Dans tout système d’information, les données sont un actif important qu’il faut capturer, conserver et traiter de façon fiable et efficace. Là où un serveur central joue très souvent le rôle de gardien des données, la majorité des grands du web ont opté pour une autre stratégie : le « sharding » ou distribution des données [1].
Le sharding décrit ainsi un ensemble de techniques qui permet de répartir les données sur plusieurs machines pour assurer la scalabilité de l’architecture.
Avant de détailler l’implémentation, revenons sur les besoins d’origine. On retrouve chez les grands du web plusieurs problématiques communes assez connues : le stockage et l’analyse d’énormes quantités de données, [2], des enjeux forts de performance pour avoir des temps de réponse faibles, des enjeux de scalabilité [3] voire d’élasticité [4] liés aux pics de consultation.
Je souhaiterais insister sur une particularité de ce type d’acteur qui sous-tend nombre des problématiques précédentes. La rémunération des grands du web est bien souvent indépendante de la quantité de données manipulées : rémunération par la publicité, facturation de l’utilisateur au forfait [5]. Cela nécessite d’avoir un coût unitaire par transaction très faible. En effet, dans un SI classique, une transaction peut facilement être rattachée à un flux physique (vente, stockage d’un produit). Ce flux permet d’avoir une facturation du SI proportionnelle au nombre de transactions (conceptuellement par une sorte de taxe). Mais sur un site de commerce marchand par exemple, chaque consultation du catalogue ou ajout dans le panier ne générera pas forcément du revenu car l’utilisateur peut quitter le site juste avant la validation du paiement.
En somme, les Systèmes d'Information des grands du web sont contraints d’assurer une scalabilité à coût marginal très faible pour répondre à leur business mode
Les bases de données restent encore majoritairement sur un modèle centralisé : un serveur unique, éventuellement redondé en mode actif/passif pour la disponibilité. La solution la plus courante pour supporter plus de transactions est la scalabilité verticale ou « scale up » : acheter une machine plus puissante (plus d’IO, de CPU, de RAM...)
Cependant cette approche présente des limitations : une seule machine très puissante ne peut pas suffire pour indexer le web.
Mais au-delà de cela, c’est souvent l’aspect coût et investissement qui conduit à rechercher une autre approche.
Une étude [6] menée par des ingénieurs de Google montre que dès que la charge dépasse la taille d’un grand système, le coût unitaire sur des grands systèmes est très supérieur au coût unitaire sur des machines de grande série [7].
Même si l’équation pour comparer des coûts par transaction n’est pas simple à poser et peut être sujette à débat - complexification de l’architecture, charge réseau à prendre en compte dans les coûts - les grands du web ont largement choisi d’utiliser des machines de grande série.
Pour mettre en œuvre cette scalabilité horizontale, le sharding devient nécessaire.
Il existe de fait 2 façons de partitionner (« sharder ») la donnée : verticalement ou horizontalement.
Le partitionnement vertical est le plus communément utilisé : il s’agit d’isoler, de séparer des concepts métier. Par exemple, on décidera de stocker les clients sur une base et leur contrat sur une autre.
La notion de partitionnement horizontal renvoie à l’idée de répartir l’ensemble des enregistrements d’une table (au sens d’une base de données) sur plusieurs machines. Ainsi, on choisira par exemple de stocker les clients de A à M sur une machine #1 et les clients de N à Z sur une autre machine #2. Le sharding horizontal nécessite une clé de répartition – la première lettre du nom dans l’exemple.
C’est principalement le type de sharding horizontal qui est mis en œuvre chez les grands du web. Il présente notamment l’avantage de ne pas être limité par le nombre de concepts comme c’est le cas pour le sharding vertical.
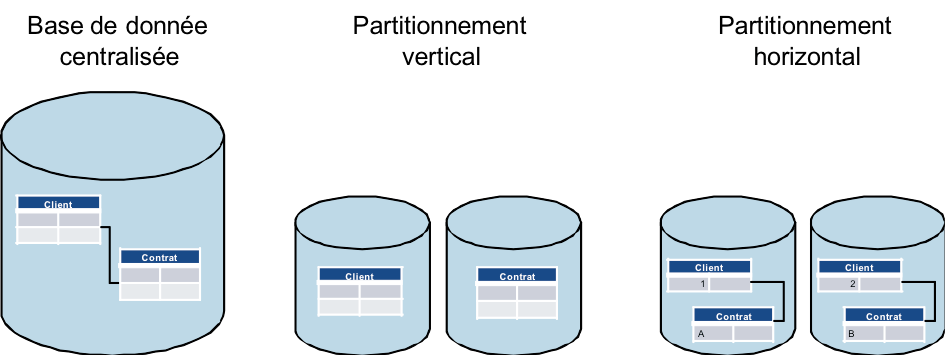
Figure 1
Les grands du web ont, sur la base de ce choix de scalabilité horizontale, développé des solutions spécifiques (regroupées sous l’acronyme NoSQL) répondant à ces enjeux et ayant les caractéristiques suivantes :
Si le sharding permet de répondre aux problèmes évoqués plus haut, il nécessite aussi de mettre en œuvre de nouvelles techniques.
Le sharding nécessite également d’adapter les architectures applicatives :
La mise en œuvre de ces techniques diffère entre les acteurs. Certains ont simplement adapté leurs bases de données pour faciliter le sharding. D’autres ont écrit des solutions NoSQL qui leur sont propre. En suivant ce cheminement de SQL à NoSQL je vous propose de découvrir quelques implémentations représentatives :
La célèbre encyclopédie collaborative est basée sur de nombreuses instances de MySQL réparties et un cache mémoire memcached. C’est ainsi un exemple de mise en œuvre du sharding avec des composants assez répandus.
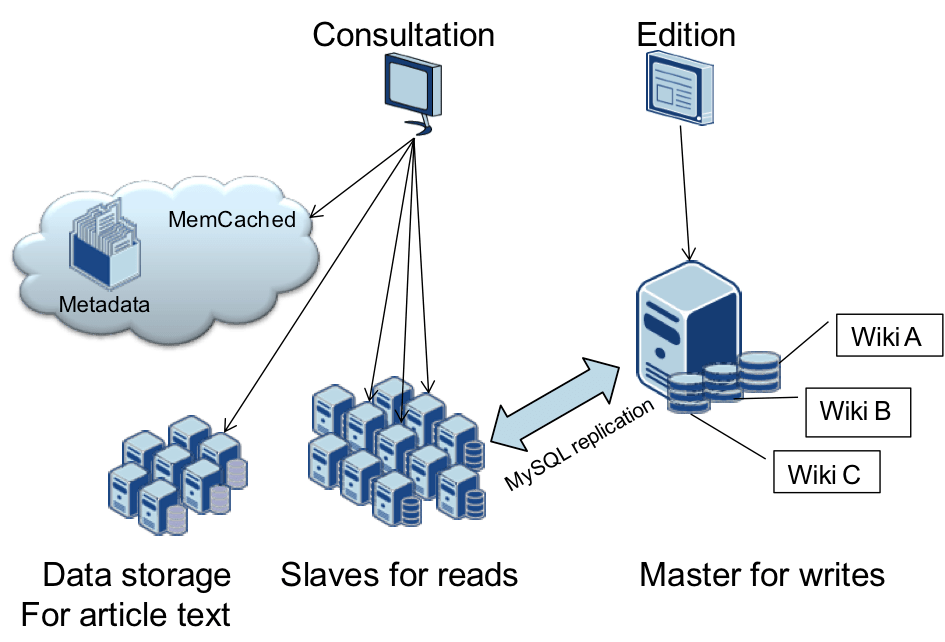
Figure 2
L’architecture utilise d’une part la réplication maître esclave pour séparer les charges de lecture et d’écriture et en partitionne d’autre part les données par Wiki et par cas d’utilisation. Le texte des articles est également déporté dans des instances dédiées. Ils utilisent ainsi des instances MySQL avec 200 à 300 GB de données.
L’architecture de ce site de partage de photos est basée là aussi sur une organisation de plusieurs instances MySQL (les shards) maîtres et esclaves mais cette fois autour d’un anneau de réplication pour faciliter l’ajout de noeuds.
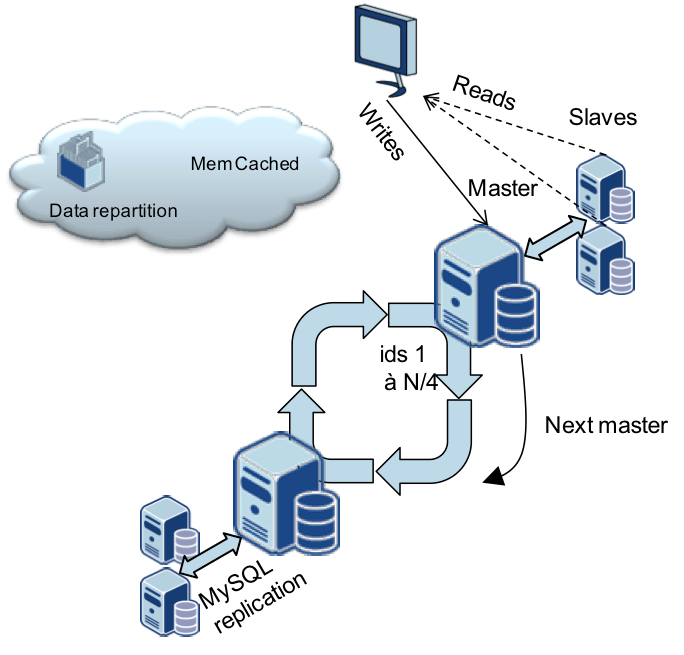
Figure 3
Un identifiant sert de clé de partitionnement (le plus souvent l’identifiant du propriétaire de la photo) qui répartit les données sur les différentes machines. En cas de chute d’un nœud, les écritures sont redirigées vers le nœud suivant sur l’anneau. Chaque instance sur l’anneau est également répliquée sur deux nœuds esclaves qui servent en lecture seule en cas de chute du nœud master associé.
L’architecture de Facebook présente l’intérêt de montrer l’évolution d’une base relationnelle vers un modèle complètement distribué.
Facebook a ainsi débuté en se basant sur MySQL, solution Open Source très efficace. Ils ont ensuite mis en œuvre un ensemble d’extensions permettant de partitionner les données.
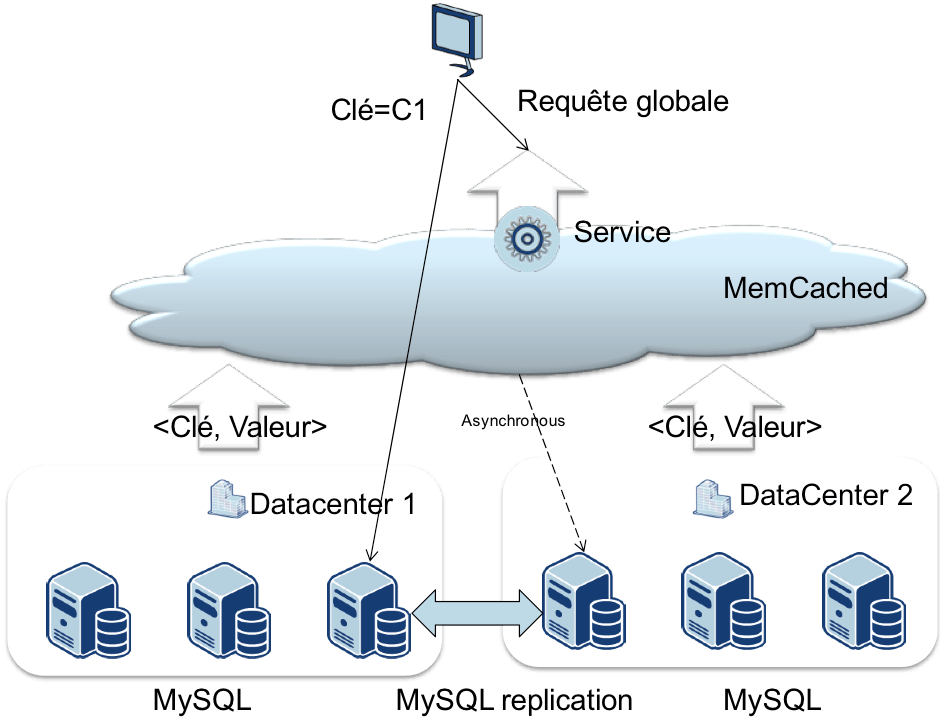
Figure 4
Désormais tout stockage de données de façon centralisée est banni dans l’architecture Facebook. Un accès centralisé est assuré par du cache (Memcached) ou un service spécialisé. L’architecture retenue continue d’utiliser MySQL mais uniquement comme système de stockage. Le système de réplication de MySQL est également utilisé après extension pour répliquer les instances entre plusieurs datacenters. Cependant son utilisation est très éloignée d’une base de données relationnelle. Les données sont accédées uniquement sous forme clé/valeur. Plus aucune jointure n’est réalisée à ce niveau. Enfin la structure des données est prise en compte pour colocaliser les données utilisées simultanément.
L’architecture Amazon se distingue par une gestion plus avancée de la perte d’un ou plusieurs nœuds sur Dynamo.
Amazon a débuté dans les années 1990 avec un seul serveur web et une base de données Oracle. Ils ont ensuite mis en place un ensemble de services métiers en 2001 avec des stockages indépendants. A côté des bases de données, deux systèmes utilisent le sharding : S3 et Dynamo. S3 est un stockage de BLOB sur Internet identifié par une URL. Dynamo (utilisé en interne puis très récemment proposé sur Amazon Web Services) est un système de stockage clé/valeur distribué, réparti, destiné à assurer une très haute disponibilité et des temps de réponse très faibles.
Afin de privilégier la disponibilité sur Dynamo, plusieurs versions d’une même donnée peuvent coexister : on parle de cohérence « à terme » (eventual consistency) [12].
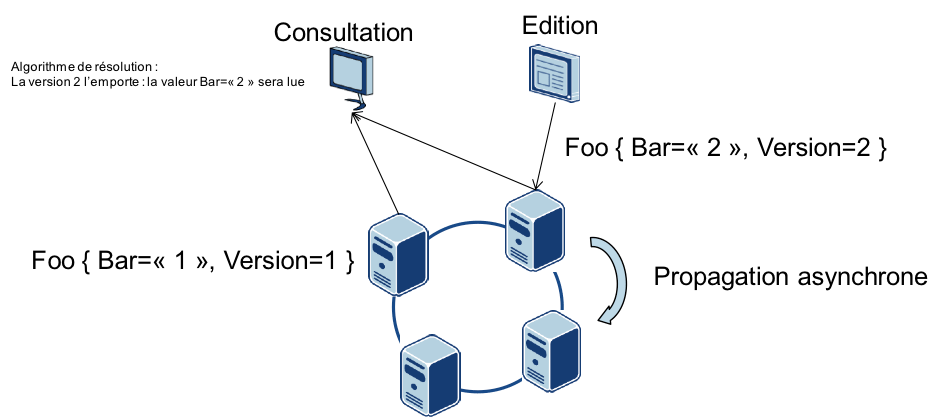
Figure 5
A la lecture, un algorithme comme le vector clock ou en dernier recours l’application cliente devront résoudre le conflit. Le curseur peut être également ajusté entre la réplication pour tolérer la perte d’un nœud et les performances du système.
Le cheminement de LinkedIn présente des similitudes avec Amazon : sortie d’une approche monobase en 2003, un découpage en service et la mise en place d’un système distribué avec des concepts similaires à Dynamo : Voldemort. Contrairement à Dynamo, il est open source. A noter : les index et graphes sociaux ont toujours été stockés de façon séparée chez LinkedIn.
Google a, le premier, publié des informations sur son système de stockage distribué. Celui-ci tire ses gênes non pas des bases de données mais des systèmes de fichiers.
Google évoque dans sa publication [13] sur le Google File System (GFS) les faiblesses précédemment observées et le choix structurant du commodity hardware. Ce système de fichier distribué sert directement, ou indirectement, aux stockages des données chez Google (index, mail).
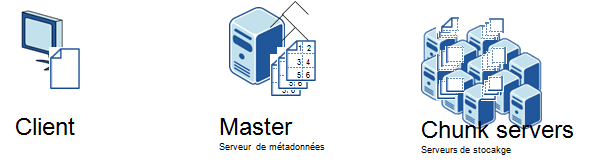
Figure 6
Son architecture repose sur un serveur de métadonnées centralisé (pour orienter l’application cliente) et un très grand nombre de serveurs de stockage. Le degré de consistance des données est inférieur à ce que peut garantir un système de fichiers classique, mais ce point à lui tout seul pourrait faire l’objet d’un article. Google utilise en production des clusters de plusieurs centaines de machines lui permettant ainsi de stocker des petabytes de données à indexer.
Il est cependant indéniable qu’un nombre important de sites restent sur des technologies de base de données relationnelle sans sharding (ou sans communiquer sur le sujet) : Stack Overflow, SalesForce, Voyages-SNCF, Vente privées… La liste est difficilement exhaustive dans un cas comme dans l’autre. Pourtant nous pensons que le sharding est désormais une stratégie classique sur les sites web à grand trafic. En effet, l’architecture de SalesForce est certes basée sur une base de données Oracle, mais elle utilise la base de données de façon très différente des pratiques qui ont cours dans nos SI : tables avec une multitude de colonnes non typées et nommées de façon générique (col1, col2), moteur d’exécution des requêtes en amont de celui d’Oracle pour prendre en compte ces spécificités… Les optimisations montrent les limites d’une pure architecture relationnelle. L’exception la plus marquante vient selon nous de chez StackOverflow, dont l’architecture repose sur une unique base relationnelle SQL Serveur. Ce site a entièrement fait le choix d’une architecture basée sur la scalabilité verticale, leur architecture initialement inspirée de Wikipédia ayant évolué pour mieux se conformer à cette stratégie. Face à cela, il faut noter que le besoin en scalabilité de StackOverflow n’est pas forcément comparable à celui d’autres sites car la communauté ciblée (celle des experts en informatique) est assez limitée, et le modèle favorise la qualité des contributions à leur quantité. Par ailleurs, le choix d’une plateforme sous licence Microsoft, leur offre un outil efficace mais pour lequel les coûts de licences deviendraient probablement prohibitifs en cas de scalabilité horizontale.
La distribution des données est l’une des clés qui a permis aux grands du web d’atteindre leur taille actuelle et de fournir des services qu’aucune autre architecture ne pourrait supporter. Mais qu’on ne s’y trompe pas, ce n’est pas un exercice facile : des problématiques toutes simples dans le monde relationnel (jointures, consistance de la donnée) demandent la maîtrise de nouveaux outils ou de nouvelles méthodes.
Les domaines avec de forts enjeux de volumétrie mais des enjeux de consistance limités – cas des données partitionnables notamment – sont ceux pour lesquels la distribution des données aura le plus de bénéfice. Des offres autour de Hadoop utilisent ses principes et sont pertinentes dans la BI et plus particulièrement dans l’analyse de données non structurées. Côté transactionnel, les problématiques de consistance sont plus importantes. Les contraintes sur les API d’accès sont aussi limitantes mais de nouvelles offres comme SQLFire de VMWare ou NuoDB tentent de mixer sharding et interface SQL. A suivre donc.
En somme, il faut se demander quelles sont les données utilisées dans un même use case (quelle partition est possible ?) et quelles seraient pour chaque donnée les conséquences d’une perte de consistance ? En fonction de ces réponses, vous pourrez identifier vos grands enjeux d’architecture qui vous permettront de choisir, au-delà de la seule problématique de sharding, l’outil qui répondra le mieux à vos besoins. Plus qu’une solution magique, le partitionnement des données doit être abordé comme un outil permettant de franchir des frontières de scalabilité inaccessibles sans son utilisation.
L’utilisation de produits Open Source ou maison, maîtrisés en interne, est inextricablement liée à l’utilisation du partitionnement des données du fait du tuning très fin requis. Le modèle transactionnel ACID est également remis en question par le partitionnement des données. Le pattern Eventually Consistent (consistance finale) propose une autre vision et une autre façon de répondre au besoin des utilisateurs tout en tolérant cette remise en question. Là encore, une maîtrise de ce pattern est très utile pour mettre en œuvre la distribution des données. Enfin et surtout, le sharding est indissociable du choix du commodity hardware fait par les grands du web.
Retrouver toutes les pratiques des Géants du Web sur le site dédié (www.geantsduweb.com) : pdf de l'ouvrage à télécharger, vidéo et compte-rendu de la présentation "Décrypter les secrets des Géants du Web"
Définition
Wikipedia
eBay
Friendster and Flickr
HighScalability
Amazon
[1] Wikipédia décrit ce mot comme une méthode de partitionnement horizontale d’une base de données ou d’un moteur de recherche (http://en.wikipedia.org/wiki/Sharding)
[2] Enjeux que l’ouverture de nos SI sur Internet tire également insidieusement (analyse du comportement des utilisateurs, liens avec les réseaux sociaux…)
[3] La notion de scalabilité est certes liée à la capacité d’un système à absorber une charge plus importante mais ce qui est important dans la scalabilité est la dimension coût. Formulé autrement, un système est scalable s’il est capable d’absorber la requête supplémentaire (avec un temps de réponse identique) et si cette requête supplémentaire coûte le même prix que les précédentes (autrement dit que les coûts d’infrastructure sous-jacent ne font pas exploser la facture)
[4] Au-delà de la scalabilité, la notion d’élasticité est liée à la capacité à n’avoir que des coûts variables sans lien avec la charge. Autrement dit, un système est élastique si quelque soit le trafic (10 requêtes par seconde ou 1 000 requêtes par seconde), le coût unitaire par requête est identique.
[5] Par exemple l’absence de taille maximale sur les boîtes mail
[6] Cette étude http://www.morganclaypool.com/doi/pdf/10.2200/S00193ED1V01Y200905CAC006 est également résumée dans cet article de blog d’Olivier Malassi https://blog.octo.com/datacenter-as-a-computer-une-plongee-dans-les-datacenters-des-acteurs-du-cloud/
[7] C’est ainsi que nous traduirons « commodity hardware » car il ne s’agit pas forcément de machines d’entrée de gamme mais de machines dont le rapport performance/prix est le plus élevé dans le système en question
[8] (364/365)100=76%=277/365 soit 88 jours
[9] Ainsi, si lorsqu’un nœud tombe, les autres nœuds ignorent les modifications faites sur ce nœud puis réconcilient les différentes modifications lorsque ce nœud est reconnecté au cluster, on a diminué le harvest – la réponse n’est pas complète car elle n’intègre pas les dernières modifications – mais préserve le yield. Les solutions NoSQL développées par ces acteurs intègrent différents mécanismes pour gérer cela : réplication des données sur plusieurs nœuds, algorithme vector clock[9] pour réconcilier des mises à jour concurrentes lorsqu’un nœud est reconnecté au cluster. Plus de détail dans cet article http://radlab.cs.berkeley.edu/people/fox/static/pubs/pdf/c18.pdf
[10] Plus de détails sur cet incident de la part de FourSquare http://blog.foursquare.com/2010/10/05/so-that-was-a-bummer/ et l’analyse d’un autre blog http://highscalability.com/blog/2010/10/15/troubles-with-sharding-what-can-we-learn-from-the-foursquare.html
[11] Plus de détail dans cet article https://blog.octo.com/consistent-hashing-ou-l%E2%80%99art-de-distribuer-les-donnees/
[12] Il existe des mécanismes de Quorum (http://en.wikipedia.org/wiki/Quorum_(distributed_computing) pour trouver des compromis entre cohérence, tolérance à la panne, disponibilité...