Cet article se veut une vue d'ensemble du logiciel OpenERP.
Dans un premier temps sont présentés l'entreprise et le contexte dans lequel évolue le logiciel. Ensuite les aspects techniques d'OpenERP sont introduits : architecture, contenu d'un module, gestion des vues et des objets ...
C'est marqué dessus! OpenERP est un Enterprise Resource Planner. Le périmètre de l'outil couvre (entre autres) les domaines suivants:
OpenERP est distribué en licence GNU AGPL (Affero GPL) qui est une extension de la licence GNU GPL pour les applications réseaux. Dans les faits, cela se traduit notamment par la possibilité d'accéder au code source, de le modifier et enfin d'utiliser l'application sans payer de licence.
OpenERP est édité par la société belge éponyme fondée en 2005. Début 2010, le nom OpenERP est apparu dans les journaux financiers suite à la levée de fonds de 3 millions d'euros, notamment attribues par Xavier NIEL, le fondateur de Free.
Outre le modèle économique classique des éditeurs libres - bug fixing, migrations, alertes de sécurité et formations - OpenERP propose une utilisation en mode SaaS pour 39 € / mois/ utilisateur.
Pour assurer le support au niveau mondial, l'entreprise qui ne compte que 85 employés se base sur un réseau de partenaires.
L'environnement OpenERP se compose de 150 sociétés partenaires dans le monde mais aussi des contributeurs individuels (environ 800) qui participent à l'évolution de l'application. L'interaction entre OpenERP et la communauté des contributeurs passe par Launchpad. Chacun peut soumettre un bug et en suivre la correction, poser des questions, proposer des améliorations, contribuer aux traductions et enfin accéder au code source.
Les contributeurs sont répartis dans différentes catégories :
Grâce à ce schéma, plus de 700 modules sont disponibles dans les différentes branches addons, extra addons et community addons.
Dans la suite de cet article, nous nous baserons sur la version 5 d'OpenERP; disponible pour Windows, Linux et MAC.
OpenERP est basé sur du client / serveur en mode déconnecté. Comme tout ERP qui se respecte, c'est avant tout une base de données - PostgreSQL - sur laquelle est ajouté un serveur applicatif - OpenERP server qui gère les protocoles suivants : Net-RPC et XML-RPC en version sécurisée ou non.
Le serveur de web-services peut être attaqué directement par un client GTK fourni ou bien par un serveur web.
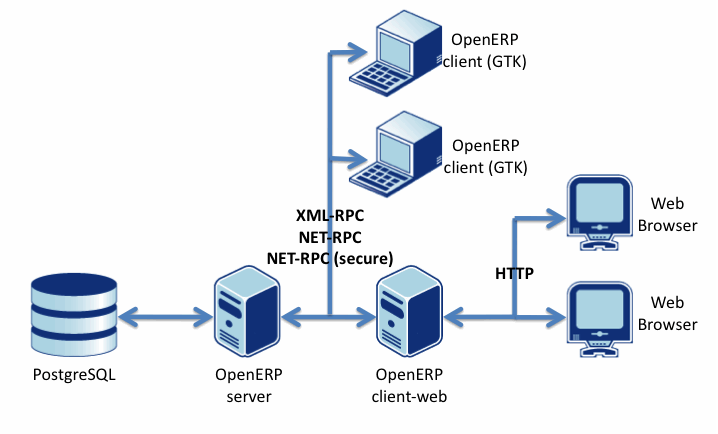
Les composants server et client-web sont écrits en python.
OpenERP repose sur le framework OpenObject qui offre les mécanismes suivantes :
Par ailleurs, toutes les fonctionnalités OpenERP sont contenues dans des modules dont l'état est géré par OpenERP server.
La structure suivante est celle préconisée :
Les fichiers python définissent des objets (tables) avec des comportements tandis que les fichiers XML/CSV chargent des données (entrées dans les tables).
Le fichier __terp__.py doit obligatoirement être présent dans un module. En voici un exemple avec celui du module de base ('base'!) :
{
'name': 'Base',
'version': '1.1',
'category': 'Generic Modules/Base',
'description': """The kernel of OpenERP, needed for all installation.""",
'author': 'Tiny',
'website': 'http://www.openerp.com',
'depends': [],
'init_xml': [
'base_data.xml',
'base_menu.xml',
'security/base_security.xml',
'res/res_security.xml',
'maintenance/maintenance_security.xml'
],
'update_xml': [
'base_update.xml',
'ir/wizard/wizard_menu_view.xml',
'ir/ir.xml',
'ir/workflow/workflow_view.xml',
'module/module_wizard.xml',
'module/module_view.xml',
'module/module_data.xml',
'module/module_report.xml',
'res/res_request_view.xml',
'res/res_lang_view.xml',
'res/partner/partner_report.xml',
'res/partner/partner_view.xml',
'res/partner/partner_wizard.xml',
'res/bank_view.xml',
'res/country_view.xml',
'res/res_currency_view.xml',
'res/partner/crm_view.xml',
'res/partner/partner_data.xml',
'res/ir_property_view.xml',
'security/base_security.xml',
'maintenance/maintenance_view.xml',
'security/ir.model.access.csv'
],
'demo_xml': [
'base_demo.xml',
'res/partner/partner_demo.xml',
'res/partner/crm_demo.xml',
'base_test.xml'
],
'installable': True,
'active': True,
'certificate': '0076807797149',
}
Ce fichier contient quatre listes :
Par ailleurs, le champ 'category' définit le type du module. On distingue des modules de base, locaux (plan de compte), ... et surtout les modules profile qui définissent un modèle d'installation pour de nouvelles base de données, que ce soit au niveau des dépendances (modules installés) ou des des écrans d'installation.
Chaque objet métier doit hériter de la classe osv.osv pour devenir persistant. Les contraintes sont les suivantes:
Voici un exemple avec la classe 'res.country':
from osv import fields, osv
class Country(osv.osv):
_name = 'res.country'
_description = 'Country'
_columns = {
'name': fields.char('Country Name', size=64,
help='The full name of the country.', required=True, translate=True),
'code': fields.char('Country Code', size=2,
help='The ISO country code in two chars.\n'
'You can use this field for quick search.', required=True),
}
_sql_constraints = [
('name_uniq', 'unique (name)',
'The name of the country must be unique !'),
('code_uniq', 'unique (code)',
'The code of the country must be unique !')
]
def name_search(self, cr, user, name='', args=None, operator='ilike',
context=None, limit=80):
if not args:
args=[]
if not context:
context={}
ids = False
if len(name) == 2:
ids = self.search(cr, user, [('code', 'ilike', name)] + args,
limit=limit, context=context)
if not ids:
ids = self.search(cr, user, [('name', operator, name)] + args,
limit=limit, context=context)
return self.name_get(cr, user, ids, context)
_order='name'
def create(self, cursor, user, vals, context=None):
if 'code' in vals:
vals['code'] = vals['code'].upper()
return super(Country, self).create(cursor, user, vals,
context=context)
def write(self, cursor, user, ids, vals, context=None):
if 'code' in vals:
vals['code'] = vals['code'].upper()
return super(Country, self).write(cursor, user, ids, vals,
context=context)
Country()
La classe (osv.osv) définit un certain nombre d'attributs et méthodes. De plus, les champs d'un objet peuvent être simples (booléen, entier, datetime, ...), une référence à d'autres objets métiers (many2one, many2many, one2many) ou bien associés à un fonction pyhton spécifique. Pour chaque champ, les attributs string (libellé), required, readonly, help (info bulle d'aide) ou select (champ définissant un critère de recherche) peuvent être spcéifiés.
Parmi les attributs d'osv.osv, on distingue notamment:
Par ailleurs, chaque objet héritant d'osv présente les méthodes : create, search, read, write, copy, unlink, browse (permet d'utiliser la notation pointée sur les champs d'un objet), default_get (retourne les valeurs par défaut), perm_read (retourne l'identifiant de l'utilisateur qui a créé l'objet), fields_get (retourne la liste des champs avec leur description), name_get, name_search, import_data, export_data.
Il est possible de redéfinir ces méthodes pour chaque objet - ce qui est fait dans l'exemple 'res.country' pour les méthodes name_search, create et write.
En outre, dans la majorité des prototypes des méthodes de l'objet osv.osv figure un curseur de base de données permettant de faire directement des requètes SQL.
Les représentations d'un objet (écran) sont des entrées XML stockées dans une table spécifique. Un objet peut avoir deux type de représentations :
Par exemple, l'objet res.country a les vues suivantes :
<record id="view_country_tree" model="ir.ui.view">
<field name="name">res.country.tree</field>
<field name="model">res.country</field>
<field name="type">tree</field>
<field name="arch" type="xml">
<tree string="Country">
<field name="name"/>
<field name="code"/>
</tree>
</field>
</record>
<record id="view_country_form" model="ir.ui.view">
<field name="name">res.country.form</field>
<field name="model">res.country</field>
<field name="type">form</field>
<field name="arch" type="xml">
<form string="Country">
<field name="name" select="1"/>
<field name="code" select="1"/>
</form>
</field>
</record>
Ce qui donne les résultats suivants :
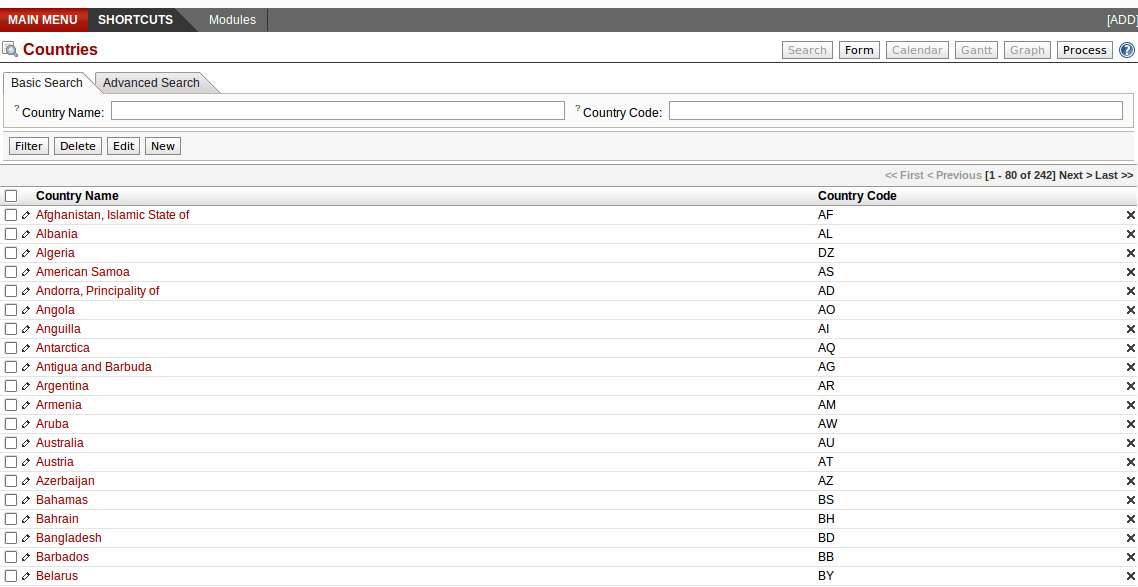

Les éléments de mise en forme peuvent être : un champ de l'objet, un bouton, un séparateur, un libellé, un groupe d'autres éléments, des onglets, ..
A ces éléments s'ajoutent des attributs comme readonly, required, invisible, string ou encore widget (url, email, progressbar, ...). Les attributs readonly, required ou invisible peuvent avoir une valeur dépendante d'autres champs. Par exemple, certains paramètres d'une facture ne sont éditable que lorsque celle-ci est à l'état de brouillon.
Pour terminer la description des vues, il est possible de faire de l'héritage entre vues, pour remplacer, ou ajouter des éléments. Le positionnement de l'ajout ou de la substitution peut se faire par sélections XPATH.
Le chargement de données dans OpenERP se fait principalement par des fichiers XML. Chaque fichier doit respecter la structure suivante:
<?xml version="1.0" encoding="utf-8"?>
<openerp>
<data noupdate="1">
<record id="entry_id" model="table_name">
<field name="field1_name">value</field>
<field name="field2_name" ref="referenced_id" />
<field name="field3_name" model="table_name" search="[('field', 'operator', 'value')]" />
</record>
</data>
</openerp>
Chaque entrée en base de données - élément record - doit définir les attributs id et model (nom de la table/objet). id peut être relatif ou absolu, ce qui permet de modifier des entrées créées dans un autre module :
<record id="new_entry_A" model="table_name">
...
<record id="module_A.entry_A" model="table_name">
...
Dans le cas de champs relationnels, les attributs 'ref' et 'search' permettent de lier des entrées entre elles. 'ref' permet de spécifier de manière absolue ou non un identifiant préalablement chargé. 'search' permet de spécifier un critère de recherhe sous la forme d'une liste de tuples : [('field_name', 'operator', 'value'), ...]
L'attribut 'noupdate' définit lors d'une mise à jour du module, le comportement du système : les données en base devront elles être écrasées par le contenu du fichier XML ? Cet attribut est donc à manipuler avec précaution au risque d'écraser les modifications faites par les utilisateurs.
Outre le XML, OpenERP supporte le chargement de fichiers CSV. Dans ce cas, le nom du fichier doit être le nom de la table SQL où l'insertion doit se faire. De plus, le nom des colonnes du fichier CSV doivent être identiques aux colonnes de la table.
Le CSV permet de charger des quantités importantes de données comme les listes de clients, de produits ou encore les comptes financiers.
L'interface graphique permet outre la modification de toutes les entrées métiers, la customisation des vues et des définitions d'objets :
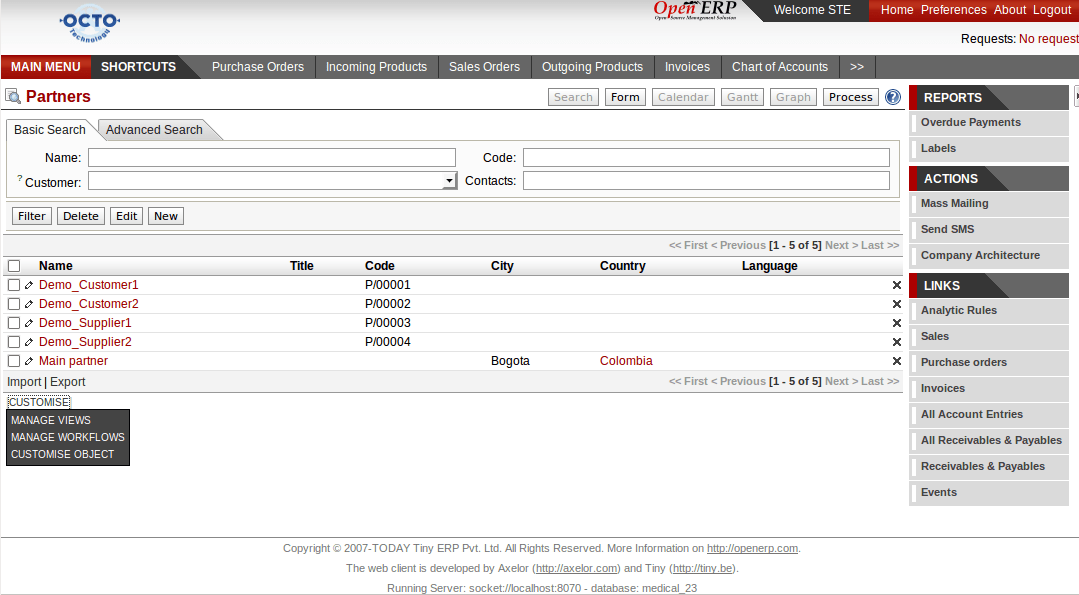
Par ailleurs, les modifications faites par des utilisateurs sont récupérables grâce au module 'base_module record' qui permet de générer des fichiers XML correspondant aux changements faits depuis le démarrage d'une session d'enregistrement.
Dans cet article, nous n'avons adressé qu'une petite partie des aspects d'OpenERP. De nombreux concepts comme : les workflows et processus, les rapports, la gestion des droits des utilisateurs n'ont pas été abordés.
A suivre donc.