“Je dispose de données annotées en nombre limité, néanmoins obtenir des données non annotées est pour moi une chose aisée. Existe-t-il des méthodes de Machine Learning permettant d’utiliser des données annotées et non annotées en même temps ?”
A travers cet article, en nous basant sur un cas d’usage assez simple, nous allons aborder cette thématique et y apporter quelques éléments de réponse.
L'apprentissage supervisé et l’apprentissage non supervisé
Les algorithmes d’apprentissage automatique ont généralement besoin de beaucoup de données pour être efficaces, ce n’est pas une surprise pour toute personne s’intéressant quelque peu à la Data Science. Communément on distingue deux types d’algorithmes :
Sur le plan de la modélisation mathématique, l’apprentissage supervisé consiste à apprendre une fonction qui à partir des données d’entrée et des résultats attendus (une matrice X par exemple et un vecteur Y) pourra établir la relation :
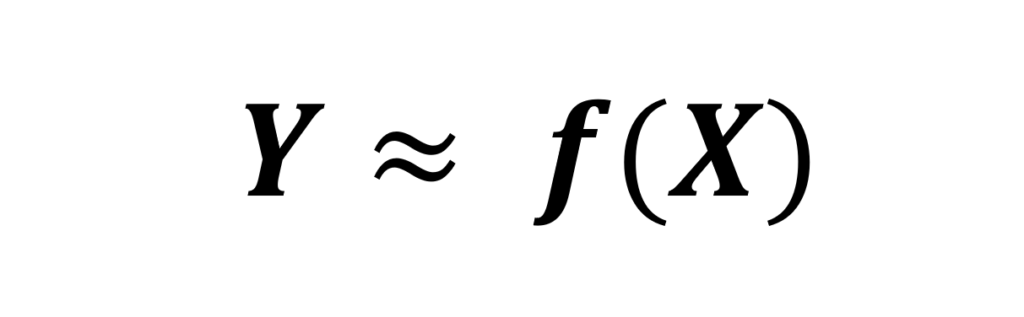
Dans le cadre de l’apprentissage non supervisé, l’objectif cette fois est de déduire la structure naturelle présente dans les données car nous ne disposons pas des résultats attendus (on se base uniquement sur la matrice X, nous n’avons pas de vecteur Y).
Supervisé + non supervisé = semi-supervisé
Il existe toutefois une catégorie intermédiaire d’apprentissage qu’on appelle l’apprentissage semi-supervisé, il s’agit d’utiliser des données annotées et non annotées. Cette catégorie d’algorithmes intéresse particulièrement la communauté des chercheurs dans le domaine du Machine Learning.
En effet, si l’obtention de données est un enjeu crucial à l’élaboration d’algorithmes performants, l’obtention de données annotées l’est plus encore lorsque l’on doit prédire une valeur ou la probabilité d’appartenance à une classe. De plus, l'obtention de données annotées est coûteuse sur le plan pécuniaire comme sur le plan du temps alloué à la tâche d’annotation (un excellent retour d’expérience dans cet article).
Parvenir à mettre au point des méthodes semi-supervisées permettrait de pallier le manque d’annotations en utilisant beaucoup de données non annotées (plus simples à obtenir) et des données annotées dans une faible proportion.
Détection de points caractéristiques sur un visage (facial landmark detection)
A partir d’un cas d’usage spécifique : la prédiction de cinq points caractéristiques sur des photos de visage, nous présentons une méthode sur laquelle nous avons travaillé afin de créer un réseau de neurones convolutif semi-supervisé. Dans un premier temps nous avons construit un réseau de neurones supervisé, puis un autre semi-supervisé.
Nous vous détaillerons ici la marche à suivre.

^Détection de 5 points caractéristiques^
Le CNN supervisé pour la prédiction de points caractéristiques
Un réseau de neurones convolutif est un type d’algorithme de Deep Learning servant principalement à l’apprentissage d’éléments caractéristiques d’images. Communément ils sont connus pour effectuer de la classification (« s’agit-il d’une image de chat ? » plus d’informations ici et là). On peut également utiliser ce type de réseau de neurones pour faire de la régression (prédiction de points caractéristiques, détection d’objets…), c’est précisément ce que l’on se propose de faire.
Afin de mener à bien notre tâche, nous avons choisi une architecture de type DenseNet (voici le lien de l’article original et deux autres articles d’explications ici et là).
^Schéma d’architecture de type DenseNet avec 4 Dense Block^
Cette architecture présente certains avantages. Elle permet par exemple de se prémunir du phénomène de gradient évanescent (vanishing gradient) qui entraîne l’arrêt de l’apprentissage, elle est également efficace en termes de temps de calcul. Dans la littérature, il existe d’autres architectures qui pourraient se révéler performantes pour la problématique que nous traitons, néanmoins nous nous limiterons à celle-ci (par exemple ResNet) .
Lors de la phase d’entraînement, la mise à jour des filtres de convolution se fait par l’intermédiaire d’un algorithme d’optimisation qu’on appelle l’algorithme du gradient stochastique (ou certaines de ses variantes). L’erreur commise par le modèle doit être estimée à plusieurs reprises lors des phases dites de rétropropagation (back propagation), afin de quantifier l’erreur on doit choisir une fonction qu’on appelle « fonction de coût » ou « fonction de perte » (cost function ou loss function).
Comme les autres algorithmes supervisés, les réseaux de neurones convolutifs apprennent à partir des données d’entrée et de la cible à prédire une fonction mathématique non linéaire. Le choix de la loss function doit correspondre à la problématique que l’on souhaite modéliser, c’est la raison pour laquelle la configuration de la dernière couche de notre réseau doit être appropriée pour la fonction de coût choisie (fully connected layer).
Dans le cas qui nous concerne, nous avons choisi l’erreur quadratique moyenne comme fonction de coût (mean squared error loss), c’est l’une des fonctions que l’on utilise classiquement pour résoudre des problèmes de régression. Elle s’écrit comme suit :
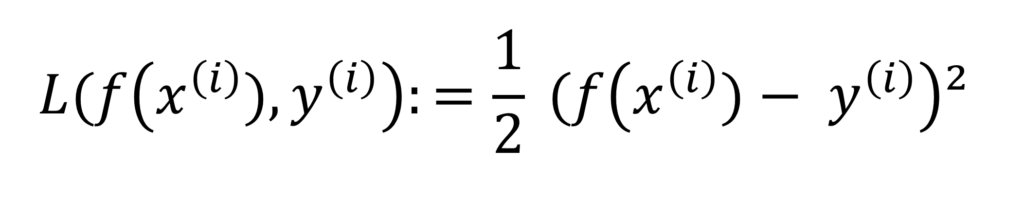
Conceptuellement il s’agit pour notre problème de minimiser la distance au carré entre la prédiction (ici les coordonnées d’un point de ℝ²) et sa valeur cible. Plus on aura minimisé la distance séparant le point prédit de sa valeur cible et plus notre prédiction sera précise.
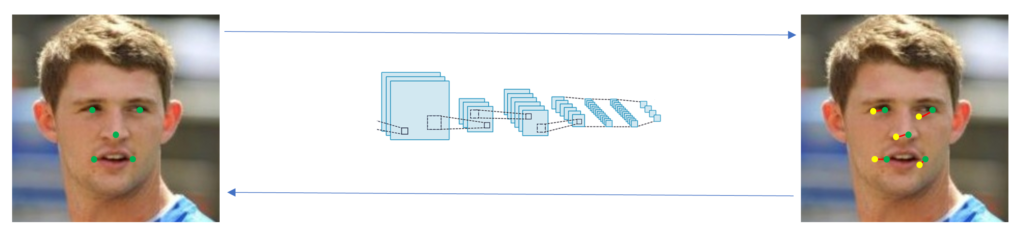
^En vert les labels, en jaune les prédictions et en rouge la distance séparant les labels des prédictions. Les flèches et le schéma au centre symbolisent le mécanisme de <a href="https://medium.com/machine-learning-for-li/explain-feedforward-and-backpropagation-b8cdd25dcc2f">feed forward et backpropagation</a> classiques des réseaux de neurones. ^
La mise en place de l’algorithme supervisé ne pose donc pas de difficultés particulières.
Avec uniquement 1000 images annotées nous parvenons déjà à atteindre une précision de l’ordre de :
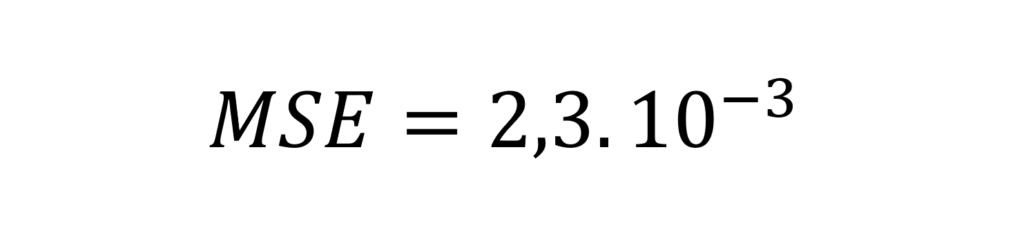
Cette valeur sera notre valeur de référence (baseline).
Que dit la recherche ?
Les articles de recherche récents traitant du Semi-Supervised Learning parlent majoritairement de problématiques de classification, nous pouvons en citer quelques-uns :
Ce dernier article (An Overview of Deep Semi-Supervised Learning) plus récent rassemble certaines des dernières avancées dans le domaine.
Ces différentes approches nous ont inspiré pour construire un réseau de neurones convolutif semi-supervisé (surtout l’article MixMatch: A Holistic Approach to Semi-Supervised Learning).
Pour cela, nous construirons une unsupervised loss function spécifique à la partie non-supervisée du problème ainsi qu’une supervised loss function classique pour la partie supervisée (mean square error), la somme de ces deux loss functions constitue la custom loss function de notre réseau de neurones semi-supervisé.
Pour la partie non-supervisée du problème, l’idée est d’appliquer une transformation géométrique aux images non annotées et de construire notre custom loss.
Entrons en matière.
Comment va-t-on procéder ?
Lors de la phase d’apprentissage, l’algorithme de minimisation est une brique incontournable du problème. Les images occupant beaucoup trop de place en mémoire il convient d’envoyer au réseau de neurones des batches d’images (l’ensemble des batches constitue une epoch, ce qui veut dire que l’ensemble du dataset « est passé à travers » le réseau).
Les filtres de convolution sont mis à jour après le parcours d’un batch (par exemple 64 images).
Chaque batch sera composé d’images annotées dans un premier temps, elles permettent au réseau de débuter l’apprentissage, ensuite viennent les images non annotées.
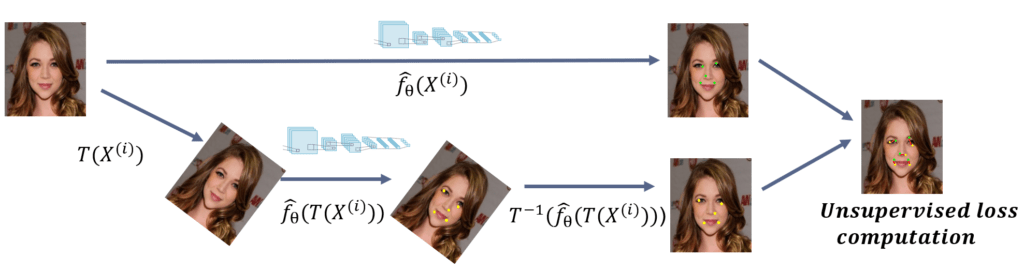
C’est lors du traitement des images non annotées que la construction astucieuse de la partie non supervisée de la loss intervient, chaque image non annotée subit une ou plusieurs transformations géométriques (translation, rotation…). Les deux images, l’image non annotée qui n’a subi aucune transformation géométrique et l’image transformée, « passent à travers » le réseau (feedforward), ainsi nous obtenons les prédictions pour les deux images (5 points caractéristiques c’est-à-dire 10 nombres flottants).
Une fois que les prédictions sont obtenues, nous appliquons à l’image transformée la transformation inverse, c’est-à-dire que nous ramenons l’image (et aussi ses prédictions) à l’état original.
Nous arrivons enfin à l’expression de la partie non supervisée de la custom loss. Il s’agit de calculer la mean square error entre les prédictions de la photo non labellisée et celles de cette même photo ayant subi dans l’ordre : la transformation géométrique, la prédiction et la transformation inverse.
Formalisons tout ceci :
On se donne une transformation géométrique (et sa transformation inverse T-1):
![]()
La fonction de prédiction de notre modèle, étant donné une image X cette dernière nous renvoie les coordonnées des 5 points caractéristiques :
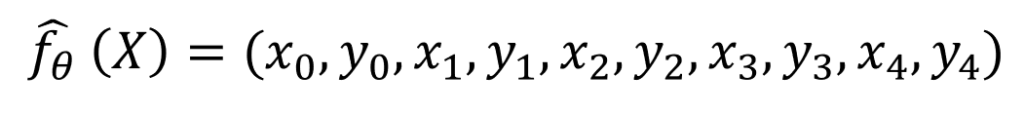
D'où le schéma d'architecture suivant :
Ainsi pour une image donnée non annotée, l’erreur est la suivante :
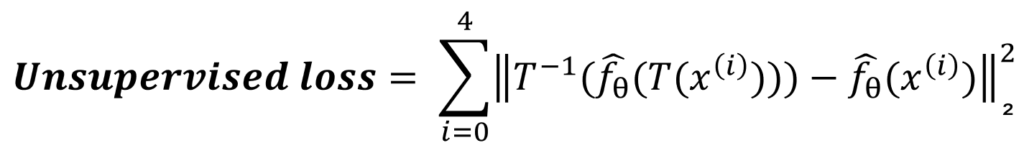
Pour une image donnée annotée on a la supervised loss (c’est la MSE) :
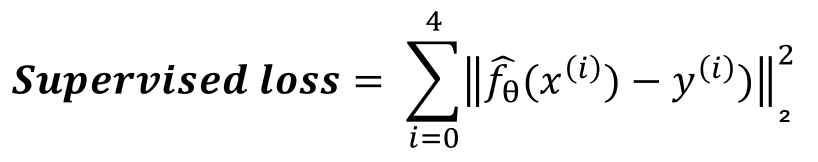
Comme nous l’avions mentionné ci-dessus, la Semi-Supervised loss sera la somme de la supervised loss et de l’unsupervised loss :
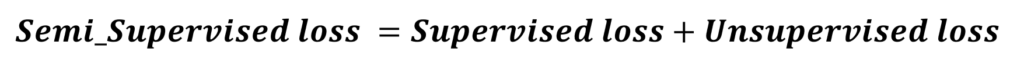
Premiers résultats
Nous comparons ici le réseau de neurones supervisé et le réseau de neurones semi-supervisé.
L’algorithme supervisé est entraîné avec 1000 images annotées, l’algorithme semi-supervisé est entraîné avec 1000 images annotées et 9000 images non annotées. Nous disposons d’un autre jeu de 5000 images annotées pour la validation.
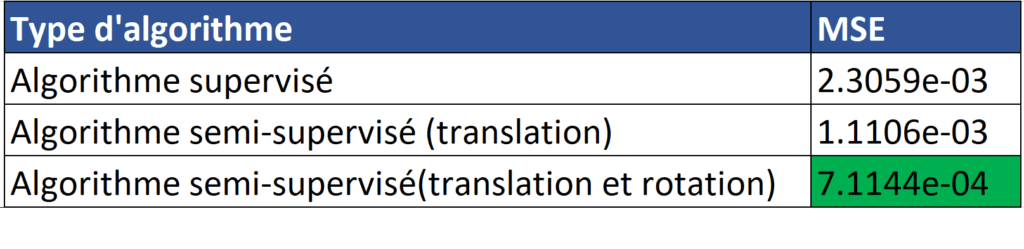
Nous présentons ici les résultats que nous avons obtenus pour deux custom loss différentes: la première où nous appliquons une translation, la seconde ou nous appliquons une translation et une rotation.
On constate que l’algorithme semi-supervisé fait mieux que l’algorithme supervisé, l’utilisation des 9000 images non annotées et des transformations géométriques aident donc à l’apprentissage !
Quelques améliorations
Pour obtenir ces premiers résultats nous avons fixé un certain nombre d'hyper paramètres qu’il convient d’optimiser. Par exemple le nombre d’images annotées par batch ou encore le coefficient multiplicateur à ajouter devant le terme de l’unsupervised loss (λ).
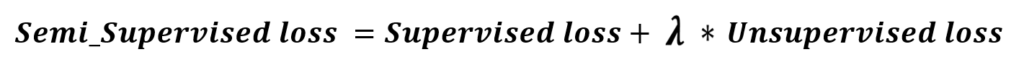
Enfin nous avons constaté qu’en appliquant les transformations géométriques (translation ou translation et rotation) il pouvait arriver que des points caractéristiques sortent du cadre de l’image, nous avons donc décidé d’ignorer les points qui sortiraient du cadre dans le calcul :
En prenant en compte tout ceci, nous améliorons encore les résultats (avec 16 images annotés pour 64 images par batch et λ = 0,25) :

Conclusion et perspectives
L’apprentissage semi-supervisé pour la prédiction de points caractéristiques sur un visage est donc une méthode qui obtient de meilleures performances que l’apprentissage supervisé (avec un nombre d’images annotées fixé à 1000 images pour les deux réseaux).
Dans le cadre du domaine de définition de cette étude, nous sommes parvenus à remédier au manque d’annotations dans les données par la construction d’une custom loss.
Il nous reste probablement à améliorer encore les différentes transformations géométriques que nous appliquons, nous pourrions augmenter également la taille du jeu de données et le pourcentage d’images annotées pour affiner encore nos résultats.
Néanmoins il existe d’autres approches qui pourraient s’avérer plus prometteuses encore, nous pensons au virtual adversarial training par exemple.