Aujourd’hui, je réalise qu’il y a un réel engouement autour de la conteneurisation, et plus particulièrement de Docker. On ne cesse de me rabacher qu’en tant que dev, cela pourrait me faciliter de nombreuses tâches au quotidien. Mais comment ?
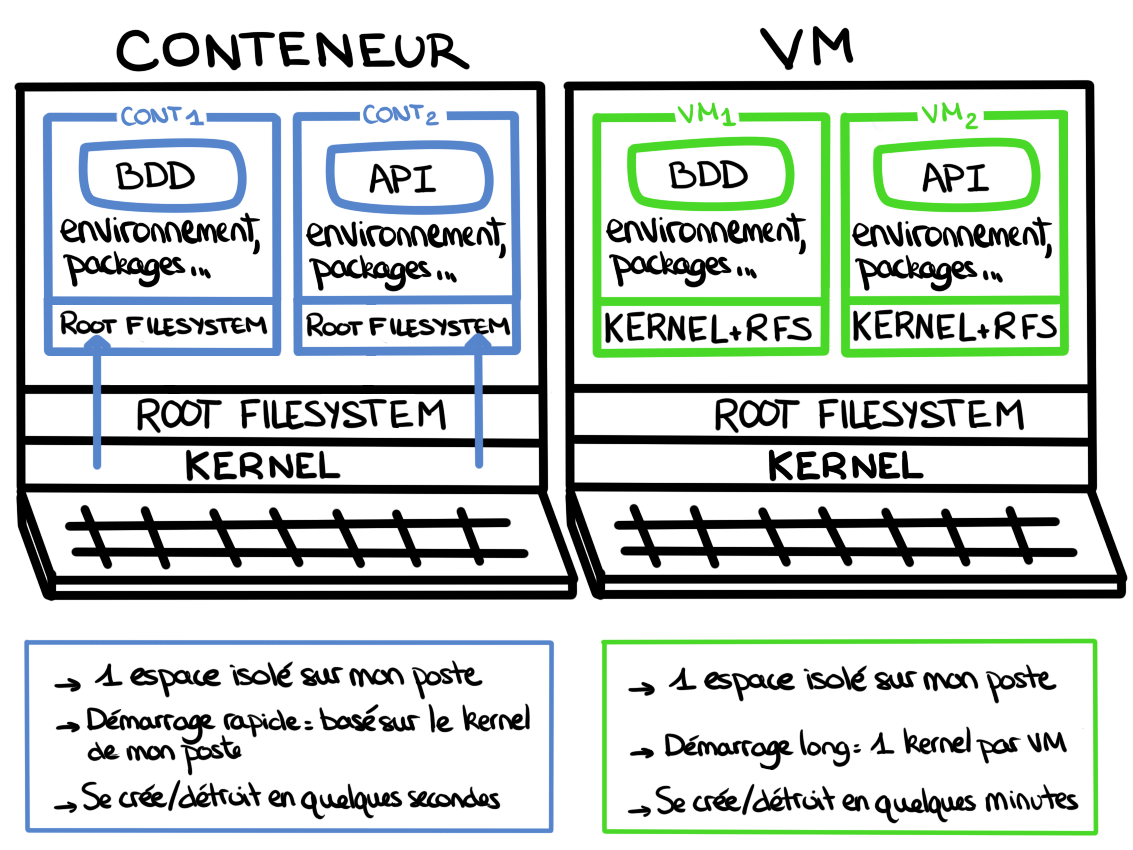
Tout d’abord, quelles sont les différences entre une VM et un conteneur ?
Aujourd’hui, je travaille sur Docker. C’est l’outil qui a démocratisé la conteneurisation et qui est le plus répandu. De plus, de nombreux outils open source se basent dessus, tels que Molecule (qui permet de tester du code Ansible), ou Kubernetes (un orchestrateur de conteneurs).
Pour débuter, il y a deux objets de base à connaître : l’image et le conteneur. Une image est une "photo" de l'état souhaité de notre serveur en production : code et dépendances. C'est à partir de cette image que l'on génère des conteneurs, des "boîtes" où tourne notre code, que l’on utilise puis que l’on détruit.
Si on peut tenter une analogie avec la programmation orientée objet : une image est l’équivalent d’une classe et un conteneur est l’équivalent d’une instance de cette classe.
De plus, la philosophie des conteneurs est assez simple :
Que l’on soit Dev ou Ops, je pense que tout le monde a déjà entendu le fameux adage “ça marche sur mon poste”. Quand ce genre de problème survient, il se situe souvent dans les différences entre les configurations (soucis de versions, de droits) qui peuvent être difficiles à déboguer.
Un premier pas dans l’uniformisation des environnements a été entrepris avec l’introduction des machines virtuelles. Malheureusement, elles nécessitent les mêmes opérations que les machines de développement (mise à jour, configuration …).
Si mes applications sont stateless, configurables par variables d’environnement et si je respecte les standards de 12factor, alors mes conteneurs seront iso-fonctionnels avec les mêmes variables d’environnement. Cela implique que si les tests sont validés pour un conteneur alors je serai assuré que tous les conteneurs issus de la même image auront le même comportement. Car oui, utiliser un conteneur ne nous exempt pas de poser des tests !
Ainsi, l’image produite testée est utilisée en production, et on est sûrs qu’elle aura le comportement attendu. De même, si un bug se produit en production, il me suffit d'instancier un conteneur à partir de cette image avec la configuration de production pour être sûr de pouvoir le reproduire.
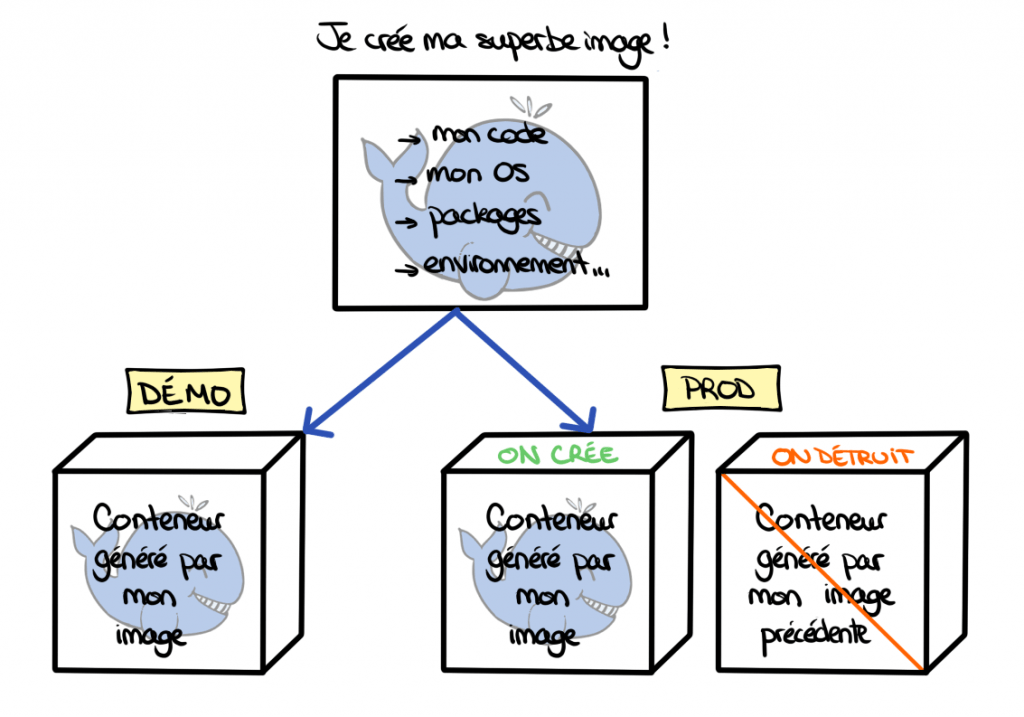
A noter que même si notre production ne fait pas tourner de conteneurs, on peut tout à fait en utiliser pour faciliter le développement de l’application. Cependant, il faut garder en mémoire que l’introduction de Docker nécessitera un apprentissage supplémentaire. Faut-il alors favoriser un développement avec une architecture simple ou se rapprocher au plus tôt de la CI/prod et viser la reproductibilité ? À vous de décider !
Je démarre un nouveau projet au sein d’une équipe qui utilise Docker ? Hop, j’installe Docker, je démarre le container avec la dernière version du code en cours de développement, et c’est parti ! Je suis sûr d’avoir les mêmes versions des outils que mes collègues, quel que soit l’OS sur mon poste de travail !
De plus, les montées de version sont facilitées pour toute l’équipe, et on est sûrs que tout le monde est à jour.
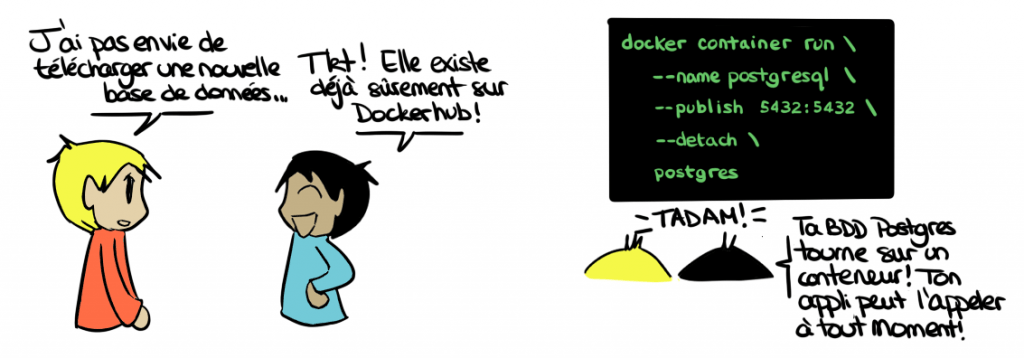
En tant que développeur, j’ai eu l’occasion de travailler sur plusieurs projets, et donc d’accumuler divers outils. Je me suis rapidement retrouvé confronté à un problème : j’ai plusieurs versions des mêmes outils installées sur ma machine. J'ai par exemple deux versions de PostgreSQL d’installées. Si je change de projet, je dois en désactiver une et activer l'autre. Cela me fait perdre du temps et je ne suis jamais sûr d'avoir tout bien désinstallé si je dois en supprimer une.
Disposer d'une base de données conteneurisée règle mon soucis : c’est simple à installer et à utiliser, et je suis sûr de tout supprimer à la destruction de mon conteneur !
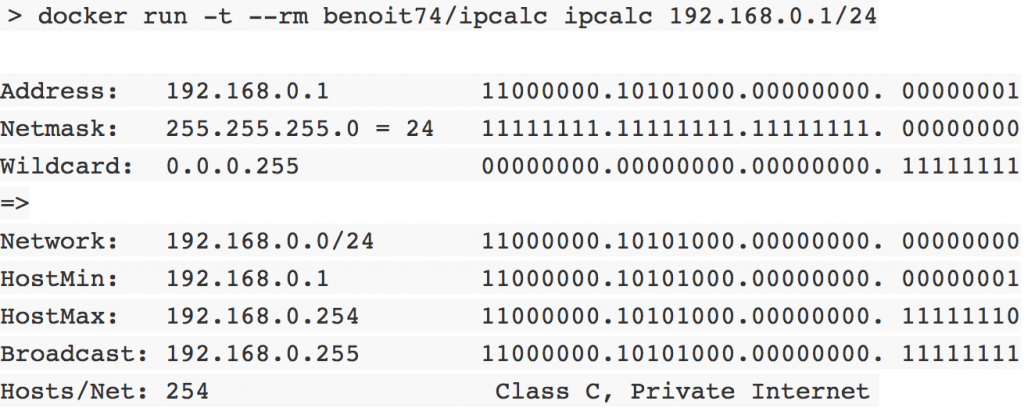
Prenons un exemple, je suis sur Mac et j’aurais bien aimé utiliser un outil sur Linux bien pratique : ipcalc. Avant, je me serais juste résigné et j’aurais cherché un outil similaire, mais avec un conteneur, je peux disposer de cet outil simplement !
L’un des avantages que j’ai découvert avec les conteneurs est celui de disposer de solutions “sur étagère”. En effet, il n’est pas pertinent de recoder une nouvelle solution à un problème déjà connu.
Il existe plusieurs endroits (on parle de registry), où trouver des images à partir desquelles instancier des conteneurs. Utilisant Docker, je suis allé sur https://hub.docker.com/ pour découvrir toutes les images disponibles et comment les utiliser. La plupart des images étant open-sources, on peut aussi contribuer à leur amélioration.
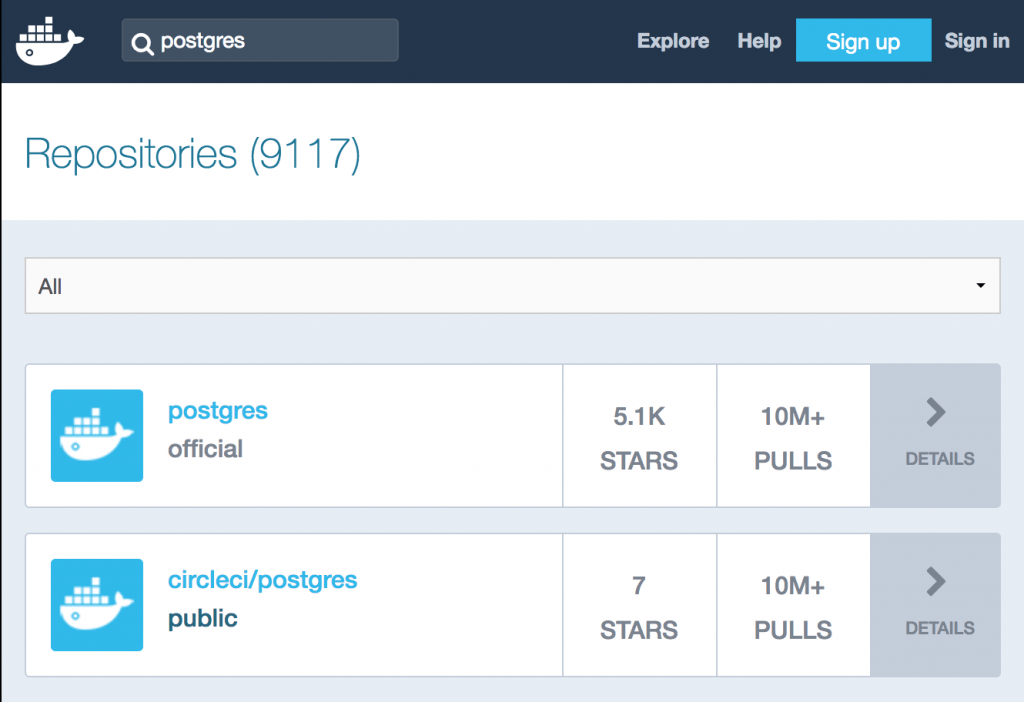
Des indicateurs permettent de faire un rapide tri pour choisir : le nombre d’étoiles (données par les utilisateurs), le nombre de téléchargements de l’image, les dates de mises à jour et du dernier téléchargement.
Attention tout de même : il reste important de vérifier le contenu des images à utiliser si l’on ne souhaite pas lancer des processus malveillants (backdoored docker images).
Mais comment faire quand on n’a pas envie de publier ses images publiquement sur Docker ? Pour ça, on peut créer soi-même sa registry à partir d’une image docker (exemple : https://docs.docker.com/registry/) et déployer ses images dessus.
Je peux travailler sur mes projets sans avoir peur de télécharger des packages inutiles lorsque j’ai un fichier à compiler, ou de télécharger un outil qui rentre en conflit avec des outils déjà existants sur ma machine. Il me suffit d’utiliser un conteneur et de le détruire à la fin pour laisser ma machine impeccable.
Je suis aussi plus à l’aise avec l’idée de faire des POCs, ou de tester de nouveaux outils, dans la mesure où je peux les installer dans un conteneur et supprimer ce dernier dès que je n’en ai plus besoin. C’est rapide - démarrer ou supprimer un conteneur ne prend que quelques secondes - et il me permet de simuler l’environnement exact sur lequel je souhaite travailler. Je peux aussi simplement simuler des appels à une base ou à une API. Si cela ne marche pas, il me suffit de quelques secondes pour détruire mon conteneur et en remonter un identique tout neuf !
Sur la plupart de mes projets, j’ai une application avec sa base de données et une API qu’elle consomme. J’aimerais pouvoir tester toutes ces interactions : cela reste faisable sur mon poste, mais sur une intégration continue, cela devient compliqué.
On l’a vu, Docker me permet de rapidement monter ma base de données. De la même manière, si j’ai la main sur l’API, je peux créer son image pour la lancer dans un conteneur. Je dispose ainsi en quelques secondes d’une API de test, utilisable en intégration continue. Si je n’ai pas la main sur cette dépendance, je peux toujours créer un mock de cette API et l'utiliser de la même manière.
Docker me permet rapidement et simplement de recréer la topologie de mon projet.
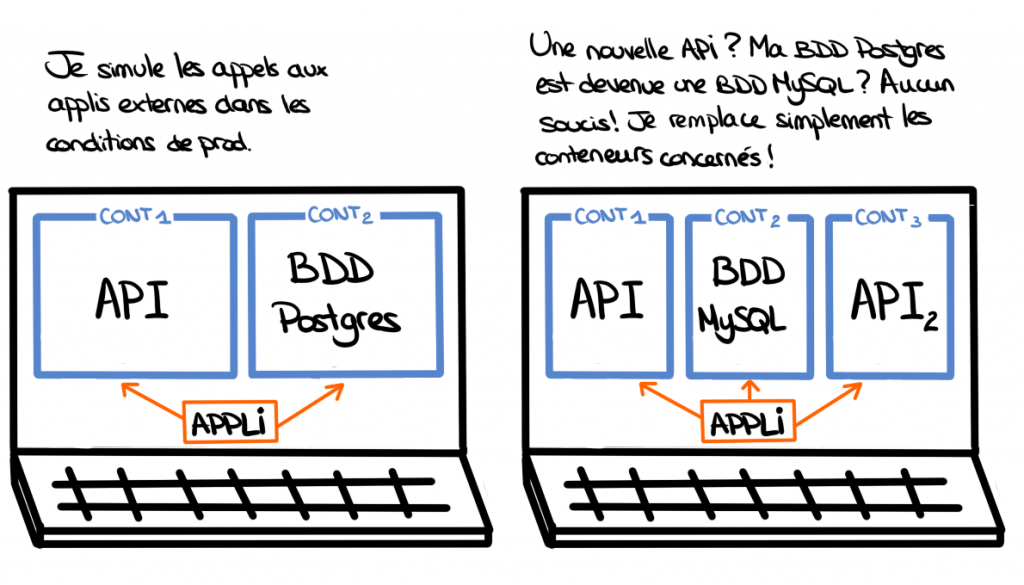
Jusqu’à présent, lorsque je voulais tester mon code dans un environnement similaire à celui de prod, je demandais au client de me fournir une VM. Cela pouvait prendre plusieurs semaines. Quelle perte de temps ! Et si je m’étais trompé et que j’avais besoin de détruire et de relancer une nouvelle VM, rebelote - et cela occasionne des frais supplémentaires.
Un conteneur me permet de faire tout cela sans avoir à passer par un intermédiaire, et de valider le fonctionnement de mon application et de ses dépendances. Il faut garder à l’esprit qu’une VM est plus longue à monter et à détruire qu’un conteneur car elle réserve une partie des ressources de la machine hôte à son lancement, alors qu’un conteneur ne consomme que ce dont il a besoin.
Dans l’ensemble, en tant que développeur, l’utilisation de conteneurs peut me faciliter la vie.
Attention cependant à ne pas se lancer tête baissée dans du Docker !
Enfin, il faut garder à l’esprit que Docker n’est qu’un outil parmi d’autres. On peut citer RKT (CoreOS), ou encore Windows Containers (Microsoft) par exemple. À vous de faire votre choix !