéro pour se recentrer sur le management de clusters dans la version 2.
Ici, nous parlerons exclusivement de Rancher 2.X. Cet article n’est pas un tutoriel sur comment utiliser l’outil mais plutôt un retour d’expériences sur les principales fonctionnalités, que nous avons manipulé (ou pas), après plus d’un an d’utilisation chez un client. À l'heure de l'écriture de cet article, la version de Rancher déployée chez celui-ci est la v2.4.5.
Entre le management des ressources, des droits utilisateurs, des règles réseaux etc., bien administrer un cluster Kubernetes n’est déjà pas chose aisée. Or, il n'est pas rare d'en avoir plusieurs à gérer. Le cas courant que nous rencontrons est un cluster de production et un autre pour les environnements de développement. Les choses se corsent encore un peu plus dès lors qu’on prend la décision de déployer plusieurs clusters sur différentes plateformes ("on-premise" ou fournisseurs cloud) pour des raisons telles que l’optimisation des coûts ou le déploiement d’applications sensibles.
Ainsi, Rancher est un produit open-source pensé pour faire face à ces cas complexes car il permet de centraliser la création et la gestion des clusters Kubernetes via une interface graphique accessible depuis un navigateur web et/ou une API. Il se propose de nous faciliter la vie avec :
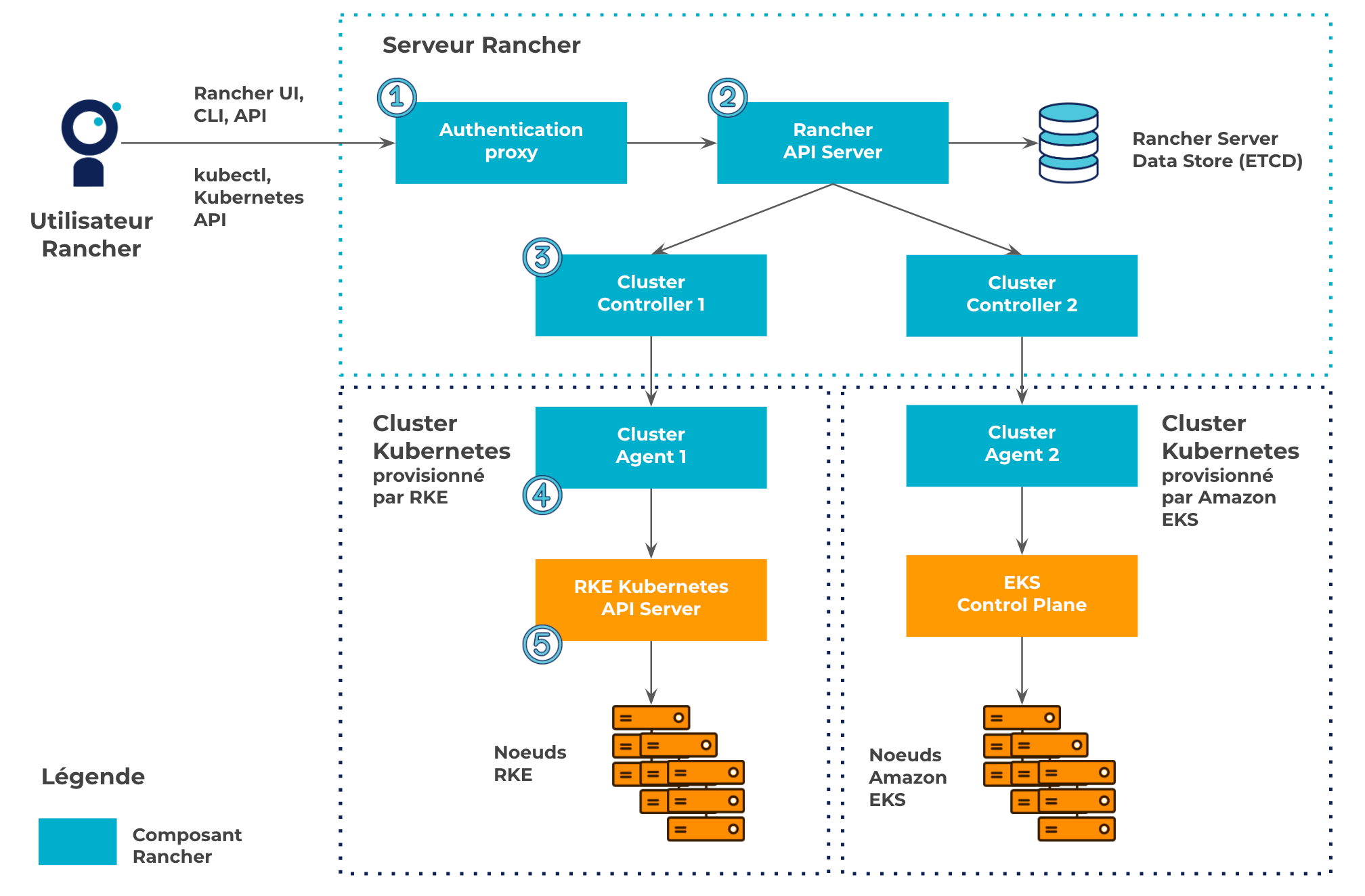
Rancher fait office de proxy pour parler et interférer avec les clusters Kubernetes qu’il manage. Par exemple pour communiquer avec le cluster provisionné par RKE (l'outil maison permettant de déployer un cluster Kubernetes), l’utilisateur s’authentifie d’abord auprès du composant Authentication Proxy de Rancher (1 sur le schéma ci-dessus). Puis, ses requêtes sont transmises à l’API Server de Rancher (2) qui est le hub pour communiquer avec tous les composants de Rancher. Une fois que l’API Server de Rancher a indiqué au bon Cluster Controller (3) l’état à atteindre (NB : chaque Cluster Controller est spécifique à un cluster Kubernetes), celui-ci surveille les ressources du cluster RKE en parlant avec son Cluster Agent (4). En cas de changement, ce dernier se charge de les appliquer en interagissant avec l’API Server (5) du cluster RKE.
Pour déployer Rancher, il existe deux façons :
Entre l’appropriation de la commande kubectl et des manifests Kubernetes, le ticket d’entrée pour déployer et déboguer des applications sur Kubernetes peut s’avérer fastidieux. Cependant grâce à son interface graphique, Rancher permet à des profils débutants de pouvoir entrer et monter doucement en compétences dans l’univers Kubernetes. En effet, depuis l’UI, sans écrire le moindre fichier YAML ou commande kubectl, il est possible de provisionner des clusters, gérer des droits d’accès, déployer une stack de monitoring, manipuler des ressources Kubernetes ou encore d'observer les logs d’un Pod. D’ailleurs, cela a bien aidé les développeurs avec lesquels nous travaillions car ils pouvaient déboguer leurs applications en toute autonomie.
En l’état, manipuler l'API directement est faisable, mais très douloureux, car la documentation est quasi-inexistante. Rancher n’est pas tout à fait mature pour être utilisé avec des outils d’infra-as-code. Nous avons dans un premier temps automatisé les tâches avec Ansible en extrayant nous-mêmes les endpoints et les payloads : ce fut chronophage et pas tout à fait idempotent. Puis, nous avons basculé sur le provider Terraform Rancher2 mais au prix d'un désagrément que nous détaillerons par la suite.
Rancher permet de provisionner rapidement des clusters Kubernetes "on-premise" ou managés sur les principaux fournisseurs cloud (EKS, AKS, GKE). Si les clusters existent déjà, il est aussi possible de les importer dans Rancher. Dans les deux cas, Rancher installera des composants pour communiquer avec ce cluster. Le nom de ces Pods commence par cattle-*.
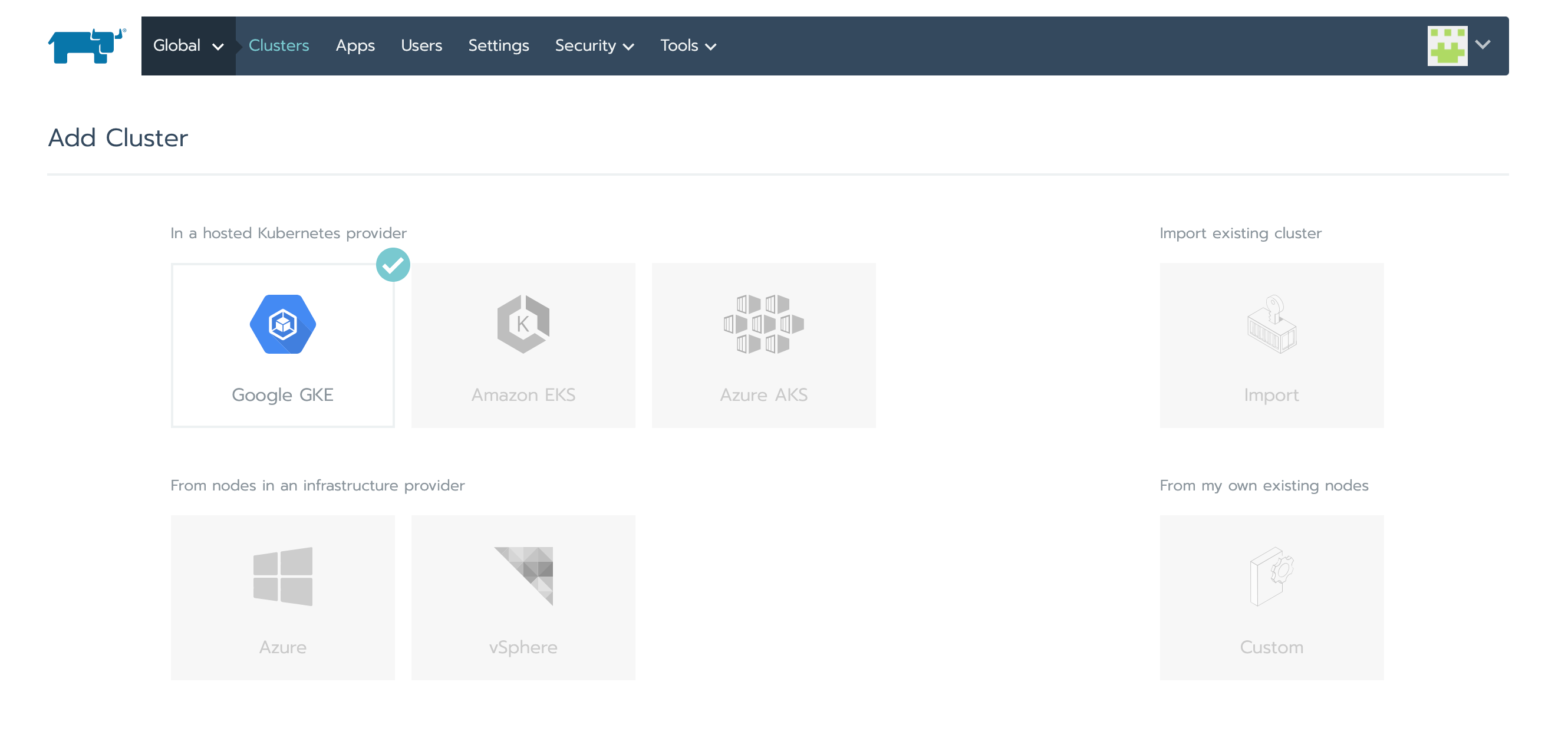
Jongler entre les interfaces ou providers Terraform des différents fournisseurs cloud peut s’avérer pénible, c'est pourquoi pouvoir créer des clusters sur de multiples plateformes via un seul point d’entrée semble séduisant.
Néanmoins, deux problèmes majeurs existent :
Ce dernier point nous fait comprendre que Rancher n’est pas encore mature pour être utilisé avec de l'infra-as-code, du moins avec Terraform.
Comme vu précédemment, Rancher devient le point d’entrée pour interagir avec un cluster Kubernetes. Ainsi, cela permet de disposer d’une procédure d’authentification commune. Il n’est donc plus nécessaire de se soucier des mécanismes de gestion d’identité propre à chaque fournisseur cloud. Si l’administrateur donne les droits d’accès d’un cluster à un utilisateur, Rancher lui génèrera un fichier kubeconfig et un token permettant de s’authentifier. Par la suite, une fois que les permissions aux ressources Kubernetes auront été définies, Rancher s’occupera de créer et modifier les ServiceAccount nécessaires.
Bien qu’il soit possible de déclarer un par un les utilisateurs puis de les inclure dans des groupes, Rancher offre la possibilité, pour nous faire gagner du temps, d’utiliser des services tiers pour s’authentifier tels que : Github, Azure AD, Google OAuth, et bien d’autres encore.

Petite ombre au tableau concernant l’authentification avec Github, les groupes ne sont pas bien gérés à ce jour. Ces derniers ne sont affichés que par leur nom dans l’UI. Ainsi, lorsque deux groupes portent le même nom, il est difficile de savoir lequel sélectionner.
Pour nous faciliter la gestion des droits d’accès et des ressources (CPU & RAM) d’une application, Rancher nous propose de regrouper plusieurs Namespaces au sein d’un Project. Techniquement, Rancher va poser une annotation field.cattle.io/projectId=<ID_du project> sur le Namespace pour savoir à quel Project il appartient.
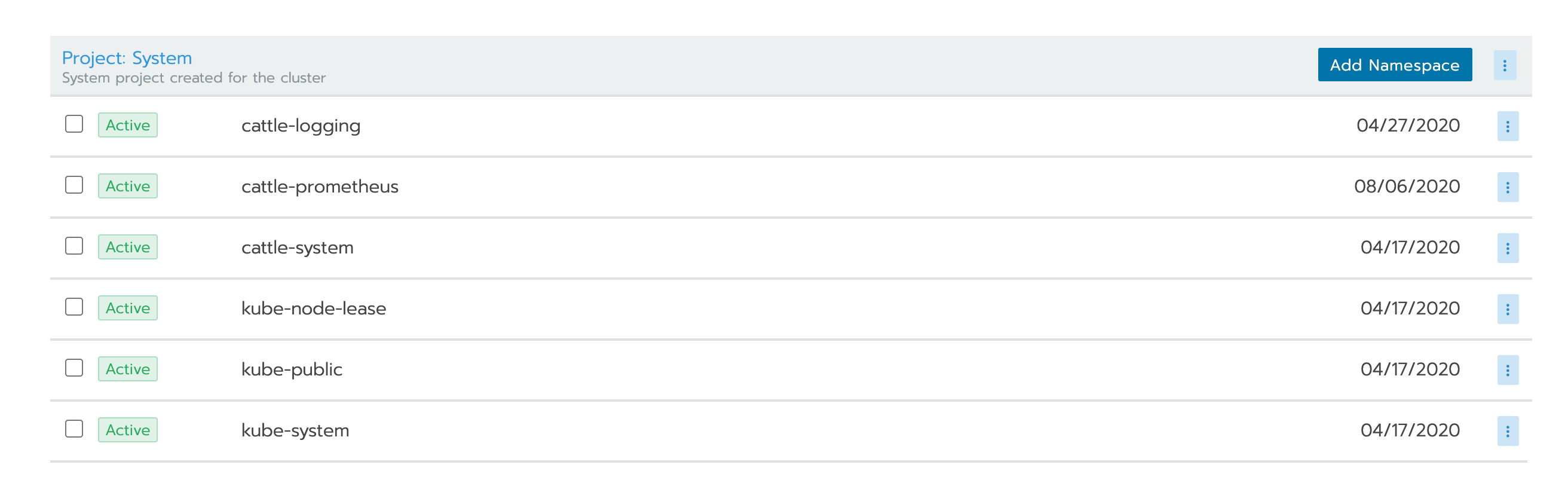
Cette abstraction supplémentaire permet, en autres, d’affecter des droits qui s’appliqueront pour l’ensemble des Namespaces du Project. Ceci peut s’avérer utile dans le cas de "review apps" (1 feature branch Git = 1 environnement) déployées dans un Namespace qui leur sont propre. En effet, il suffit désormais de définir les droits d’accès uniquement sur le Project (et non plus sur chacun des Namespaces) pour que les "review apps" soient accessibles par les personnes autorisées.
En théorie, il est également possible de positionner des contraintes de ressources (CPU & RAM) sur les Projects afin de limiter, par exemple, le nombre de Namespaces au sein d’un Project. Cependant, avec la version 2.2 de Rancher, nous avons eu des comportements erratiques avec des Namespaces qui refusaient d’être créés alors qu’il restait des ressources disponibles. Nous avons donc abandonné l’idée et n’avons pas renouvelé l'expérience sur les versions ultérieures.
En plus de mettre à disposition des Helm Charts vérifiées par l’éditeur, Rancher permet d’importer des catalogues de Charts dans son interface pour ceux qui souhaitent déployer des applications via l’UI. Nous avons utilisé cette fonctionnalité essentiellement pour tester rapidement des outils. Si le POC (proof of concept) était validé, le produit était déployé avec de l'infra-as-code.
Nous n’avons pas utilisé la possibilité de déployer une application, avec la même configuration sur plusieurs clusters (type cert-manager ou kubed), via son interface, car de notre point de vue, cela se gérait mieux avec de l'infra-as-code.
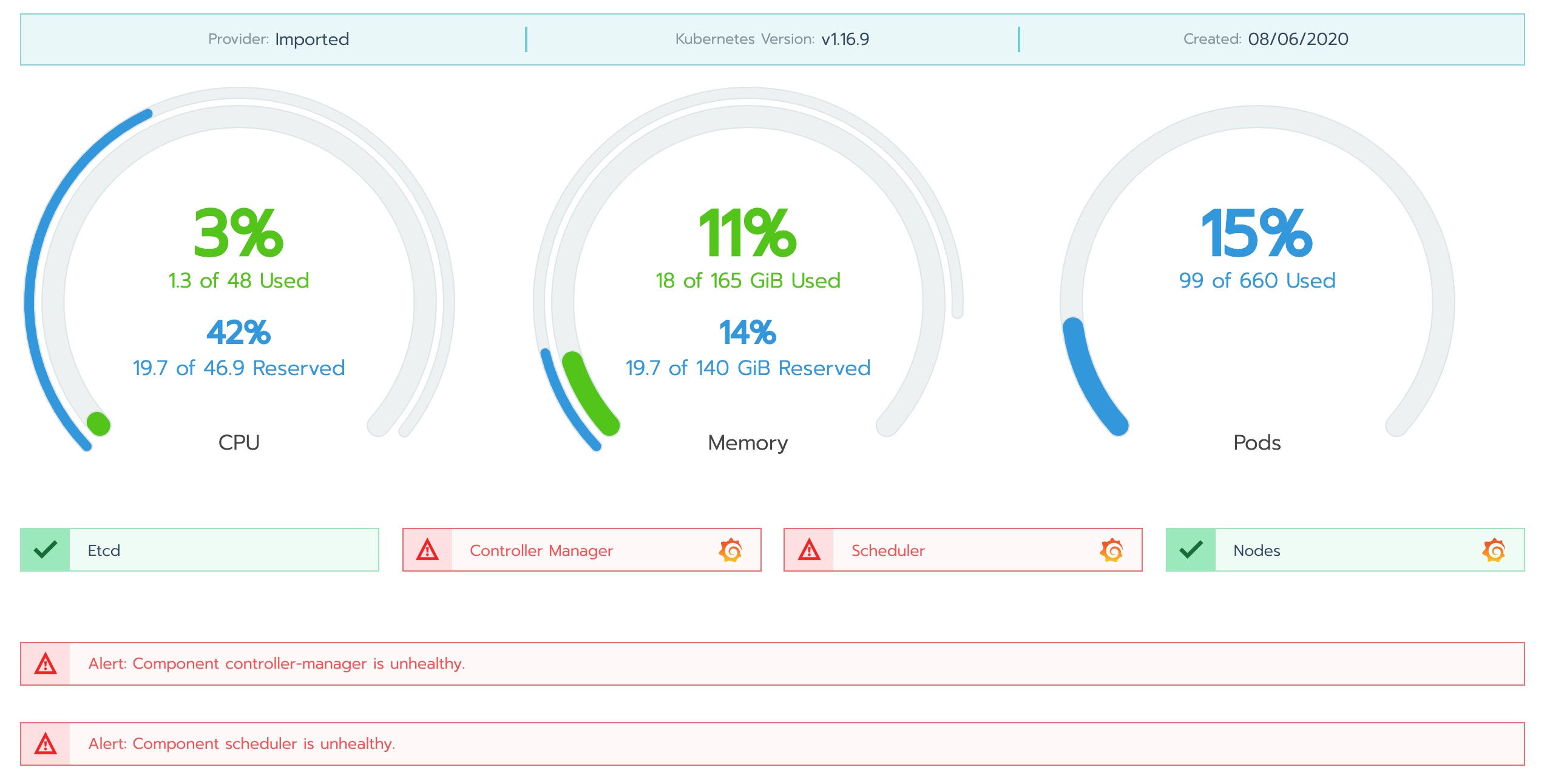
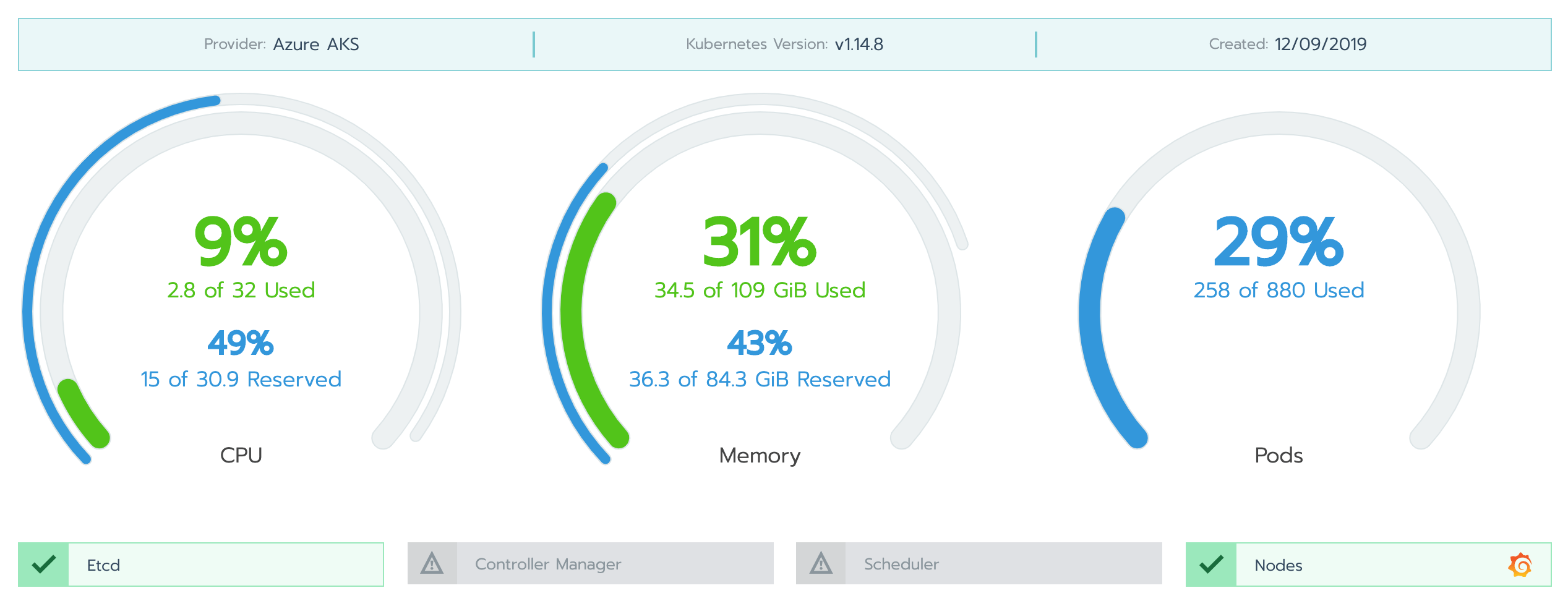
Par défaut, Rancher expose des tableaux de bord avec les informations de base issues de metrics-server tels que : l’utilisation des CPU, de la RAM, le nombre de Pods déployés etc (cf. images du paragraphe "La création de cluster Kubernetes sur différentes plateformes"). De plus, l’interface permet de voir facilement les Pods en erreur en affichant ces derniers en rouge.
Si l’on désire aller plus loin, Rancher permet de provisionner facilement une stack de monitoring basée sur le couple Prometheus/Grafana (un prometheus-operator est alors déployé) via son interface ou le provider Terraform Rancher2. Une icône Grafana apparaîtra par la suite et il suffira de cliquer dessus pour ouvrir le dashboard.
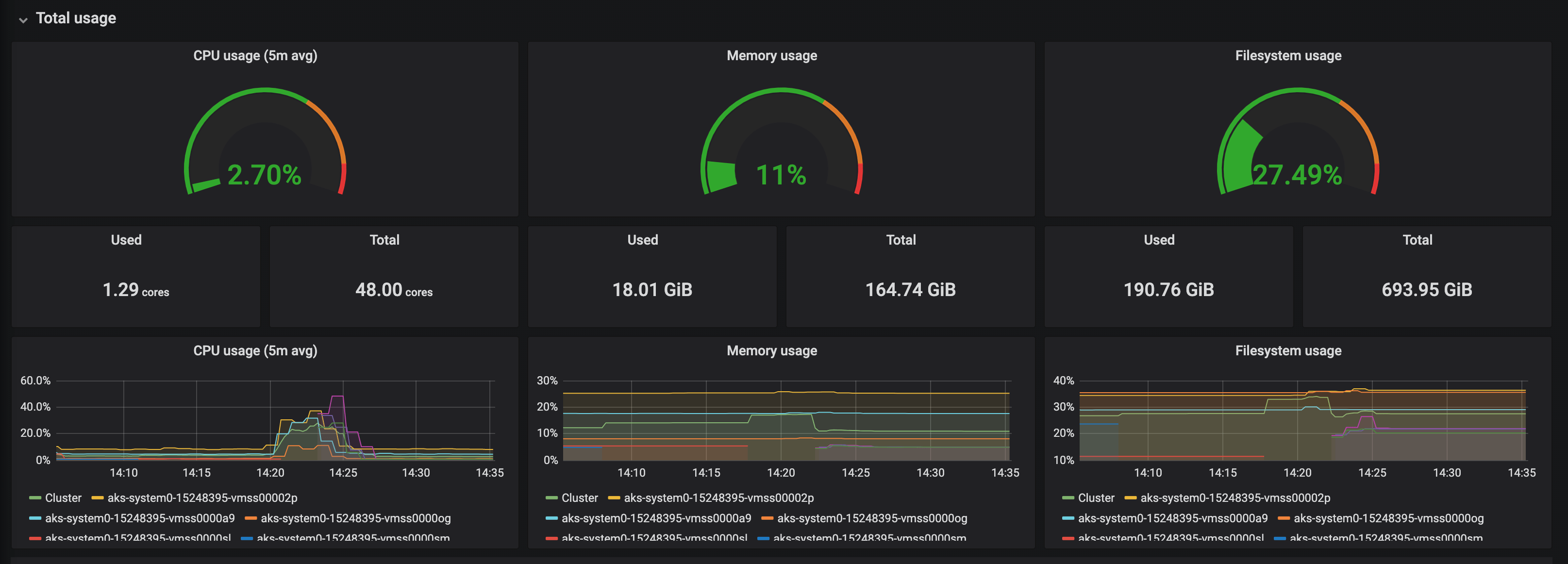
Il est également possible d’activer le monitoring pour chaque Project. Les dashboards ne comporteront alors que les métriques des applications et seront uniquement accessibles par les membres autorisés. Bien que cette fonctionnalité permette d’avoir rapidement des tableaux de bord spécifiques pour chaque équipe de développement, il faut néanmoins garder en tête que cela consomme beaucoup de ressources car une nouvelle instance de Prometheus et Grafana sera déployée à chaque fois.
Aussi, il faut savoir qu'inclure des configurations personnalisées de Prometheus et de Grafana n’est pas aisé. De plus, ces dernières ne persisteront pas en cas de désactivation puis de réactivation du monitoring car le Namespace contenant les Pods Prometheus et Grafana sera détruit et les nouveaux seront déployés dans un Namespace différent dont le nom est aléatoire.
Provisionner des clusters sur des fournisseurs cloud différents oblige à utiliser des services propriétaires et payants (Cloudwatch pour EKS, Log Analytics pour AKS) pour obtenir les audits logs du cluster Kubernetes (logs d’activité des utilisateurs). Au-delà d’une contrainte financière, ceci peut également s’avérer problématique si l’on souhaite centraliser leurs exploitations du fait des solutions propriétaires des fournisseurs cloud.
Cependant, puisque toutes les requêtes passent par l’API Server de Rancher avant d’interagir avec un cluster managé, il est possible d’utiliser les audit logs de Rancher pour tracer les activités des utilisateurs. Pour cela, il faut activer la fonctionnalité à partir de la Chart Helm de Rancher qui créera un conteneur "sidecar" rancher-audit-log pour streamer les logs sur la sortie standard (stdout). Il sera ensuite facile de les exploiter avec un service de collecte de logs. Bien sûr, si quelqu'un interagit directement avec un cluster sans passer par Rancher, cela ne sera pas tracé.
Rancher permet d’expédier les logs des Pods, présents dans /var/log/containers, vers les outils suivants : Elasticsearch, Splunk, Kafka, Syslog et Fluentd. Il est possible d’activer cette fonctionnalité pour chaque cluster et Project.
Pour le cas d’Elasticsearch, après avoir renseigné l’URL et les identifiants du service, Rancher provisionnera un DaemonSet Fluentd pour collecter et envoyer les logs sur le moteur d’indexation. Ces derniers seront sauvegardés dans le même index et "parsés" avec des règles prenant en compte les principaux standards (Docker, Nginx, etc.). Il est possible de customiser le "parsing" des logs (par exemple pour les anonymiser) en modifiant la configuration de Fluentd mais, comme pour le monitoring, l’implémentation n’est pas triviale et celle-ci ne persistera pas en cas de désactivation de la fonctionnalité.

D'après mon expérience, l’utilisation de Rancher est pertinente si en premier lieu les environnements sont déployés sur différentes plateformes. Lorsque les clusters sont provisionnés chez le même fournisseur cloud, il est sans doute plus judicieux d’utiliser les services qu’ils offrent pour exploiter les environnements. De plus, cela permettra de bénéficier de fonctionnalités avancées que l’API de Rancher ne prend pas en compte.
Si les clusters sont déployés sur différentes plateformes, il conviendra ensuite d’analyser le type de profil qui administrera ou exploitera l'infrastructure. Il faut bien comprendre que Rancher est pensé pour être utilisé via son interface. Cela devient vite contraignant dès lors que l’on souhaite automatiser les tâches avec de l'infra-as-code ou sortir du cadre que nous impose l’outil. Cependant, tous les profils ne sont pas techniques ou ne sont pas familiers avec l’univers Kubernetes. L’interface graphique de Rancher pourra alors les rassurer et leur permettre de monter progressivement en compétences sur le sujet. Pour les plus aguerris ayant une contrainte de temps, Rancher leur permettra quand même d’obtenir un "quick win" en déployant des clusters Kubernetes multi-cloud avec des services (monitoring, collecte de logs) prêts à l’emploi utilisant des outils reconnus par la communauté et avec une gestion d’authentification commune. Au delà, l'outil montrera ses limites.