Tired of using EC2 instance, creating your infrastructure, instantiating as many node as possible to handle the amount of data? Good news! it is now possible to get rid of these servers and focus only on the code. Pretty nice, isn’t it? To illustrate this topic, this article is dedicated to a real-time “serverless” platform.
Let’s dive into it!
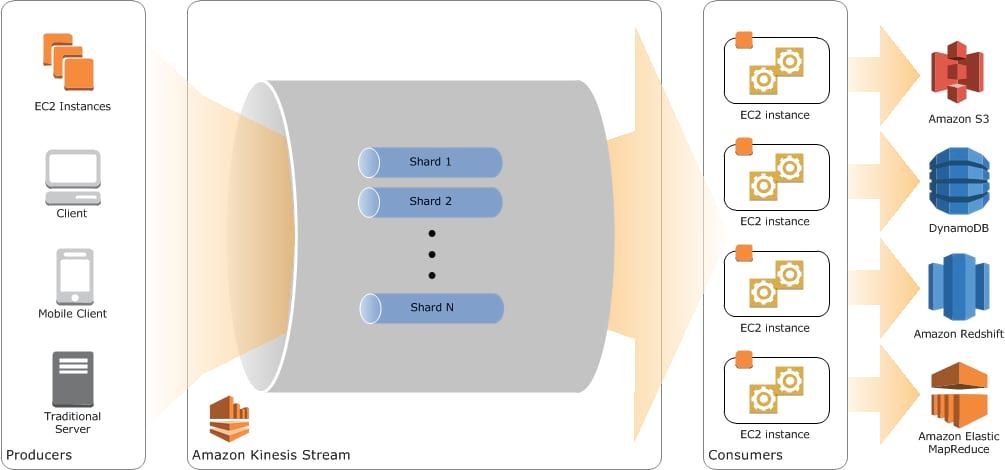
Amazon Kinesis Stream is a platform devoted to collect and process records in real-time. If you are familiar with Kafka, it refers to the same concept, the only difference lies in the terms you use. You can consider Kinesis as a messages queue for high message throughput. The core feature of Kinesis is its streams. Streams can be considered as the equivalent of topics in Kafka. Each stream is separated into shards which are a “uniquely identified group of data records in a stream” (one feature is the simulation/indication of how many tuples you can handle by modifying the number of shards)
There are different kinds of “Kinesis” :
The one we are interested in is Kinesis Stream because we want to manipulate the platform features at a deeper level.
For those who know how distributed messages queue works, the core feature is the high volume of messages handled by the platform. Kinesis is supposed to be able to handle 1MB/sec data input and 2MB/sec data output by shard.
What does it mean?
Regarding real-time Big-Data platform, you usually have to deal with millions to billions messages per second. The first question arising is: Is Kinesis able to handle this amount of data?Let’s admit the average record size is 65Kb and the maximum records written per second is about 1,000,000.
With this amount of data AWS recommend to instantiate 97,500 shards knowing that the service is limited to 50 (unless you contact them). 97,500 shards or threads seem really high even if the platform is able to handle this amount. If you are interacting directly with a consumer or/and a producer on an EC2 server, you would have to size your server with enough resources to deal with this amount of threads. In other words, if you want to handle large amount of events, it seems compromised.
However, if you have the necessity to change the number of shards after creating a Kinesis instance, you can do so without re-creating the stream. Yet, it would be great if the resizing was done automatically.
As a distributed message queue, you need a consumer and a producer to interact with Kinesis. The producer purpose is to inject inside the streams records (of any type) and the consumer purpose is to retrieve records from the streams.
There is no intelligence behind it. It works as a queue and allows to handle high volume in records without failure and with high availability guarantee. Indeed, Kinesis does not lose records, it replicates over its nodes the data it needs to keep. Everything is done automatically, we do not have access to the infrastructure and even less to the replication factor.
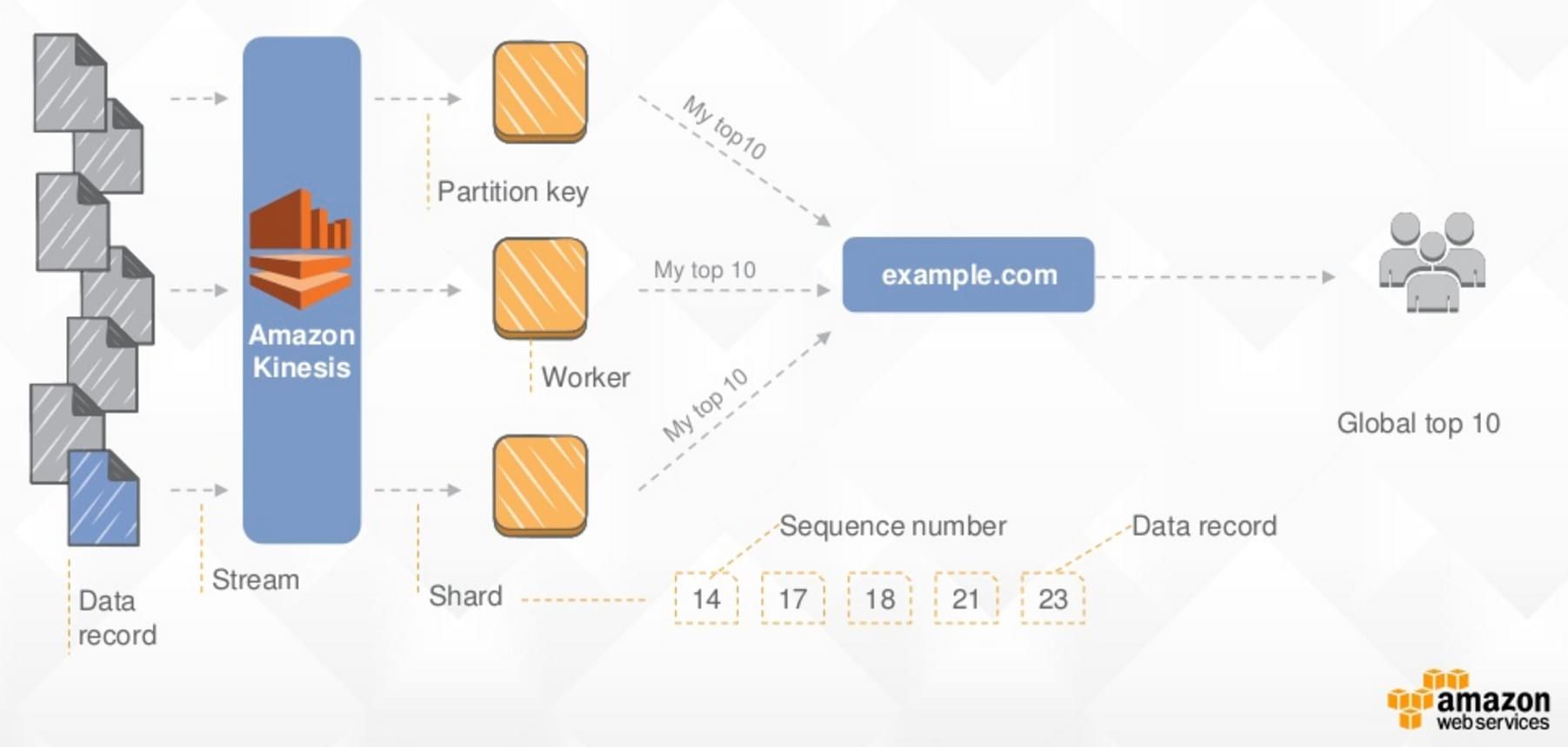
Advantages: Easy to manipulate, enables fault-tolerant consumption, simple data analysis and reporting in real time. Drawbacks: Still important issues need to be fixed: record skipped while being consumed, records belonging to the same shard processed by the same consumer at the same time, consumer applications not reading the latest data from the stream.
When you create your stream for the first time, there are a few things to know:
Described below the interface to create your first stream:
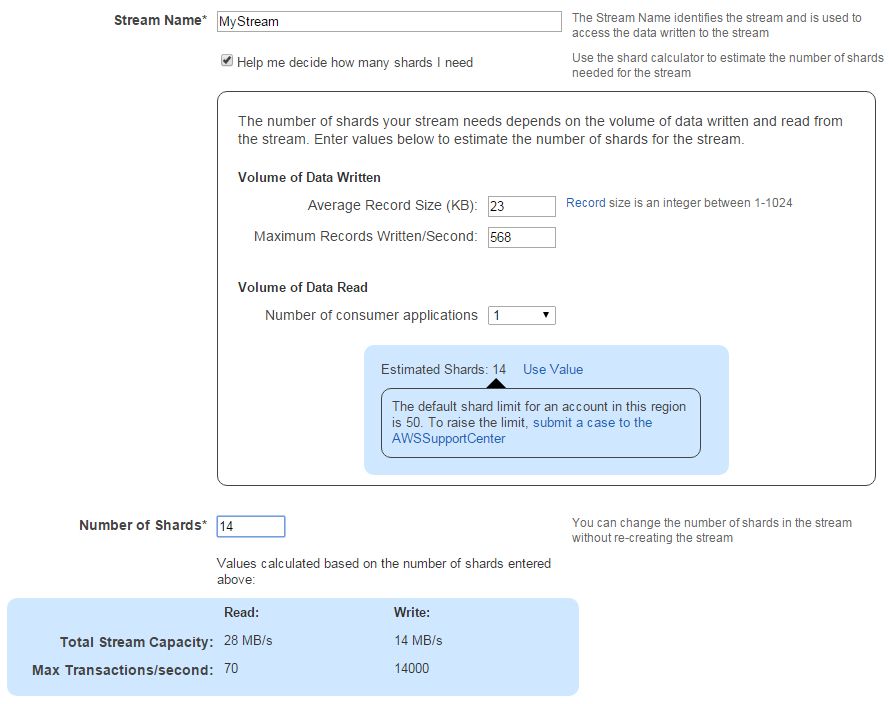
Once you click the create button, you get a Kinesis Stream up and running.
When the words “message queue” and “real-time” occur, usually, what comes next is the real-time framework combined with the data flow.
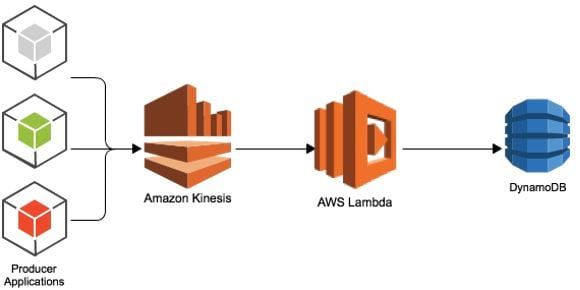
Kinesis can be used by real-time frameworks such as Storm or Spark Streaming. However our goal here is to create a full AWS real-time stack. And this can be done by “AWS Lambda”.
Lambda is a compute service where you can upload a “Lambda function”. A Lambda function needs to be implemented in order to be executed as any regular code (Java, Python, NodeJS) reacting to an AWS Events. By doing so, you will not have to worry about any infrastructure or managing the servers, and you will pay just regarding the amount of CPUs used. In other words, you can forget about EC2 and just deal with your code.
Here is an example of Lambda Function:

In our case, what matters here is the ability to connect easily Kinesis to a Lambda function. Lambda can behave as an event-driven compute service, such as new data getting into Kinesis. Therefore, a Lambda function can act as a consumer.
The perks of using a Lambda are the high availability, provisioning and automatic scaling. However, when you consume data from Kinesis and the connection is severed, you may encounter data loss. A fault-tolerant mechanism needs to be design to prevent any risks.
Advantages: Useful to just handle the code without worrying about the infrastructures, services easy to handle, offer multiple languages (Java, Python, NodeJS).
Drawbacks: Lack of flexibility when performing multi-threading applications (no access to workers-JVM), limited in terms of resources allocation, 5 minutes timeout...
To implement a lambda, you need to implement a function call a "handler" and attach a role to it (so it can interact with DynamoDB and Kinesis for instance).
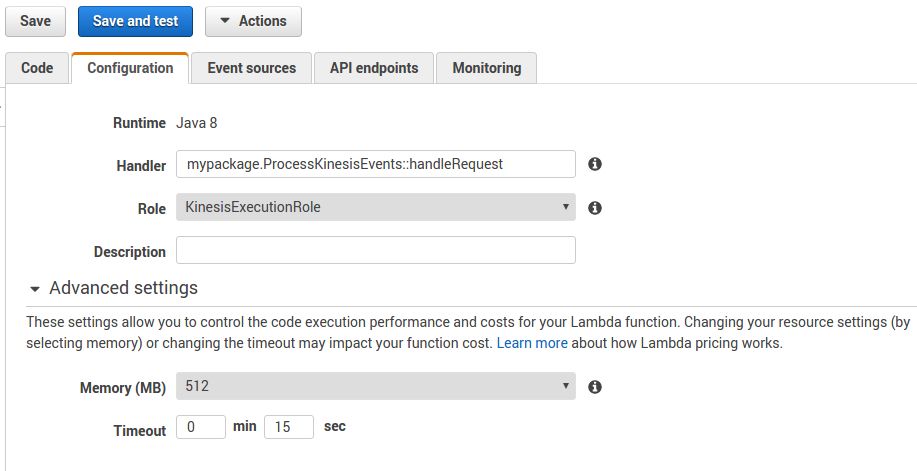
One way to code your own function is to use a regular IDE with the appropriate SDK. Once your code is ready, you just have to package it and upload it on the Lambda service.
FYI: if your package weighs over 10Mb you will have to use S3 to launch you code.
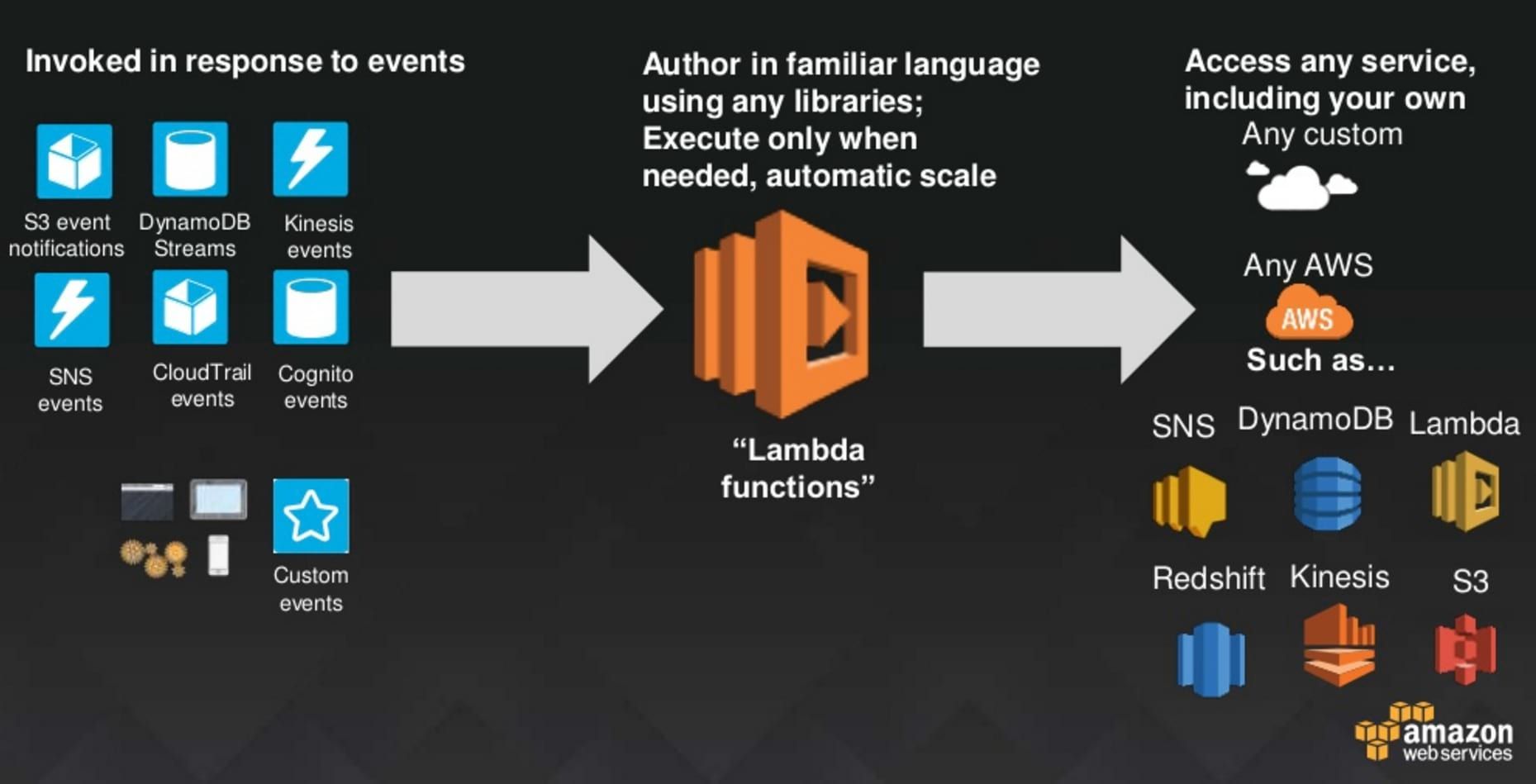
When the code is uploaded, the link between Kinesis has to be set. An easy way to do it is to select as source the type of resources you want. In our case, it would be "Kinesis" and it will automatically detect your stream (mind that your resources need to be in the same region).
A major aspect of coding is testing, you should obviously not deploy a code in production without testing it. Indeed, with lambda you can easily test your code by using the "test" interface. However, it is limited if you want to test several Lambda in parallel and AWS does not provide tools to automate the deployment and test everything in an automated way.
One answer could be to use common tools, for instance if your code is written in Java, such as JUnit, Cucumber or FitNesse. Then, package everything as a “normal” application and perform your tests in local before deploying the code on AWS.
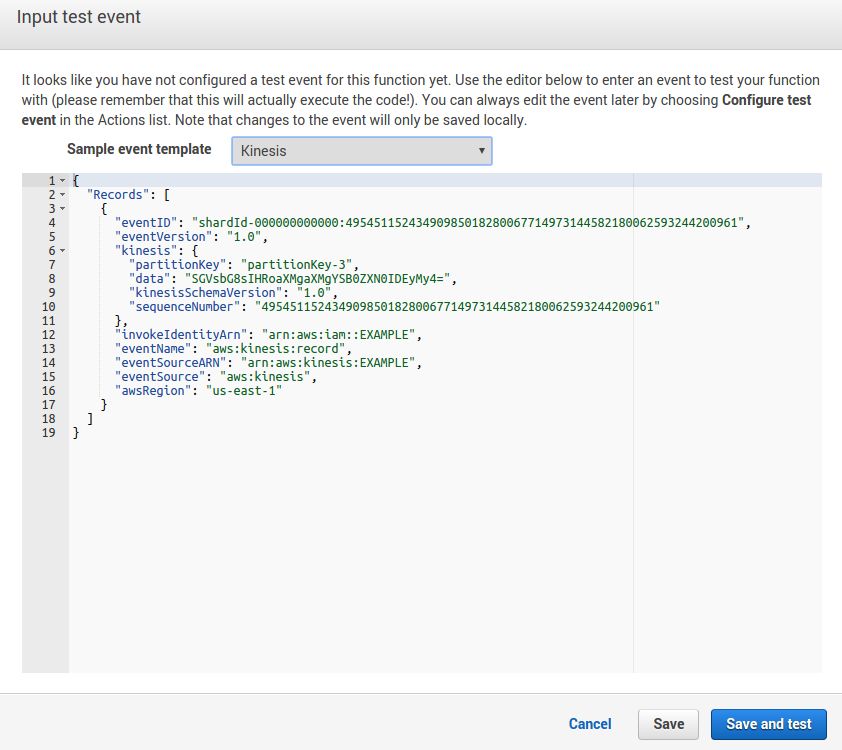
In this state the lambda function is always listening to Kinesis, you can let your resources launched because you will only pay for the amount of resources used. Which is pretty nice.
You can now conceive that the major perks of using Kinesis + Lambda are definitely better in terms of cost compared to EC2 instances with Kafka + Storm/Spark cluster or with Kinesis as well.
Described below how you can use Kinesis with EC2 instances:
Last missing part of our design is the storage system because as every real-time processing architecture, the data need to be stored somewhere and this is achieved through Amazon NoSQL database: DynamoDB.
Be aware that good documentation about DynamoDB is hard to find. You will find piece of codes here and there to create your own application. However once you are familiar with AWS it is not that difficult (in AWS: credentials are the key, once everything is well configured coding skills are all that matters).
By instantiating the right object in our lambda, creating the right table in DynamoDB and making all the right links, the only thing left to do is to run a producer which will inject the records into Kinesis. Then our lambda function will consume the data to let them end up in Dynamodb.
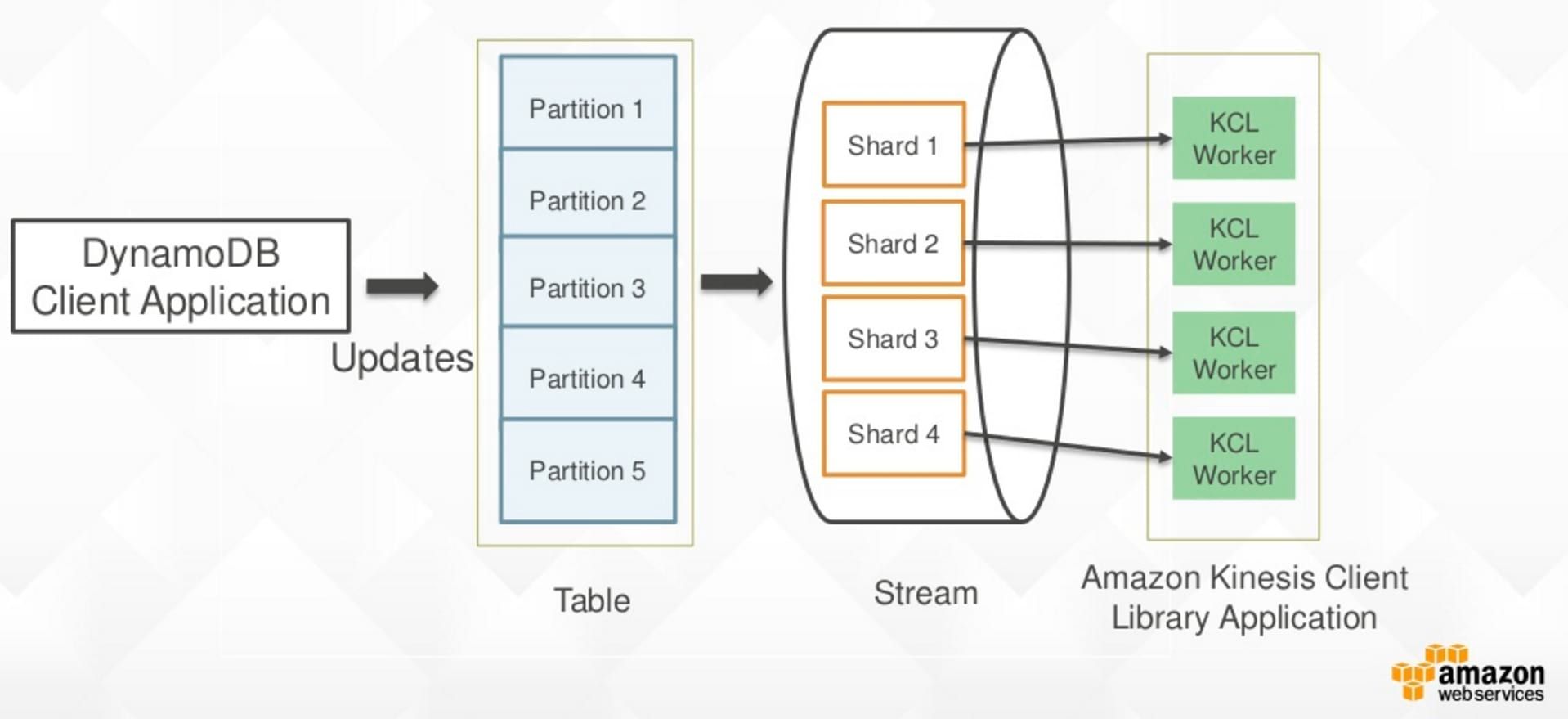
As every NoSql database DynamoDB enables to store large amount of data. However, one cool feature is DynamoDB Stream. DynamoDB Stream enables to get every event generated by DynamoDB (insert, delete, type of events etc...). All necessary monitoring informations can be found in CloudWatch. Indeed, DynamoDB is directly plugged to this cloud monitoring services but if you want to go further and perform your own analysis Dynamo Stream allows to extract all necessary informations. DynamoDB Stream is based on Kinesis, as a layer on top of DynamoDB with the same API, so it is easy to adapt your code from a Kinesis app to a DynamoDB Stream one.
We now have Kinesis + Lambda + Dynamodb able to handle a high volume of records at a minimum cost in the cloud.
We tested as well if Lambda could store directly to S3. The answer is yes: the same principle applies as for DynamoDB except that instead of inserting into Dynamo, an S3 bucket is used.
Advantages: Triggered associated with DynamoDB
Drawbacks: Lack of documentation
As a result, it is seducing to be able to easily create a real-time platform without worrying about infrastructure, provisioning, automatic scaling, high availability or OS maintenance. Nevertheless, real-time platform does not mean Big Data real-time platform. If you want to digest millions of messages per second you will probably encounter latency issues, bottlenecks, etc…
Nonetheless, It would be interesting to see how the architecture would react by analysing each components:
At this stage of maturity, it would be not wise to consider this stack as a Big Data platform. The risks of too many errors occurring would be too high and the design would have to be twisted.
Yet, this is the main issue here. How do we store data that need to be aggregated? There is no magic answer :
The way to automate provisioning and configuration at scale is to use CloudFormation which is a configuration management tool such as Puppet, Chef or Ansible. It is difficult to handle but once everything is configured, it makes things easy. It allows to create, modify or update an existing stack on AWS.
Described below key templates to instantiate our components with CloudFormation:
AWS Kinesis Stream :

AWS Lambda :

AWS DynamoDB:

Once your Cloud Formation template is done, you will be able to deploy a full stack without manually set parameters or interactions between components. It makes things easy to create automatically services and end up with a full real-time architecture up and running on AWS.
All of these questions will have to find answers. But for the moment, The AWS stack Kinesis, Lambda and DynamoDB is a good start to make real-time distributed system easier to start with.