Having an efficient flow monitoring is critical: integrating all data flows, it offers an overall view of the entire Information System.
This article aims to help you compare your current system with generally observed good practices and provides you with suggestions to improve it.
We call flow a collection of service calls and/or message sending which as a whole represents a business service. In a complex Information System, such flow often goes through multiple applications and sometimes uses several technologies. For example, a user can click on a screen that triggers a REST will eventually call which causes a SOAP process whose execution sends a bunch of JMS messages.
Monitoring these flows means implementing Business Activity Monitoring. This involves collecting data in all application layers in order to correlate them. This provides an aggregated transversal overview vision of the activity of your Information System. This monitoring must at any time provide the state of health and performance of important business functions (Key Performance Indicators). In the past, this information was often computed separately for each technical layer.
The monitoring of flow does not replace the monitoring of components but completes it in the same way that integration tests complete unit tests. Each block must be monitored separately in a technical way to identify its own problems, while flow monitoring will look at transverse elements and activities that require an overview of the system. There is overlaps between the two but do not confuse them nor use one to replace the other.
In the following article, a service message means either the content of a service or of a message.
The essential feature is the ability to identify business flows in atomic messages. Typically this requires the use of a unique identifier (correlation id). All messages in the same stream will therefore contain the same identifier. This requires all applications to contain custom components in charge of generating the identifier string and transmitting it through the processes. These components will also be responsible for providing a copy of each message for the monitoring system.
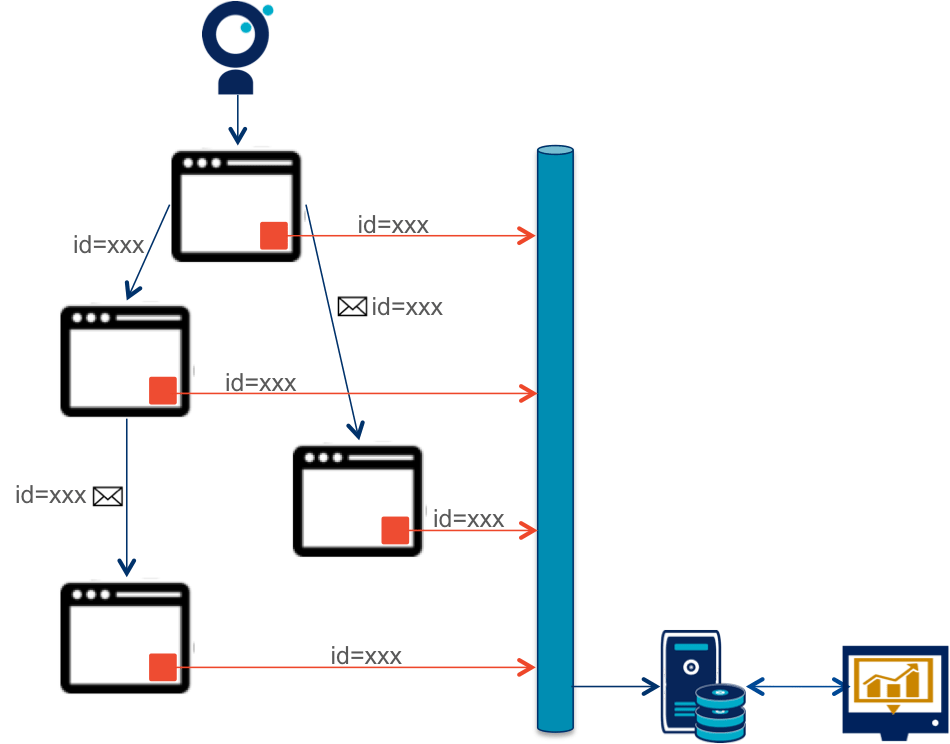
The system must be able to take into account heterogeneous events: if the messages sent by the various components have common elements (timestamp for example), they also contain specific information related to the business service (name of business service, object identifier). Being able to easily integrate these data will enable you to build more accurately functional metrics which will evolve along with the services.
To make the most of this data, you must have a configurable dashboarding system: such systems are not only used for predefining a set of fixed monitoring screens, but also for analysis or investigation. The monitoring systems usually used are often ill-suited to this type of use: their "old" ergonomics makes the investigation of data painful. Moreover, it uses monolithic solutions that integrates monitoring of data collection and storage.
The database must provide functionality for indexing with maximum coverage, the ideal being to index all the data fields. This simplifies the investigations in case of errors: for example, you can identify all messages concerning a certain account number. For volume issues, we can limit the indexing time (at least 48 hours), keeping the possibility of re-indexing past messages.
A failure in the monitoring components should never result in consequences to the business, so be aware to technically isolate them.
Next, monitoring should not lead to loss of performance, the monitoring messages have to be sent as asynchronous events (pattern wiretap) through a middleware of messages. The best solution is a dedicated messaging infrastructure, since this avoids any risk of overload.
Finally, one should limit business developments in the monitoring components: if the configuration or some custom development can't be avoided, especially for very specific metrics, duplicating business behaviors must be avoided. The result is often fragile and will make business evolutions more difficult to achieve.
To meet these criteria, you can identify different components for monitoring flows:
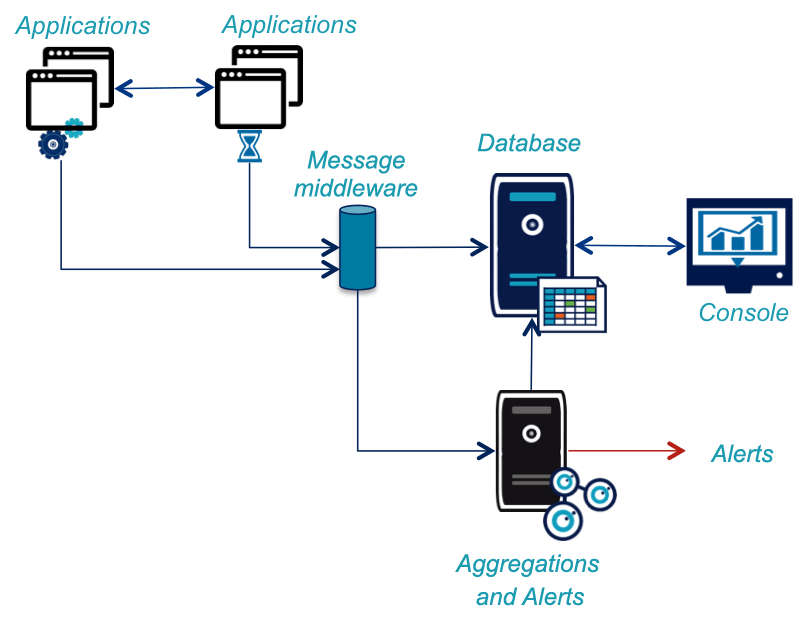
Your Information System already has some of the technical components needed, such as message system or database. Unfortunately the specificities of monitoring often prevent the use of identical tools:
This type of architecture based on standard components is limited in two aspects, technical and functional.
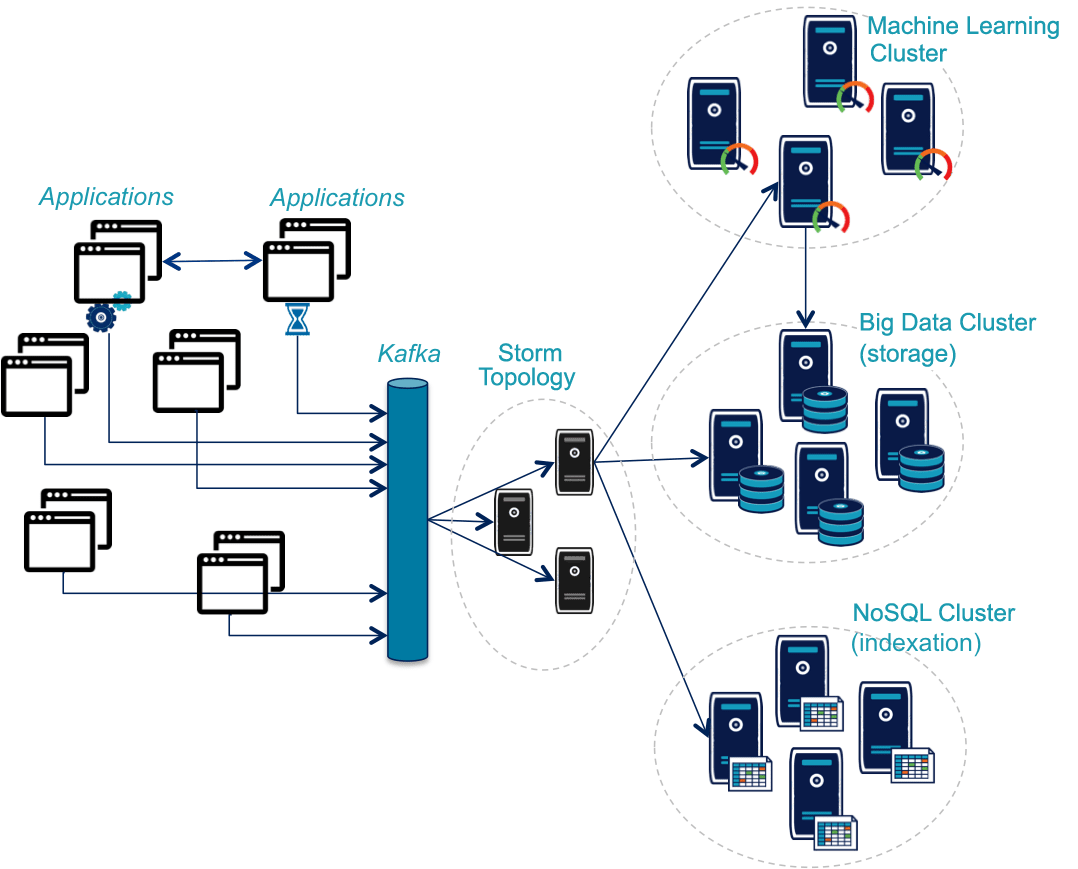
The first limitation is related to the increasing number of messages to be processed. In systems based on micro-services architectures and that incorporate new usages (mobile applications, Internet of Things) the number of messages is multiplied by 10, 100, 1000. As the goal of the monitoring system is to handle all the messages, it must increase its capacity by the same rate.
This causes the introduction of several solutions:
This kind of "big data" architecture allowing combination of multiple processing approaches while maintaining a unified storage is called DataLake.
Following the classical rules engines, we begin choosing more advanced analysis solutions for a better measure of what's happening and for better predictions. In this context, the business part of monitoring is becoming more and more important and the distinction fades with classical BI. We believe that soon these systems will be improved by online machine learning solutions.
This is our vision about the value of monitoring flow. Today it is essential for operational reasons; tomorrow it will generate business value. The introduction of this kind of solutions in an Information System is a structuring project but is based on well-known and open components, so nothing should stop you from doing it