Après quelques missions d’infra diverses et variées en utilisant ce formidable outil qu’est Terraform, on s’est dit qu’il était nécessaire de partager ce que nous avons appris.
Et des choses… nous en avons apprises ! Tellement, qu’un seul article ne serait pas suffisant. Nous vous proposons donc une série d’articles pour aborder l’utilisation de Terraform… at scale !
Dans ce premier article nous aborderons le sujet de l’organisation du code Terraform pour une grosse infrastructure (le layering pour les intimes).
Avertissement: Cet article vise un public qui aura au moins une première expérience avec Terraform.
Lorsque l’on écrit du code Terraform “classique”, celui-ci est placé dans un répertoire et le développeur est libre d’organiser son code comme il l’entend. Peu importe le nom des fichiers, ils seront tous lus à condition qu’ils aient l’extension .tf. C’est l’outil qui construit un graphe à partir de la liste complète des ressources et qui orchestre la création de l’infrastructure en le parcourant. Il est d’ailleurs possible de générer un schéma de ce graphe, ce qui peut par exemple, venir enrichir votre documentation.
Cette organisation du code vient avec une limitation, et pas des moindres : une seule personne peut travailler à la fois sur un changement de l’infra.
Explication :
Le tfstate est un composant critique de Terraform qu’il est important de conserver sur un espace partagé (s3, gcs ou storage account pour les 3 principaux Cloud Provider) qui supporte le mécanisme de lock pour éviter les écritures concurrentes.
Avec un code monolithique, l’état de votre infra est stockée dans un seul et même tfstate et l'exécution d’une commande Terraform (plan ou apply à minima) entraînera un lock et par extension, l’impossibilité pour un autre développeur d'exécuter une commande de son coté. Peu importe donc la taille de votre équipe, il faudra faire la queue pour faire une modification !
Pour un gros projet d’infrastructure avec beaucoup de ressources et plusieurs membres d’une même équipe, cette limitation devient très vite un problème car cela va rythmer la capacité à faire de l’équipe... et rarement au rythme que l’équipe souhaiterait avoir !
Autre exemple, considérons que nos développeurs n’effectuent pas leur commandes en même temps, mais suffisamment espacée dans le temps pour que le “lock” du premier développeur ai été levé au moment de l'exécution des commandes du second développeur. Le second développeur n’ayant pas les modifications apportée par son collègue, la commande apply va tout simplement entraîner la suppression des modifications qu’il aura apporté. Pas facile de tester nos modifications si celle-ci peuvent disparaître à tout moment !
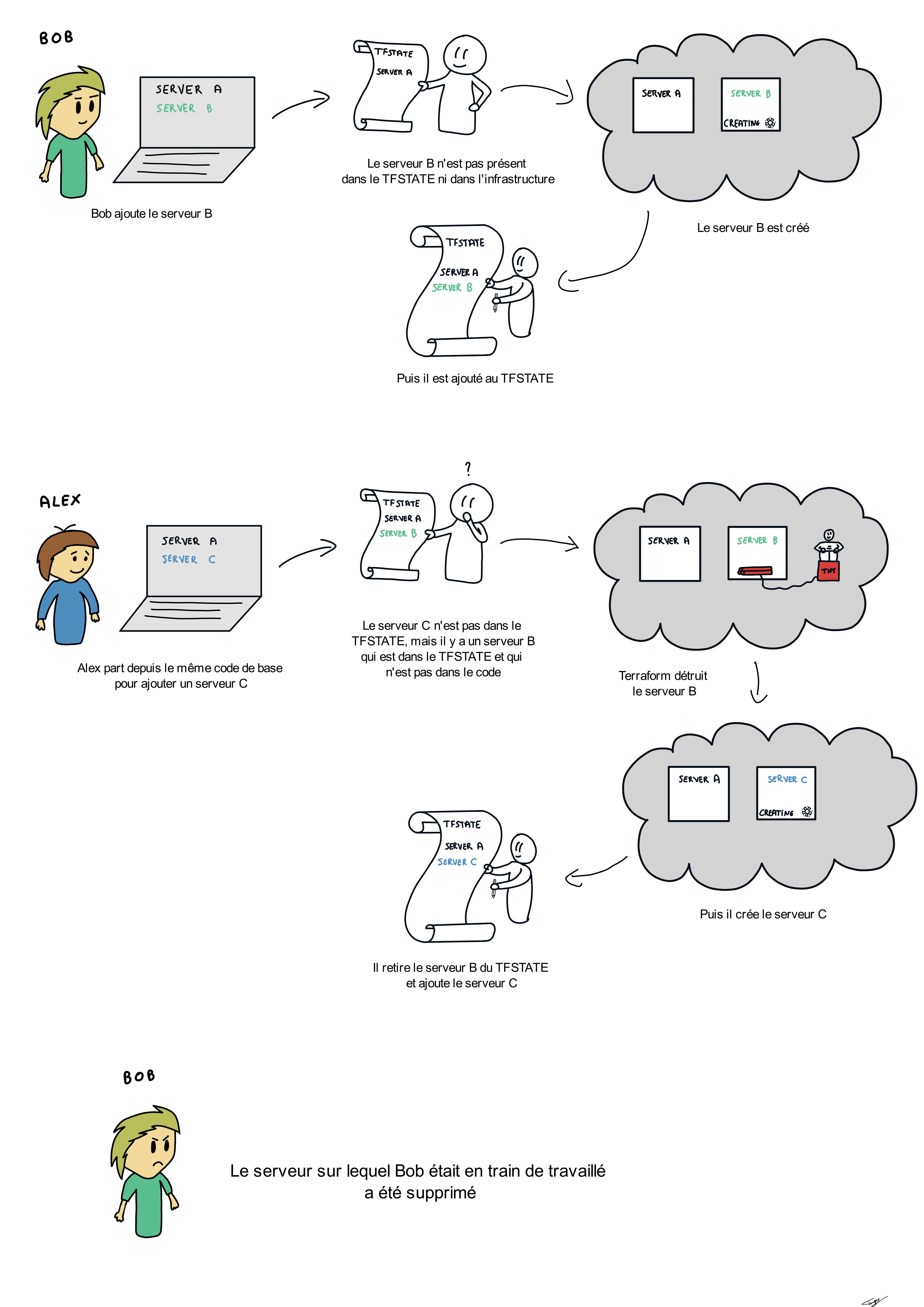
"Ils n’ont qu'à travailler sur une instanciation différente de l’infra !" me direz-vous ?
…
Sur un petit projet pourquoi pas, mais sur un gros projet d’infrastructure, les coûts associés rendent l’opération impossible (trop cher et trop long).
Autre impact ; le temps d'exécution des commandes plan et apply s’allonge avec l’agrandissement de votre infrastructure. Nous avons vu des projets être énormément ralentis par les temps d'exécution de la CI sur leur patchs (jusqu’à 10 minutes juste pour le `plan`), étape incontournable permettant la validation d’un changement.
Combinez le temps d’attente avec la contrainte d’avoir un seul changement à la fois sur l’infrastructure et vous vous retrouvez avec une équipe qui passera son temps à attendre le feedback de la CI.
Terraform contient quelques solutions à ces problèmes :
plan par exemple, et n’autoriser le apply que sur la CI par exemple.plan ou apply (cela se fait “in memory”, et n’est donc pas persisté dans le `tfstate`). Il peut aider à accélérer vos `plans` en ne faisant pas d’appels d’API au “cloud provider”. On passera également à côté de possibles divergences entre le tfstate et l’état réel de l’infrastructure.Vous l’aurez compris, si des solutions de contournement existent, il s’agit principalement de “petits hacks” qui risquent de vous apporter des problèmes sur le long terme.
Maintenant que les problèmes sont posés, nous pouvons parler du layering, car cette technique d’organisation du code va nous aider à résoudre une grande partie de ces problèmes.
Le layering est une technique d’organisation du code Terraform qui n’est pas toute nouvelle.
Vous pourrez trouver des articles de blog relatant de la technique qui sont bien plus vieux que le nôtre(1)(2). Mais ce n’est qu’en 2020 que Hashicorp publiera un article qui décrit le fonctionnement sans mentionner le terme de layering(3).
Le principe repose sur un découpage de l’infrastructure en couches (layers) logiques et de représenter ces couches sous forme de répertoires distincts.
Le déploiement d’une infrastructure ne se fera donc plus en executant Terraform dans un seul répertoire, mais dans autant de répertoires qu’il y aura de couches.
On notera également l’introduction d’un tfstate pour chacune des couches isolant ainsi la gestion des ressources.
Chacune des couches pourra souvent être gérée avec l’appel d’un seul module Terraform, rendant l’infrastructure très modulaire et facilement testable. Nous aborderons le sujet des tests dans un autre billet de cette série d’articles.
Afin de rendre le principe plus parlant, prenons un exemple d'architecture volontairement simplifiée permettant de comprendre la logique :
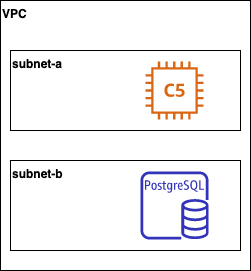
Pour cette architecture, le découpage en couches serait le suivant:
L’implémentation du layering reviendrait à mettre en place l’arborescence suivante:
├── 10-network
│ ├── README
│ ├── main.tf
│ ├── outputs.tf
│ └── variables.tf
├── 20-compute
│ ├── README
│ ├── main.tf
│ ├── outputs.tf
│ └── variables.tf
└── 30-database
├── README
├── main.tf
├── outputs.tf
└── variables.tf
La numérotation des répertoires permet de voir en un coup d’oeil l’ordre d'exécution des couches. L’utilisation d’un incrément de 10 (et non pas de 1) permettra d'insérer une nouvelle couche entre deux couches existantes lorsqu’un nouveau besoin émerge.
Nous pourrons par exemple insérer une couche 15-peering si le besoin émerge dans le projet.
Les couches supérieures ne sont pas totalement indépendantes, car elles peuvent reposer sur une couche inférieure. Les instances de compute, par exemple, ont besoin d’une référence au subnet dans lequel elles vont être lancées.
Pour effectuer ces références, nous utiliserons les datasources de Terraform afin de retrouver les ressources créées par la couche précédente.
Prenons nos couches et regardons ce que le code Terraform peut donner en utilisant les modules Terraform pour AWS que nous trouvons sur le registre public :
Dans la couche 10-network, nous pouvons appeler le module vpc/aws, qui permet de créer toute une partie de la couche réseau :
# 10-network/main.tf
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
name = "my-vpc"
cidr = "10.0.0.0/16"
azs = ["eu-west-1a"]
private_subnets = ["10.0.1.0/24"]
public_subnets = ["10.0.101.0/24"]
enable_nat_gateway = true
enable_vpn_gateway = true
}
provider "aws" {
version = "~> 2.0"
region = "eu-west-1"
}
La seconde couche peut créer les instances avec le module ec2-instance/aws également disponible sur le registre public.
Cette couche repose sur la couche 10-network, et nous allons devoir faire reference au subnet qui y est créé à l'aide d'une datasource. Le module aws/vpc utilisé précédemment utilise une convention de nommage qui permet d'anticiper le nom des subnets créés, nous pouvons donc :
# 20-compute/main.tf
data "aws_subnet" "public" {
filter {
name = "tag:Name"
values = ["my-vpc-public-eu-west-1a"]
}
}
module "ec2_cluster" {
source = "terraform-aws-modules/ec2-instance/aws"
version = "~> 2.0"
name = "my-cluster"
instance_count = 1
ami = "ami-ebd02392"
instance_type = "t2.micro"
key_name = "user1"
monitoring = true
vpc_security_group_ids = [] # vide pour ne pas alourdir l'exemple
subnet_id = data.aws_subnet.public.id
}
provider "aws" {
version = "~> 2.0"
region = "eu-west-1"
}
Dans cette exemple les valeurs sont codées en dur, dans un vrai cas d'usage il sera bien sur attendu de variabiliser au maximum pour rendre le tout plus utilisable.
Si deux modifications doivent être faites sur la même couche, nous restons confrontés aux limitations que j’ai listées en début d’article.
Cependant, cette organisation apporte un gain immédiat ; chaque couche d’infrastructure permet un niveau de parallélisation du travail sur l’infra :
Ces opérations sont possibles en parallèle car chaque couche à son propre tfstate et le lock sur le tfstate ne verrouille qu’une sous partie de l’infrastructure. Avec un éclatement du code monolithique en 3 couches, nous passons donc de 1 à 3 tâches pouvant être effectuées en même temps par des membres d’une équipe.
Il est possible de découper encore plus les couches en séparant chaque groupe de machine, chaque réseau, chaque stockage objet pour limiter encore plus les risques de collisions lorsque plusieurs personne travaille dans le même repo.
Le nombre limité de ressources dans chaque couches permet également d’avoir un temps d'exécution des commandes plan et apply plus court que si toute l’infrastructure était gérée dans une même couche.
Cette organisation du code est tout de même accompagnée d’inconvénients. L'exécution du code va demander un peu plus de travail car il faudra exécuter les commandes Terraform dans chaque répertoires au lieu d’un seul avec un code monolithique.
Il y a deux manières d’aborder cette problématique:
Les deux méthodes ont leur avantages et inconvénients :
À vous de choisir ce qui est acceptable pour votre équipe. De notre côté, nous avons opté la plupart du temps sur la deuxième solution. Certains d’entre nous ont même rendu leur code Open Source.
Nous vous parlerons dans un autre billet de Terragrunt, un wrapper autour de Terraform qui permet (entre autres) de gérer l'exécution de toutes les couches simplement. Mais l’outil mérite plus que quelques lignes dans un article, il faudra donc attendre le billet dédié à l’outil dans cette série d’articles.
Dernier point, mais pas des moindres, certaines modifications dans l’infra peuvent nécessiter des modifications dans plusieures couches.
Si nous voulons améliorer la disponibilité de notre solution par exemple, nous pourrions ajouter un subnet dans une nouvelle zone de disponibilité, et étaler nos instances dans ce nouveau subnet.
Cette modification nécessite une modification dans la couche 10-network et dans la couche 20-compute.
Oui mais voilà, si nous effectuons ces deux changements en même temps et que nous soumettons notre patch à notre outil de CI, l’étape de plan exécutée dans la couche 20-compute échouera lors de la tentative de résolution de la datasource du nouveau subnet car celui-ci n’existe pas encore, l’apply dans la couche 10-network n’ayant pas encore été appliqué !
Cette modification devra donc être effectuée en deux temps :
La deuxième étape ne pouvant être effectuée que lorsque la première a déjà été faite.
Ce fonctionnement est certes contraignant, mais il est également en adéquation avec des principes populaires du développement logiciel : faire de petits changement déployés fréquemment jusqu’en production afin de limiter l’impact de chaque déploiement.
Ce principe s’applique également à l’infrastructure !
Selon les points de vue, ce dernier impact peut être perçu comme un avantage ou un inconvénient suivant les pratiques et la maturité de votre équipe.
Résumons en quelques points les avantages et inconvénients du code monolithique et du layering :
Avantages :
Inconvénients :
Pour un petit projet dont l’infrastructure n’évoluera pas ou peu, le code monolithique fera parfaitement l’affaire, car vous ne serez probablement pas confronté à la nécessité d’effectuer de nombreux changements en parallèle sur l'infrastructure. Mais sur un gros projet nécessitant de faire évoluer en parallèle plusieurs parties de l’infrastructure (réseau, monitoring, etc ...), le layering sera rapidement un atout pour l’équipe en charge de l’infrastructure.
Nous vous recommandons d’utiliser le layering comme organisation du code par défaut lorsque la vision finale de l’infrastructure n’est pas définie ou que la taille de votre infrastructure est significative. Sur un petit projet, le layering sera cependant probablement trop coûteux à mettre en place et n'apportera pas grand chose par rapport à un code monolithique.
Dans le doute, l’utilisation du layering vous permettra d’éviter les embûches, mais si vous partez sur un code monolithique, le passage au layering vous coûtera cher car il faudra prendre en charge le déplacement des ressources d’un tfstate à l’autre avec les commandes import et state rm (ou state mv).
Dans le prochain article de la série, nous aborderons le sujet des modules Terraform et des challenges autour de la maintenance de ce code qui a vocation à être partagé.