Exposer votre métier via des API, que ce soit pour le reste de votre entreprise ou pour le monde entier, est une belle idée. Vous avez passé du temps à en concevoir le design pour les rendre facile d’utilisation par les développeurs, et vous avez repensé l'architecture de votre SI pour leur offrir la place qu'elles méritent… Et vous vous heurtez à la crainte de vos collègues et de vos supérieurs : “Mais si j’expose mes applications sur le web, mes données ne seront pas en sécurité !”.
Gardez à l’esprit que le but d’une stratégie API, c’est de permettre à des développeurs de consommer vos ressources, pour aider vos utilisateurs. Il est donc crucial, non seulement d’authentifier et d’autoriser vos utilisateurs, mais aussi d’authentifier et d’autoriser les applications qui consomment votre API.
Cet article a pour but d’expliquer comment exposer, sans danger, votre API sur le web… et par conséquent à votre entreprise ! Sans oublier les deux objectifs d’une stratégie de sécurisation d’application : mener la vie dure aux attaquants potentiels, tout en facilitant la vie des consommateurs légitimes. Deux objectifs entre lesquels il faudra trouver un équilibre.
Toutes les ressources exposées par votre API ne nécessitent pas le même niveau de vigilance. On distingue deux types de ressources.
Comme leur nom l’indique, les informations contenues dans ces ressources sont publiques. Par exemple, /products ou /offers sont des ressources qui sont probablement faciles à consulter sur votre site Internet, sans aucune connexion préalable de l’utilisateur.
Même si les données exposées sont publiques, nous recommandons de mettre en place une stratégie d'API_KEY. Cela vous permettra de gérer les quotas d'utilisation de vos ressources et donc d'éviter des abus.
Il s'agit de ressources auxquelles tout le monde ne doit pas avoir accès, en général des informations qui sont propres à un utilisateur : un historique de commandes, des informations bancaires, des données personnelles, etc. De telles informations ne doivent être accessibles que par leur propriétaire.
Le cas particulier d'une API, c'est qu'elle est potentiellement consommée par plusieurs clients différents, certains internes à votre entreprise, d'autres qui lui sont étrangers. Et le propriétaire d'une ressource privée peut vouloir accéder à cette ressource via plusieurs clients d'API différents !
Prenons un exemple : vous voulez accéder à votre compte en banque avec le site de votre banque, et aussi à travers une application d'agrégation bancaire. Les informations de votre compte en banque sont privées, donc l'API de votre banque ne doit pas les exposer de façon publique pour que n'importe quelle application puisse les lire. Elle autorise probablement son propre site à y accéder facilement ; mais l'agrégateur bancaire est géré par une entreprise indépendante, la banque ne lui donne donc pas accès à toutes ses ressources.
Pour pouvoir utiliser cet agrégateur, il vous faut donc un moyen d'informer l'API de votre banque que vous autorisez l'agrégateur bancaire à accéder à votre compte en banque en votre nom. Et ce, de manière suffisamment sécurisée pour que l'API soit certaine de vous avoir identifié.
C'est ce problème que nous allons aborder, ainsi que les protocoles et frameworks qui permettent de le résoudre. Mais d'abord, encore quelques définitions.
Ces 3 piliers se résument en anglais par le triple A : Authentication, Authorization, Accountability. Dans la langue de Molière, nous les traduisons par Authentification, Autorisation, et Traçabilité.
Les deux concepts d’authentification et d’autorisation sont trop souvent confondus, et malheureusement le langage du Web n’aide pas à faire la distinction. On pourra citer la spécification OAuth qui utilise l’abréviation anglaise “auth”, ou encore l’en-tête HTTP “Authorization” qui se charge en réalité d’authentification.
L’authentification, c’est savoir qui appelle notre API. À partir d’un ensemble d’informations, il est possible de savoir de qui vient l’appel HTTP. L’exemple le plus simple (et probablement le moins sûr) est le suivant :
GET /v1/some-resource Host: some.api Accept: application/json I-Am: Renaud Dahl
Dans cet exemple, l’ensemble d’informations utilisé pour identifier l’utilisateur appelant est… son nom en clair. Cette information n'est bien entendu pas fiable et ne peut être utilisée en l'état ! Nous verrons plus loin comment résoudre ce problème.
Une fois que la personne qui appelle votre API a été identifiée, l’autorisation consiste à savoir ce que cette personne a le droit de faire. Dans la mesure où chaque appel HTTP est traité indépendamment (une API REST est stateless), à chaque fois que vous recevrez un appel, il vous faudra décider si oui ou non l’appelant a le droit de consommer cette ressource en particulier.
Il n’est pas prudent de récupérer ce genre d’information depuis l’appel HTTP en lui-même. Voyez plutôt :
GET /v1/some-resource Host: some.api Accept: application/json I-Am: Renaud Dahl I-Can: do pretty much anything
Ce serait assez ridicule. Par conséquent, savoir ce que l’auteur d’une requête est autorisé à faire est une information qui DOIT être contrôlée et validée par votre propre système.
Il s’agit de savoir qui a fait quoi, quand, avec quelles ressources. Il peut s’agir simplement d’un fichier de logs, mais attention ! Dans le cas d’une API, le “qui” est assez vague et représente finalement plusieurs personnes. Pour suivre précisément ce qui se passe dans votre système, il vous faut noter pour chaque appel HTTP :
Une telle “comptabilité” pourra vous aider plus tard pour de la révocation d’accès, si vous découvrez qu’un des éléments ci-dessus a été compromis. Cela peut aussi vous permettre de noter le type d’appareil d’où vient la requête, ainsi que sa région, grâce à des méthodes simples de localisation.
À partir des définitions que nous avons données jusque là, on peut déduire que pour une ressource privée, il vous faudra gérer l’Authentification et l’Autorisation. Enfin, la Traçabilité sera nécessaire pour toutes les ressources.
Maintenant, nous sommes tous d’accord sur quelles ressources protéger, et sur les 3 piliers qui se cachent derrière ce mot “protéger”. Passons au “comment” : quels sont les différents rôles impliqués ? Quels sont les protocoles à utiliser ?
Résumons qui sont les parties prenantes :
Vous l’aurez remarqué, les deux rôles identity provider et resource provider sont souvent un seul et même acteur. Ce n’est pas complètement illogique : une identité peut très bien être une ressource comme une autre ! Mais ce mélange des genres peut avoir des effets secondaires problématiques :
Pour des ressources publiques, pas question d’authentification ou d’autorisation… Mais vous voulez quand même sûrement gérer des accès ! Pour mettre en place une tarification à base de quotas par exemple, ou simplement éviter des abus. Pour ce genre de cas, une stratégie d’API Key convient parfaitement.
Une telle clé est facile à récupérer par un développeur d’application :
GET /v1/some-resource Host: some.api Accept: application/json X-API-KEY: MyAwes0m3API_KeY
Mais cette façon de faire a bien sûr des inconvénients :
Pour gérer l’authentification et l’autorisation, nous avons donc besoin d’autres protocoles.
Les standards de l’industrie pour l’authentification et l’autorisation sont OAuth2 et OpenID Connect : OAuth2 est dédié à la délégation de droits (“moi, utilisateur, autorise cette application à lire mes mails en mon nom”) et OIDC, à la gestion d’identités.
Ces deux protocoles couvrent à eux deux 99,9% des cas possibles. Nous vous DÉCONSEILLONS FORTEMENT d’essayer d’utiliser d’autres protocoles ou d’essayer de réinventer la roue, ce serait un frein inutile ajouté à vos clients que sont les développeurs d’applications.
Vous pouvez vous contenter d’utiliser OAuth2 si vous êtes à la fois resource provider et identity provider (et rappelez-vous que vous l’êtes sûrement). OpenID Connect est une extension du protocole OAuth2 et vous permettra donc une migration sans douleur si vous décidez d’utiliser un identity provider externe (connexion avec Facebook, Linkedin, Google, etc).
Un certain nombre d’outils ne sont pas efficaces ou pas utiles dans la sécurité de votre API :
Enfin, il est toujours utile de le rappeler : toutes les communications réseau doivent passer par HTTPS pour éviter des attaques de type “man-in-the-middle”.
Nous avons beaucoup parlé d’OAuth2. Il est temps d’entrer dans le vif du sujet et de découvrir en quoi il consiste ! Vous êtes prêts ? C’est parti !
Le framework OAuth2 est conçu pour autoriser des applications, écrites par des développeurs, à consommer les ressources d’un resource provider au nom d’un utilisateur. On parle de délégation, via le consentement de l’utilisateur.
Ce framework a un vocabulaire spécifique :
Petit schéma pour récapituler tout ça :
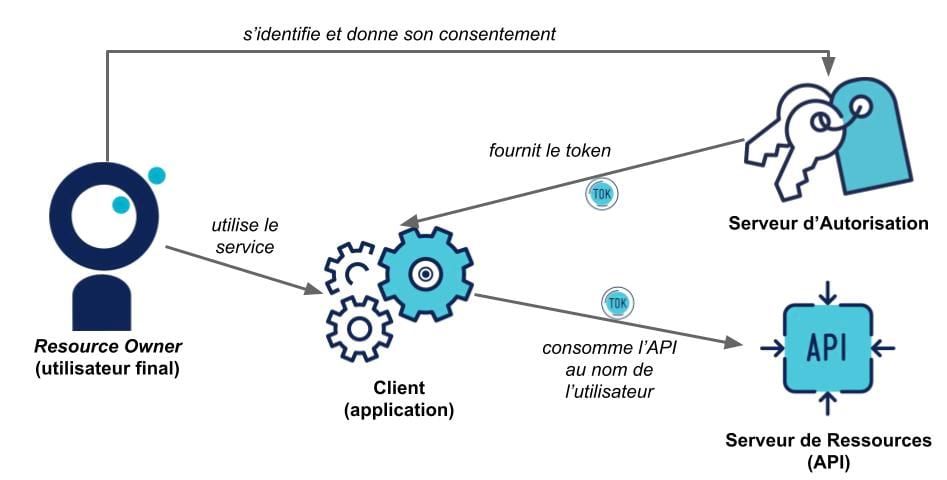
En plus de ce vocabulaire, OAuth2 définit différents types de clients.
Petit rappel : les clients dont nous parlons sont des applications écrites par des développeurs, qui veulent consommer votre API. Ces clients peuvent être confidentiels, externes, ou publics.
La distinction entre ces 3 types de clients dépend de
Il s’agit de clients qui sont développés, déployés, et exploités par la même organisation que celle qui gère les ressources et le Serveur d’Autorisation. Par exemple, des applications de votre entreprise qui ont besoin d’accéder à des données gérées par une autre application.
Pour un client confidentiel, le Serveur d’Autorisation a confiance dans les points suivants :
client_id et un client_secret)Ces hypothèses sont basées sur le fait que le serveur d’autorisation a une certaine connaissance de l’implémentation et du processus de livraison du client. Dans certains cas, vous pouvez considérer que l’application mobile de votre entreprise est un client confidentiel de confiance. Puisqu’elle est développée et publiée sous le nom de la même organisation, les utilisateurs peuvent donner leurs identifiants en toute confiance. Vous n’avez pas de scrupules à renseigner votre mot de passe Facebook... dans l’application mobile Facebook, si ?
Les clients externes sont les clients de base des anciennes spécifications OAuth0 et OAuth1. L’exemple canonique est un site internet hébergé sur un serveur différent (de celui qui héberge votre API) et développé par des développeurs externes.
Pour un client externe, le Serveur d’Autorisation :
Pour ces raisons, dans nos scénarios d’interaction, nous n’exposerons pas les identifiants de l’utilisateur à ce type de client. Par contre, nous leur autoriserons quelques raccourcis pour récupérer un nouveau token si, dans le passé, ils en ont déjà obtenu un pour leur utilisateur (par exemple avec des mécanismes de refresh token).
Comme leur nom l’indique, les clients publics sont ceux auxquels nous ferons le moins confiance. Dans cette catégorie, nous regroupons tous les clients qui ne peuvent pas garantir la sécurité de leurs identifiants (client_id et client_secret), typiquement des applications mobiles ou des SPA (single-page applications) dont le code source peut être récupéré.
Pour un client public, le Serveur d’Autorisation :
Pour ces raisons, nous utiliserons des techniques pour valider “implicitement” l’identité de l’utilisateur final à travers ce type de client (tous les détails viendront plus loin dans l’article, ne vous en faites pas !) De plus, les tokens attribués à ce type de client auront une durée de vie courte, et ne seront pas automatiquement renouvelables.
Il faut donc plusieurs scénarios d’interaction entre l’API, le Serveur d’Autorisation, et le client, afin de pouvoir interagir avec tous les types de clients que nous venons de décrire ! OAuth2 en propose 4 pour couvrir tous nos besoins.
OAuth2 propose 4 scénarios, ou “flows” dans la langue de Shakespeare (et souvent utilisé par les développeurs français aussi). Open ID Connect propose les mêmes (puisqu’il est une extension d’OAuth2, vous suivez toujours ?)
Commençons par le scénario le plus “simple”. Contrairement aux autres, il ne permet pas à un client d’effectuer des actions au nom d’un utilisateur : il ne fait que fournir un token à un Client pour l’identifier auprès d’un serveur de ressources.
Ce scénario est très utile pour des cas où vous avez besoin d’un “utilisateur technique” pour des traitements serveur à serveur (batch ou d’autres actions d’administration). Il permet aussi à des applications de mettre à jour leurs propres informations (nom de l’application, pays, conditions d’utilisation…)
Puisque le client va devoir être authentifié, il devra savoir conserver ses identifiants en sécurité : ce scénario ne doit donc être utilisé que pour des clients confidentiels ou externes.
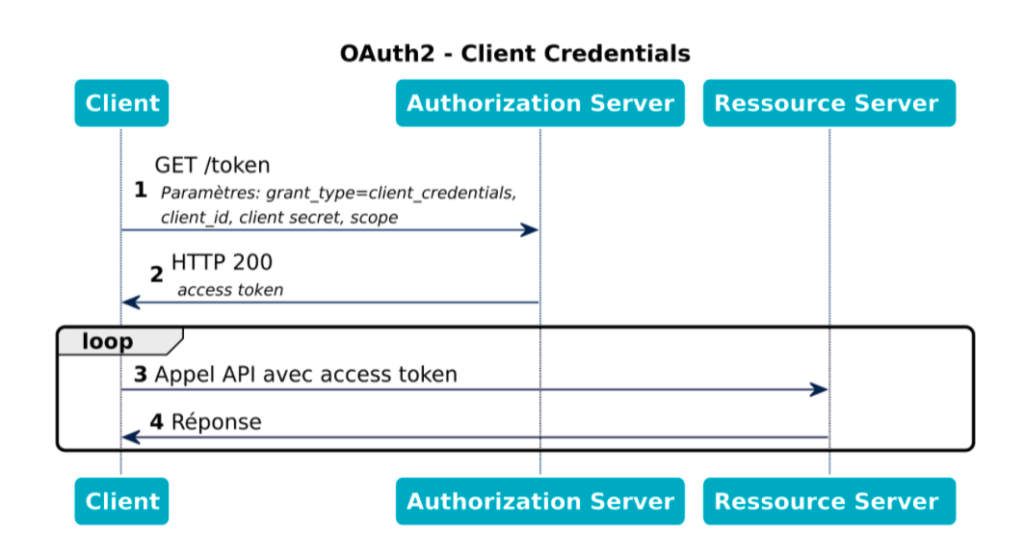
Dans cette séquence vous pouvez noter que :
client_id et son client_secret comme identifiants (credentials, d’où le nom du scénario)Dans ce scénario, le Client reçoit un token directement depuis le serveur d’autorisation sur un endpoint /token. Pour identifier le Resource Owner, le client a la responsabilité de récupérer les identifiants de l’utilisateur. Ces informations étant des données sensibles, ce scénario est seulement acceptable dans le cas d’un client confidentiel.
Il est particulièrement utile pour des applications legacy qui fonctionnaient auparavant en récupérant directement les identifiants de l’utilisateur. Il peut servir de substitution (pas de changement du point de vue de l’expérience utilisateur), l’avantage principal étant que l’application legacy n’a plus besoin de stocker les identifiants utilisateur car elle va se contenter du token d’accès.
Puisque ce scénario n’est acceptable que pour des clients confidentiels, le Serveur d’Autorisation DOIT toujours contrôler les identifiants du client (client_id et client_secret) en plus des identifiants de l’utilisateur.
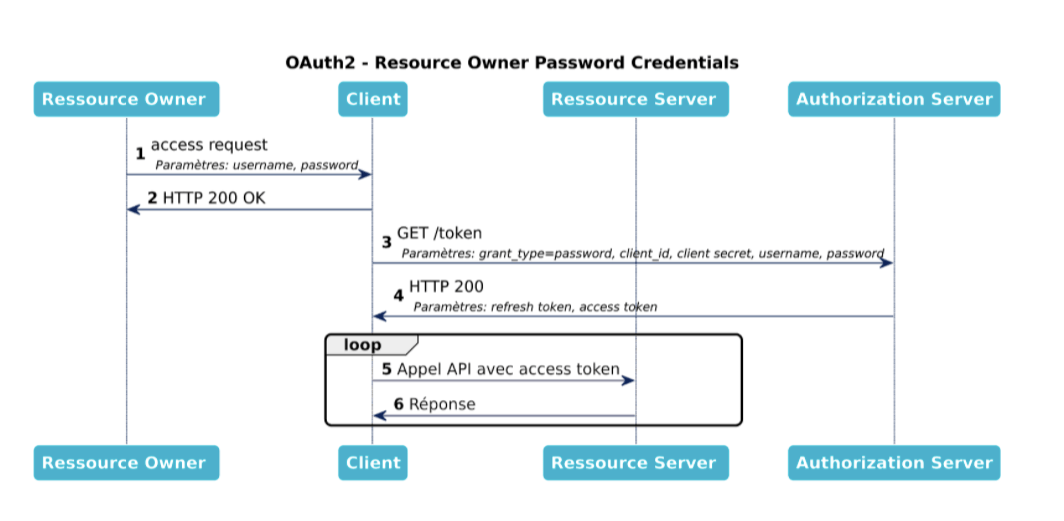
À retenir de ce diagramme :
Ce flow est conçu pour des clients publics. Dans le scénario “implicite”, il n’y a pas de code d’autorisation intermédiaire envoyé au client. Le token d’accès lui est envoyé directement via une URL de confiance connue par le Serveur d’Autorisation (redirect url).
Cette URL doit n’être accessible qu’avec HTTPS et inclure un programme Javascript capable de lire le token à partir du fragment de l’URL correspondante. À partir de là, le token peut être utilisé par cette application Javascript.
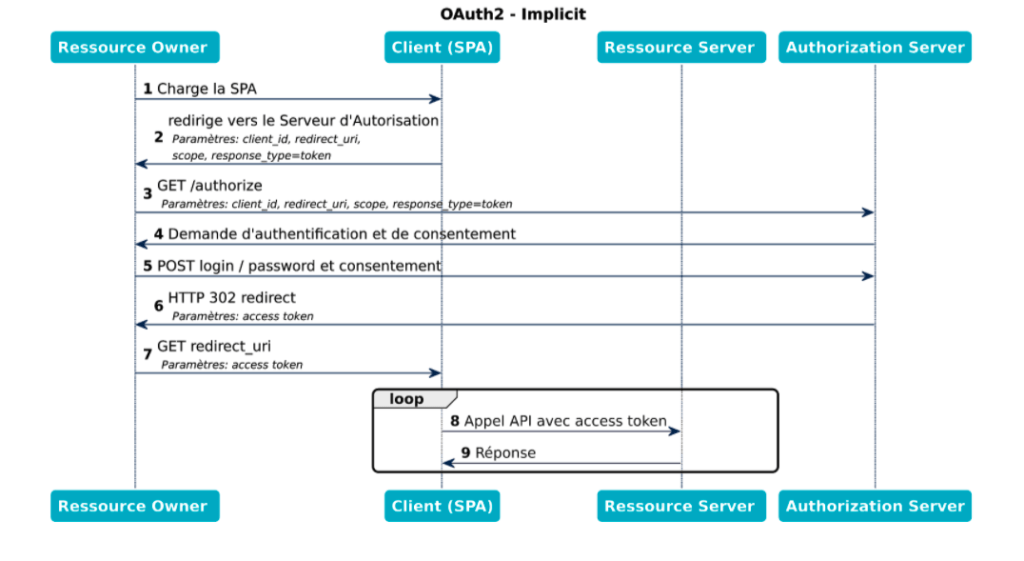
Vous pouvez constater dans cette séquence que :
Le scénario “Authorization Code Grant” est le scénario “traditionnel”, hérité d’OAuth1 et simplifié. Il est conçu pour gérer la communication de serveur à serveur, pour un service web (c’est-à-dire dans le cas où l’utilisateur final utilise un navigateur web). Il convient aux clients confidentiels et externes, et il s’agit d’un cas où le client (au sens OAuth2 du terme c’est-à-dire l’application consommant votre API) est un serveur. Il y a donc trois serveurs en présence, le Serveur d’Autorisation, le Serveur de Ressources et le Client : on appelle donc souvent ce scénario un three-legged flow.
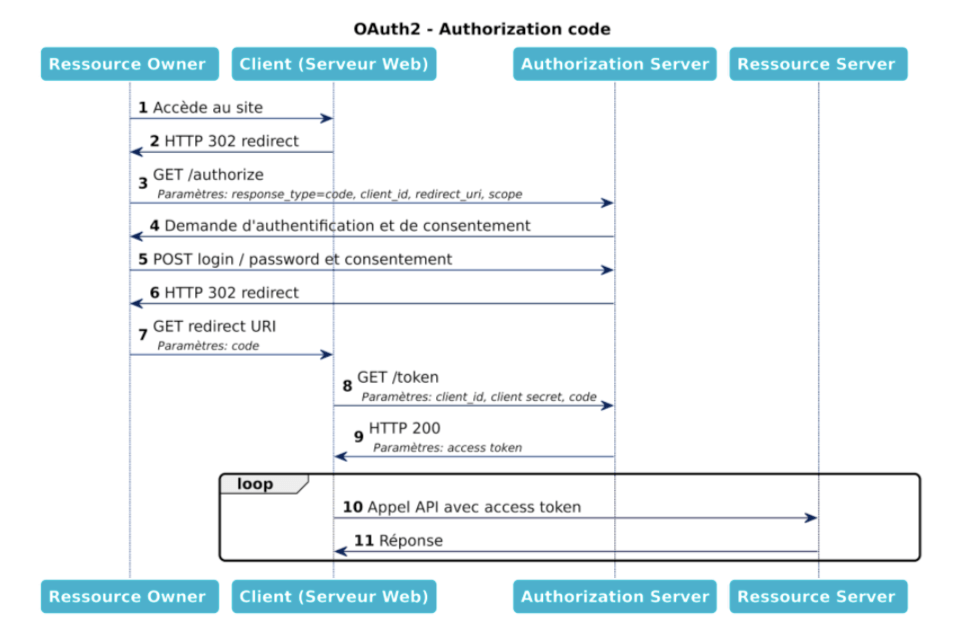
Vous pouvez voir dans ce schéma que :
À noter que ce scénario existe avec une variante destinée aux clients mobiles : la variante Authorization code + PKCE. Son but est d’éviter une interception du token d’accès par une autre application mobile malicieuse : pour cela il ajoute une étape d’échange et de vérification de secrets entre le client et le Serveur d’Autorisation.
Un petit récapitulatif ne fait pas de mal ! Petit rappel des principaux termes utilisés :
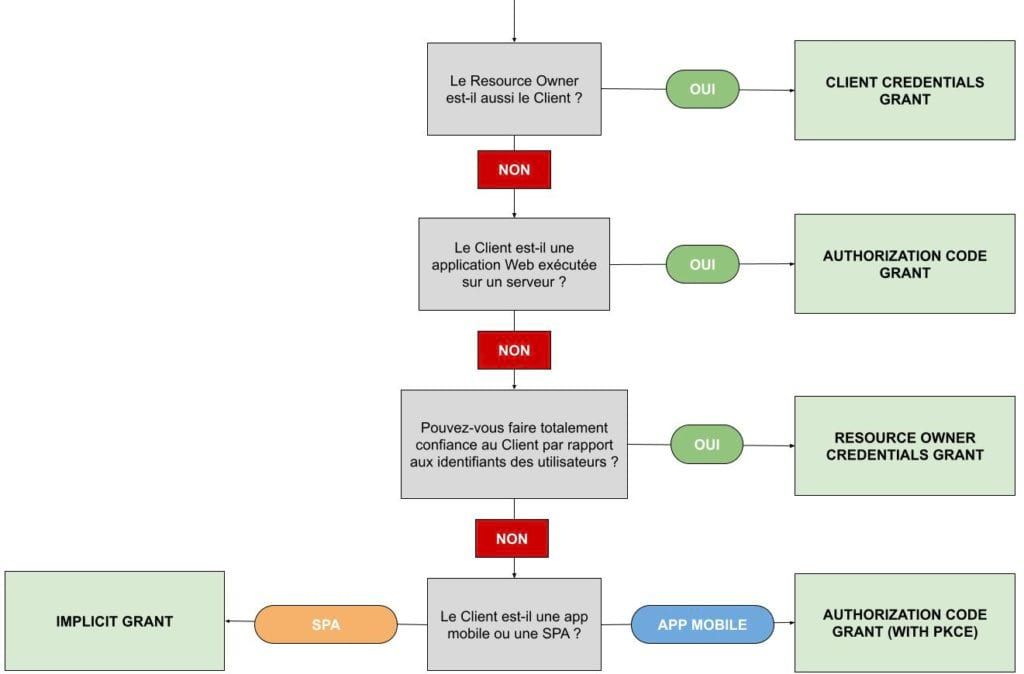
Voilà les questions à se poser pour choisir un flow (source : https://auth0.com/docs/api-auth/which-oauth-flow-to-use )
_ 
_
La version encore plus résumée : chaque scénario correspond à une architecture Web ! Donc pour choisir lequel utiliser, il vous suffit de regarder votre architecture.
En utilisant un de ces scénarios, le client a donc obtenu un token. Mais comment l’utilise-t-on pour sécuriser l’accès à des ressources ?
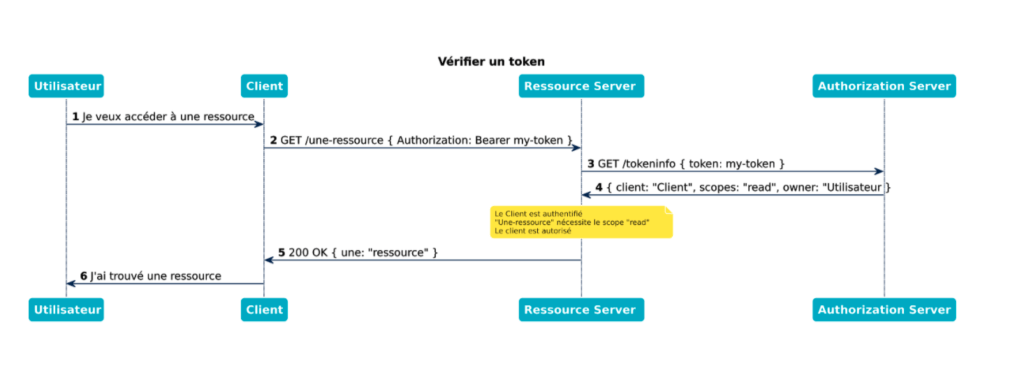
Quand un Serveur de Ressources reçoit un token dans les en-têtes d’une requête HTTP, il doit déterminer à quelle combinaison de (client, user, scopes)ce token correspond. La façon la plus évidente : il peut interroger le Serveur d’Autorisation !
_ 
_
Si l’accès à la ressource nécessite un scope qui n’est pas inclus dans le token d’accès, alors le Serveur de Ressources doit refuser la requête et répondre en utilisant le code HTTP 403.
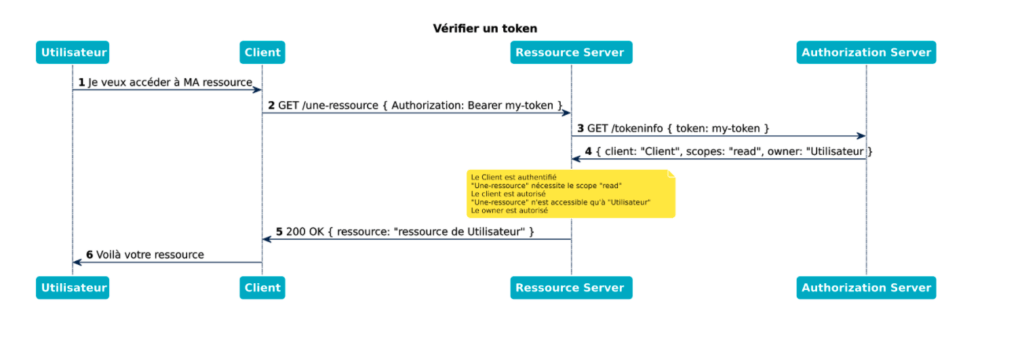
Une ressource privée est une ressource dont l’accès, en plus d’être limité à des clients qui ont un certain scope, est aussi limité à un certain ensemble d’utilisateurs. Dans notre exemple ci-dessous, la ressource de l’utilisateur n’est accessible que par lui-même (pensez à un compte en banque par exemple).
_ 
_
Avec OAuth2 et OpenID Connect, un token d’accès est lié à un scope donné. Un scope décrit les limites des actions que le Resource Owner a autorisé le client à faire en son nom. Il est souvent décrit par une chaîne de caractères ou de symboles.
Nous vous recommandons d’utiliser la casse snake_case pour décrire votre scope : par exemple friend_list, full_profile, administrator_uk, etc.).
Quelle que soit la méthode utilisée pour décrire comment un client est autorisé à accéder à du contenu, vous ne devriez prévoir qu’un petit nombre de scopes. Si vous vous rendez compte que le nombre de scopes augmente à chaque nouvelle ressource / nouveau verbe HTTP / nouveau rôle utilisateur, vous avez probablement choisi une mauvaise stratégie… Prendre un peu de temps pour réfléchir à cette stratégie est donc probablement une bonne idée.
Cette stratégie est basée sur le pattern “Access Control List” (ACL). Si vous appliquez ce pattern aux scopes tels que décrits par OAuth2, vous allez probablement vous retrouver avec des scopes du type <ressource>_<rôle>_<action> (par exemple, article_redactor_write). C’est une approche parfaitement convenable pour configurer les droits d’accès des utilisateurs, mais elle n’est pas appropriée pour les accès des clients. Le nombre de scopes possibles devient la combinaison de tous les modèles, rôles, et fonctions de votre système. Nous vous conseillons donc de ne pas utiliser cette stratégie.
Une autre stratégie pour décrire comment un utilisateur peut déléguer certains de ses privilèges à une application : décrire chaque rôle de cet utilisateur dans votre système, et en déléguer seulement certains au client. Il s’agit du pattern “RBAC” (Role-Based Access Control). Puisque “utilisateur du système” est plutôt vague, il y a souvent tout un ensemble de rôles précis (implicites ou explicites) liés à un utilisateur. Par exemple, dans le cas d’un blog, en fonction des actions qu’un utilisateur essaie de faire, il peut être vu comme :
Le but d’une approche basée sur les rôles est de décrire un scope OAuth2 comme une combinaison des rôles d’un utilisateur qu’il est prêt à déléguer au client. Adopter une telle stratégie pourra vous aider à mettre en évidence des rôles implicites de votre système auxquels vous n’auriez pas pensé ! Comme toujours en informatique, trouver les bons termes pour nommer les objets manipulés est la première étape pour une bonne stratégie… mais souvent la plus difficile.
Il vous est aussi possible de définir votre stratégie de scopes à partir du métier. Dans ce cas, au lieu de décrire chaque rôle d’un utilisateur dans votre système, vous décrivez chaque partie du domaine qui est sous sa responsabilité. Par exemple, vous avez très probablement un compte en banque : à travers ce compte vous avez accès à
Dans cette approche vous décrirez un scope comme : l’ensemble des domaines de l’utilisateur et les actions associées qu’il délègue au client. Si vous utilisez un aggrégateur bancaire basé sur l’API de votre banque, vous pouvez par exemple choisir de l’autoriser à lire votre solde et les dernières opérations, mais pas à effectuer des virements.
Un autre exemple est l’API de Facebook qui décrit assez finement les différents éléments d’un profil utilisateur (âge, date d’anniversaire, liste d’amis, etc).
Depuis que nous parlons de scopes, nous répétons qu’il s’agit des actions que le Resource Owner a autorisé le client à faire en son nom. Mais pour que l’utilisateur donne son autorisation, il faut lui demander son consentement à un moment ! C’est la fameuse page que vous avez probablement déjà vue si vous utilisez un compte Google, Facebook, Twitter, etc... pour vous connecter à d’autres applications :
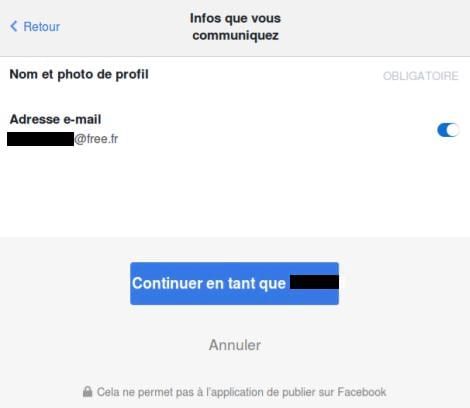
Au moment de construire une stratégie d’autorisation, vous devez choisir à quelle fréquence demander ce consentement. Trois grandes stratégies se dégagent :
Il est temps de rappeler une des clés de l’introduction de cet article : les deux objectifs d’une stratégie de sécurisation d’application sont de mener la vie dure aux attaquants potentiels, tout en facilitant la vie des consommateurs légitimes. Au moment de choisir une stratégie pour demander le consentement de l’utilisateur, il faut garder cet équilibre à l’esprit ! Car devoir passer par la phase de consentement fait perdre du temps à l’utilisateur qui peut trouver cela pénible.
Il faut donc trouver la bonne combinaison des trois stratégies en fonction des informations manipulées. Certains scopes peuvent être accordés implicitement (des informations de profil de base par exemple), d’autres doivent être demandés une fois et c’est suffisant (autoriser une application à lire mes tweets par exemple) et enfin certains doivent être rendus explicites à chaque fois (données médicales, etc).
À noter : le consentement peut être donné implicitement, mais le client doit tout de même obtenir son token via un des scénarios OAuth2.
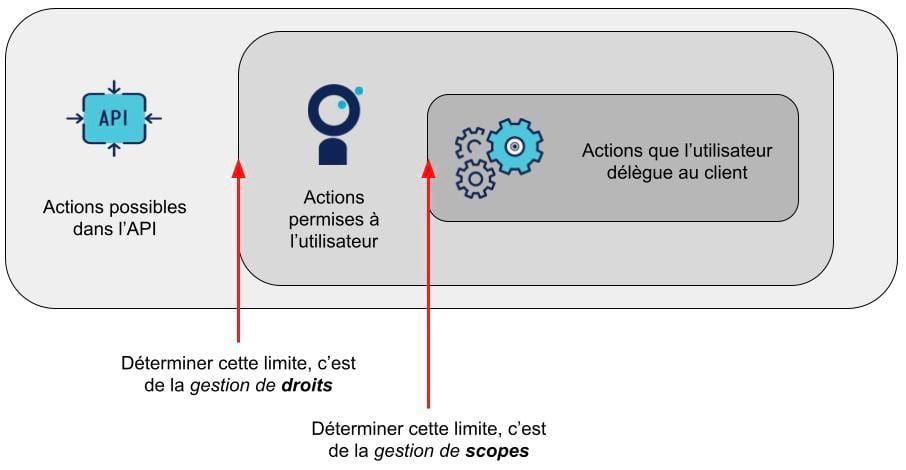
Revenons ici sur une confusion fréquente : les scopes ne doivent pas remplacer une gestion de droits au niveau de votre système ! Un scope décrit les actions que le Resource Owner autorise le client à faire en son nom... parmi les actions que l’utilisateur a le droit de faire. Et ce périmètre-là doit être fixé et géré au niveau de l’API, c’est-à-dire du serveur de ressources.
Pour résumer :
_ 
_
OAuth2 permet d’autoriser l’accès à des ressources, et de déléguer certains privilèges. Mais il ne donne aucune ligne directrice pour gérer l’identification de l’utilisateur en tant que tel. Vous avez seulement pu voir à plusieurs reprises sur les diagrammes de séquence une flèche indiquant que l’utilisateur renseignait son login et mot de passe.
Le but d’OpenID Connect (souvent abrégé en OIDC) est d’autoriser une application cliente à récupérer de manière sécurisée l’identité de l’utilisateur, en se connectant au Fournisseur d’Identité (Identity Provider). Il permet donc à une application cliente d’avoir une gestion des identités des utilisateurs sans avoir à mettre en place sa propre gestion de mots de passe. Il est donc lié à la notion de fédération d’identités (Single Sign-On ou SSO en anglais).
Il s’agit d’une extension du protocole OAuth2.0, et il est donc entièrement compatible avec l’utilisation de OAuth2. Tout ce que nous avons décrit plus haut sur OAuth2 reste vrai dans cette section. Une petite exception : les scénarios Client Credentials Grant et Resource Owner Credentials Grant ne sont pas spécifiés par OIDC.
Voilà son fonctionnement de base : dans un scénario Authorization Code Grant ou Implicit Grant, le client demande au Serveur d’Autorisation un token avec un certain nombre de scopes métier, auquel viendra s’ajouter le scope spécifique “openid”.
Lorsque le Serveur d’Autorisation génère le token d’accès OAuth (qu’on appellera par la suite access_token), il fournit aussi un token d’identité (qu’on appellera id_token). Cet ID Token contient des détails sur l’identité de l’utilisateur et le processus utilisé pour l’authentifier. L’ID Token prend la forme d’un JWT signé (plus de détails sur ce format de token plus bas). La spécification OpenID Connect définit aussi un nouvel endpoint /userinfo qui retourne l’identité de l’utilisateur (cet endpoint est à destination du serveur de ressources).
Au cas où vous auriez tout suivi depuis le début de l’article, préparez-vous bien car OIDC apporte deux changements de noms. Le Serveur d’Autorisation que nous avons appris à connaître, qui est aussi le Fournisseur d’Identité, sera maintenant nommé “OpenID Provider”. Et l’application cliente, que nous appelions simplement “Client”, sera maintenant le “Relying Party”.
Contrairement à l’access token qui a vocation à être utilisé par le client pour s’authentifier auprès du serveur de ressources (et donc être partagé au serveur de ressources), l’ID Token n’est à destination que du client, et ne devrait jamais être envoyé au serveur de ressources.
Il contient des informations à propos de la façon par laquelle l’utilisateur a été authentifié par le serveur d’autorisation, ainsi que des informations (optionnelles) sur l’utilisateur si elles ont été demandées. Toutes ces informations sont regroupées sous le nom de claims.
Certains claims sont obligatoires : il s’agit surtout d’informations à propos de la façon dont l’utilisateur a été authentifié.
D’autres claims sont optionnels et peuvent être retournés par le Serveur d’Identités si ils ont été demandés par le client. Il s’agit souvent d’informations sur l’utilisateur : par exemple son nom, son email, sa date de naissance… La spécification OIDC précise la syntaxe de beaucoup de claims standards (given_name, gender, birthdate...)
OpenID Connect s’utilise avec 3 scénarios :
Les 3 scénarios impliquent des interactions avec un navigateur web, et ils commencent par une requête envoyée par le Client au Serveur d’Autorisation. Cette requête contient plusieurs paramètres, notamment le paramètre scope (qui contient la liste des scopes demandés) qui doit contenir le scope openid. Un autre paramètre obligatoire est response_type, qui permet au client de choisir le scénario qui s’applique :
| Valeur de <br>"response_type" | Flow | Mais au fait, qu’est-ce que <br>je vais recevoir ? |
code | Authorization Code | Un code d’autorisation, <br>que vous échangerez contre <br>l’access token et l’ID Token |
id_token | Implicit | L'’ID Token <br>mais pas d’access token |
id_token token | Implicit | L’ID Token et l’access token |
code id_token | Hybrid | L’ID Token, <br>et un code d’autorisation <br>que vous échangerez contre <br>l’access token |
code token | Hybrid | Un premier access token, <br>et un code, <br>que vous échangerez contre <br>un second access token <br>(plus sécurisé que le premier) |
code id_token <br>token | Hybrid | L’ID Token, <br>un premier access token, <br>et un code <br>que vous échangerez plus tard <br>contre un second access token <br>(plus sécurisé que le premier) |
Le flow OAuth2 Authorization Code décrit plus haut s’applique, avec quelques spécificités. Vous devez d’abord rediriger le navigateur web (ou l’appareil mobile) vers l’URL d’autorisation, avec le paramètre scope pré-rempli, et ce scope doit contenir “openid”. D’autre part vous devez remplir le paramètre “response_type” avec la valeur “code”.
GET /authorize? response_type=code &scope=openid%20profile%20email%20my_other_scopes &client_id=...
À la fin des opérations utilisateur (connexion avec login/mot de passe, puis étape de consentement), le navigateur sera redirigé vers le serveur du client, avec le code d’autorisation inclus dans les paramètres de la requête. Le serveur devra alors échanger le code d’autorisation contre un access token et un ID Token. La requête prendra cette forme :
POST /token Authorization: Basic fUDU0kwep5p9NgythBmufFDM grant_type=authorization_code &code=RCxPxxcFYlunAuD9zSrQNS4C &redirect_uri=...
Pour obtenir la réponse :
HTTP/1.1 200 OK Content-Type: application/json { "access_token": "EpjZGJrprScYUD9SPSKHjSM1HOYBGKhB", "token_type": "Bearer", "refresh_token": "7AJ1C1hc6xR4aUicZjU6HeW6tKlXsNIn", "expires_in": 3600, "id_token": "eyJhbGciOiJSUzI1NiIsImtpZCI6IjFlOWdkazcifQ.ewogImlzcyI6ICJodHRwOi8vc2VydmVyLmV4YW1wbGUuY29tIiwKICJzdWIiOiAiMjQ4Mjg5NzYxMDAxIiwKICJhdWQiOiAiczZCaGRSa3F0MyIsCiAibm9uY2UiOiAibi0wUzZfV3pBMk1qIiwKICJleHAiOiAxMzExMjgxOTcwLAogImlhdCI6IDEzMTEyODA5NzAKfQ.ggW8hZ1EuVLuxNuuIJKX_V8a_OMXzR0EHR9R6jgdqrOOF4daGU96Sr_P6qJp6IcmD3HP99Obi1PRs-cwh3LO-p146waJ8IhehcwL7F09JdijmBqkvPeB2T9CJNqeGpe-gccMg4vfKjkM8FcGvnzZUN4_KSP0aAp1tOJ1zZwgjxqGByKHiOtX7TpdQyHE5lcMiKPXfEIQILVq0pc_E2DzL7emopWoaoZTF_m0_N0YzFC6g6EJbOEoRoSK5hoDalrcvRYLSrQAZZKflyuVCyixEoV9GfNQC3_osjzw2PAithfubEEBLuVVk4XUVrWOLrLl0nx7RkKU8NXNHq-rvKMzqg" }
L’ID Token a l’air peu engageant ! Mais toutes les informations décrites dans la section précédente y sont bien présentes, sous la forme un peu particulière d’un Json Web Token (voir ci-dessous).
Voici un diagramme de séquence de ce scénario (en rouge, les différences par rapport au flow Auth Code d’OAuth2).
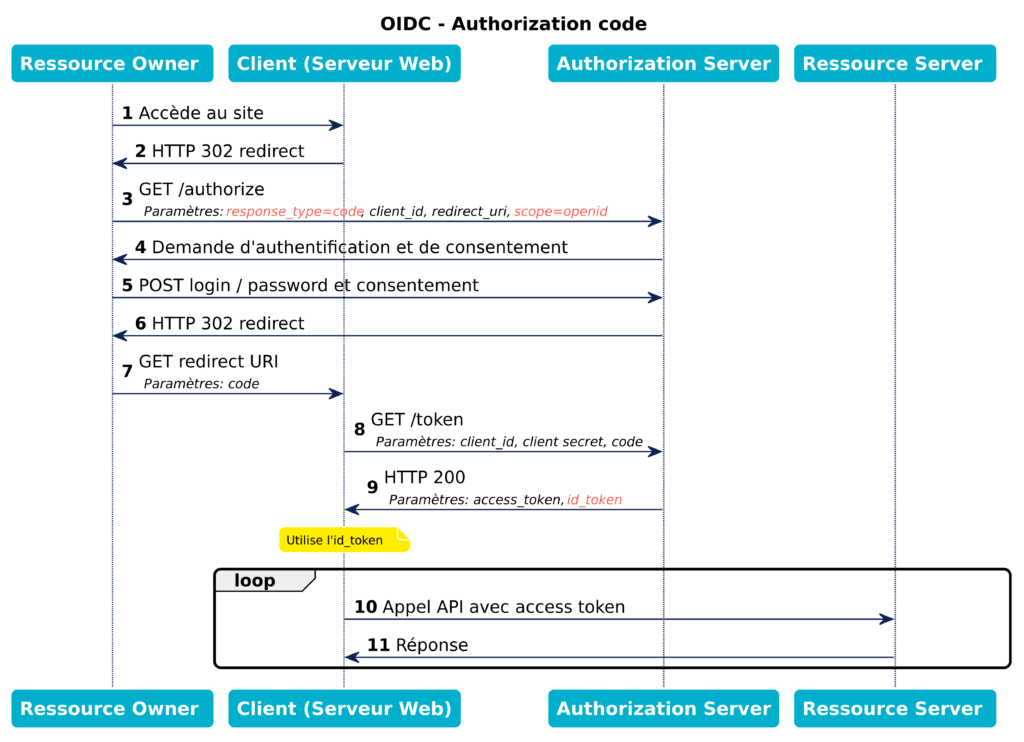
Flows OIDC: Authorization Code
Ici c’est le flow implicite décrit dans la section correspondante de OAuth2 qui s‘applique, avec certaines spécificités. Ici aussi, le scope “openid” doit être demandé pour permettre la récupération de l’ID Token.
| Paramètre | Valeur <br>(à encoder au format URL) | Pour demander : |
scope | openid ... | |
response_type | id_token | ID Token |
| ou | ||
response_type | id_token token | ID Token <br>et A_ccess Token_ |
La requête initiale prendra cette forme :
GET /authorize? response_type=id_token%20token &scope=openid%20profile%20email%20my_other_scopes &client_id=...
À la fin des opérations utilisateur (connexion avec login/mot de passe, puis étape de consentement), le navigateur sera redirigé vers le serveur du client avec un ID Token, et s’il a été demandé, un access token.
HTTP/1.1 302 Found Location: https://client.example.org/cb# access_token= EpjZGJrprScYUD9SPSKHjSM1HOYBGKhB &id_token=eyJhbGciOiJS...cifQ.ewog...AKfQ.ggW8...rvKMzqg &token_type=...
Voici un diagramme de séquence de ce scénario (en rouge, les différences par rapport au flow Implicit d’OAuth2).
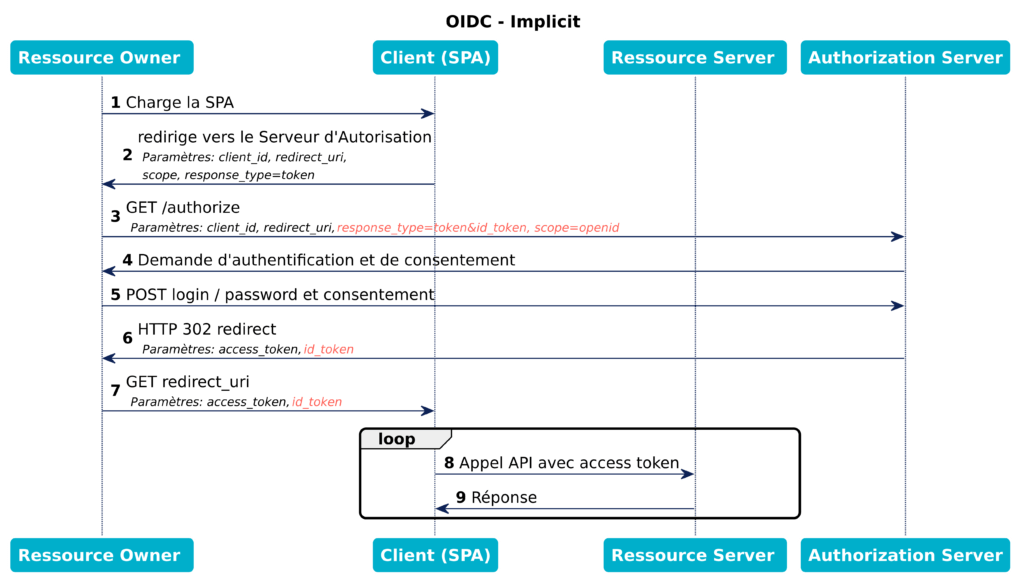
Flows OIDC: Implicit
Le scénario hybride n’est pas spécifié par OAuth2 : il est spécifique à OpenID Connect, et il mélange les flows Implicite et Authorization Code. On le déclenche en incluant dans le paramètre response_type à la fois “code” et un autre paramètre. Et comme pour les autres flows, il faut aussi demander le scope “openid”.
| Paramètre | Valeur <br>(à encoder au format URL) | Pour demander : |
scope | openid ... | |
response_type | code id_token | Un code d’autorisation, <br>et un ID Token |
| ou | ||
response_type | code id_token token | Un code d’autorisation, <br>un ID Token, <br>et un access token |
| ou | ||
response_type | code token | Un code d’autorisation, <br>et un access token |
À la fin des opérations utilisateur (connexion avec login/mot de passe, puis étape de consentement), le navigateur sera redirigé vers le serveur du client avec un code, qu’il devra ensuite envoyer au Serveur d’Autorisation pour obtenir ses tokens, ainsi que les paramètres optionnels qu’il aura demandé (access token temporaire par exemple).
Json Web Tokens (JWT) est la spécification d’une façon de générer, lire, et valider des documents JSON pour les utiliser dans un contexte HTTP. L’acronyme JWT est un terme général qui regroupe JSON Web Signature et JSON Web Encryption. Ils permettent à un fournisseur d’API de vérifier l’identité d’un utilisateur et les droits d’un client, à la réception d’une requête, sans nécessiter un appel au Serveur d’Autorisation. Le principe de fonctionnement est le suivant : le Serveur d’Autorisation appose une signature digitale à ses tokens, de sorte que le fournisseur d’API puisse vérifier la signature, et ainsi être assuré que le token a été émis par une autorité de confiance.
Nous allons nous concentrer sur JSON Web Signatures mais les principes derrière JSON Web Encryption sont les mêmes.
Une JWS est composée de 3 chaînes de caractères, encodées en Base64, séparées par des points : <headers>.<payload>.<signature>
D’après la spécification OpenID Connect, le format JWT est obligatoire pour l’ID Token. Mais il peut aussi être intéressant d’utiliser ce format pour l’Access Token ! En effet, si vous choisissez d’utiliser un token opaque (une chaîne de caractères aléatoire), votre API devra le valider auprès du Serveur d’Autorisation, pour savoir si l’access token est valide et récupérer les informations sur l’utilisateur… et ce, à chaque requête !
Alors qu’en utilisant JWT, votre API peut elle-même valider le token grâce à la signature, et récupérer les informations de l’utilisateur incluses dans le payload. Cela lui permet d’économiser bien des appels, et éviter au Serveur d’Autorisation d’avoir à supporter une charge trop lourde, d’autant plus que certaines solutions en SaaS (comme Auth0 par exemple) imposent des quotas sur ce type de requête.
Vous avez lu jusque là ? Merci, ça nous fait plaisir ! Mais on imagine bien que c’est difficile de retenir toutes ces informations-là d’un coup. Voici les informations importantes à retenir, et pour tous les détails, vous pourrez revenir lire la section qui correspond !
Maintenant, il ne vous reste “plus qu’à” mettre tout ça en pratique ! Bonne sécurisation !