L’évolution du métier d’Ops suit un cheminement que nous observons régulièrement dans nos interventions. C’est au travers de cette fable, que nous allons voir les 4 étapes qui jalonnent ce chemin pavé d’embûches. Voyons pour cela comment un Ops procède concrètement pour effectuer l’opération « fix_mysql » qui consiste à changer une configuration de MySQL sur des serveurs de production.
Nombreux sont les administrateurs système qui ont une relation presque affective avec leurs machines. Sous le nom de «machines», vous pouvez tout aussi bien parler de serveurs physiques, de machines virtuelles (VMs), de stockage, d’équipements réseau.
Il est rassurant de connaître ses machines une par une, de faire le tour sur chacune d’entre elles le matin (ssh, consultation du dashboard munin machine par machine) comme un médecin fait la tournée des chambres en hôpital. Quand une machine tombe malade, nous sommes à son chevet, nous pratiquons des soins de façon héroïque, nous nous réunissons en comité pour examiner le traitement à prescrire. Bref, nous sommes aux petits soins.

_Violette, la reine du troupeau_Ce phénomène que l’on observe ici a un nom, nous l’appelons l’approche « Pet ». Vous avez l’impression d’avoir affaire à des animaux de compagnie que vous appelez par leur petit nom, chouchoutez, dorlotez, à qui vous mettez un petit nœud sur la tête pour éviter que ses poils ne retombent sur ses yeux. Vous prenez soin de vos machines avec tout le professionnalisme, l’empathie et l’humanité dont vous êtes capable. C’est ce qui vous rend bon, ce goût des choses bien faites, le soin porté aux détails pour que la machine « se sente bien » et que ses utilisateurs aient le service attendu. Vous êtes un artisan dont les chefs d’œuvre sont des serveurs et vos outils : un terminal, ssh, vi, tmux ou screen quelques scripts et des fichiers de configuration aux petits oignons.
Les organisations qui sont centrées sur ce comportement sont détectables dans leur propension à personnifier les machines, à faire des réunions dont l’objectif est de faire le ménage sur le serveur « daniela », à effectuer la montée de version du SGBD de acme-dc1-lnx-db001-prd, à planifier un week-end pour l’upgrade du kernel des machines du site B. Tout un poème.
Exemples de commandes pour fix_mysql, version premier âge :
# Connexion sur le premier serveur $ ssh amz@acme-dc1-lnx-db001-prd # Vérification des processus en exécution amz@acme-dc1-lnx-db001-prd ~> ps # Vérification de l’espace disque amz@acme-dc1-lnx-db001-prd ~> df -h # Édition du fichier de configuration de mysql amz@acme-dc1-lnx-db001-prd ~> sudo vim /etc/mysql/my.cnf # Redémarrage du service mysql amz@acme-dc1-lnx-db001-prd ~> sudo systemctl restart mysqld # Vérification des logs amz@acme-dc1-lnx-db001-prd ~> sudo tail -F /var/log/mysql.log # Déconnexion du premier serveur amz@acme-dc1-lnx-db001-prd ~> logout # Connexion sur le second serveur... $ ssh amz@acme-dc1-lnx-db002-prd amz@acme-dc1-lnx-db002-prd ~> sudo vim /etc/mysql/my.cnf amz@acme-dc1-lnx-db002-prd ~> sudo systemctl restart mysqld amz@acme-dc1-lnx-db002-prd ~> sudo tail -F /var/log/mysql.log amz@acme-dc1-lnx-db002-prd ~> logout # Connexion sur le troisième serveur (encore 17 à faire)... $ ssh amz@acme-dc1-lnx-db003-prd amz@acme-dc1-lnx-db003-prd ~> sudo vim /etc/mysql/my.cnf amz@acme-dc1-lnx-db002-prd ~> sudo systemctl restart mysqld amz@acme-dc1-lnx-db003-prd ~> sudo tail -F /var/log/mysql.log amz@acme-dc1-lnx-db003-prd ~> logout # longtemps plus tard...
Derrière ces signes cabalistiques se cachent un travail très manuel et répétitif sur chacun des serveurs, laborieusement. Dans de nombreuses étapes peuvent se glisser des erreurs et conduire à des environnements dysfonctionnels et / ou hétérogènes.
#### Premier âge : niveau de confort   | |
| #### Pourquoi ça marche<br><br>Mes serveurs n'ont pas besoin d'être mis à jour souvent<br><br>Peu d'applications à gérer<br><br>Peu de déploiements<br><br>Petit nombre de machines | #### Pourquoi ça ne marche pas<br><br>Il faut livrer de nouvelles versions des applis plus d'une fois par mois<br><br>Je gère plus de X machines<br><br>Je gère plus de Y applications<br><br>Je pars en vacances ou tombe malade |
Avec l’arrivée de la virtualisation, la donne change. Nous avons tendance à utiliser de nombreuses VMs. Vraiment beaucoup. Tellement que les connaître toutes par leur nom devient quasiment impossible. Comment faire donc pour conserver une capacité à s’occuper avec amour et dévouement de tant de machines ?
En outre, les VMs sont gérées comme des serveurs physiques (créées au début du projet, supprimées à la fin), les phases de ménages ne sont pas fréquentes. Et il faut bien le reconnaître, la suppression des VMs n’est pas franchement une priorité. On fera ça quand on aura le temps ou quand l’hyperviseur sera plein.
L’approche « Pet » est mise à mal. Les tâches systématiques effectuées par centaines paraissent vides de sens, en plus d’être franchement fastidieuses. Vous ne pouvez pas tenir un tel rythme durablement, la surchauffe vous guette.
Vous vous lancez dans des mesures diverses et variées : création de snapshots / clones pour dupliquer les machines, vous ne jurez plus que par votre golden-image. Pour les réglages spécifiques, à chaque machine, ça reste un enfer.
Exemples de commandes pour fix_mysql, version second âge :
# Belle boucle en shell $ machines=”001:16M 002:32M 003:16M 004:32M 005:32M ...” # passage sur toutes les machines en un coup, j’ai testé sur une machine, ça a l’air de fonctionner... $ for m in $machines; do IFS=: read machine_number mem <<< $m ssh -tt amz@acme-dc1-lnx-db$machine_number-prd -- “sudo sed -ie 's/.*key_buffer_size.*/key_buffer_size=$mem/' /etc/mysql/my.cnf && sudo systemctl restart mysqld” done
Dans cet exemple, vous commencez à écrire des bouts d’automatisation pour passer sur toutes les machines. Peu de contrôle, de forts risques de loupés, vous aimez vivre dangereusement… Mais après tout, vos scripts et vos one-liners, vous les connaissez par cœur, peu importe si personne n’y comprend rien.
| #### Second âge : niveau de confort | |
| #### Pourquoi ça marche<br><br>Mes images m’assurent que ce qui a fonctionné hier continuera de fonctionner demain | #### Pourquoi ça ne marche pas<br><br>Parfois j’oublie de backporter le patch X de la prod vers une image.<br><br>Il y a tellement d’images qu’on finit par toujours prendre la dernière en date, et on espère qu’elle est la plus à jour.<br><br>Déployer sans downtime est difficile : mes images mettent du temps à booter, il faut les surveiller comme le lait sur le feu, et je dois mettre à jour la configuration de mes loadbalancer à la main.<br><br>Mes shells sont parfois un peu instables et compliqués à maintenir |
L’automatisation s’impose alors comme une évidence. Suite à l’incompréhension de vos collègues à comprendre vos scripts maison, vous vous lancez dans un outil, un vrai.
Il existe de nos jours tant d’outils d’automatisation qu’il peut même être difficile de choisir, mais là n’est pas la question. Grâce à eux, les installations / configurations / déploiements sont grandement facilités, à très large échelle. Vous vous sentez tomber inéluctablement dans l’approche « Cattle ». Cette gestion industrielle et bestiale d’une palanquée de machines toutes identiques, sans personnalité vous donne plus l’impression de gérer la ferme aux 1 000 vaches qu’une petite exploitation de 20 brebis sur les contreforts de la Banne d’Ordanche à Murat-le-Quaire. 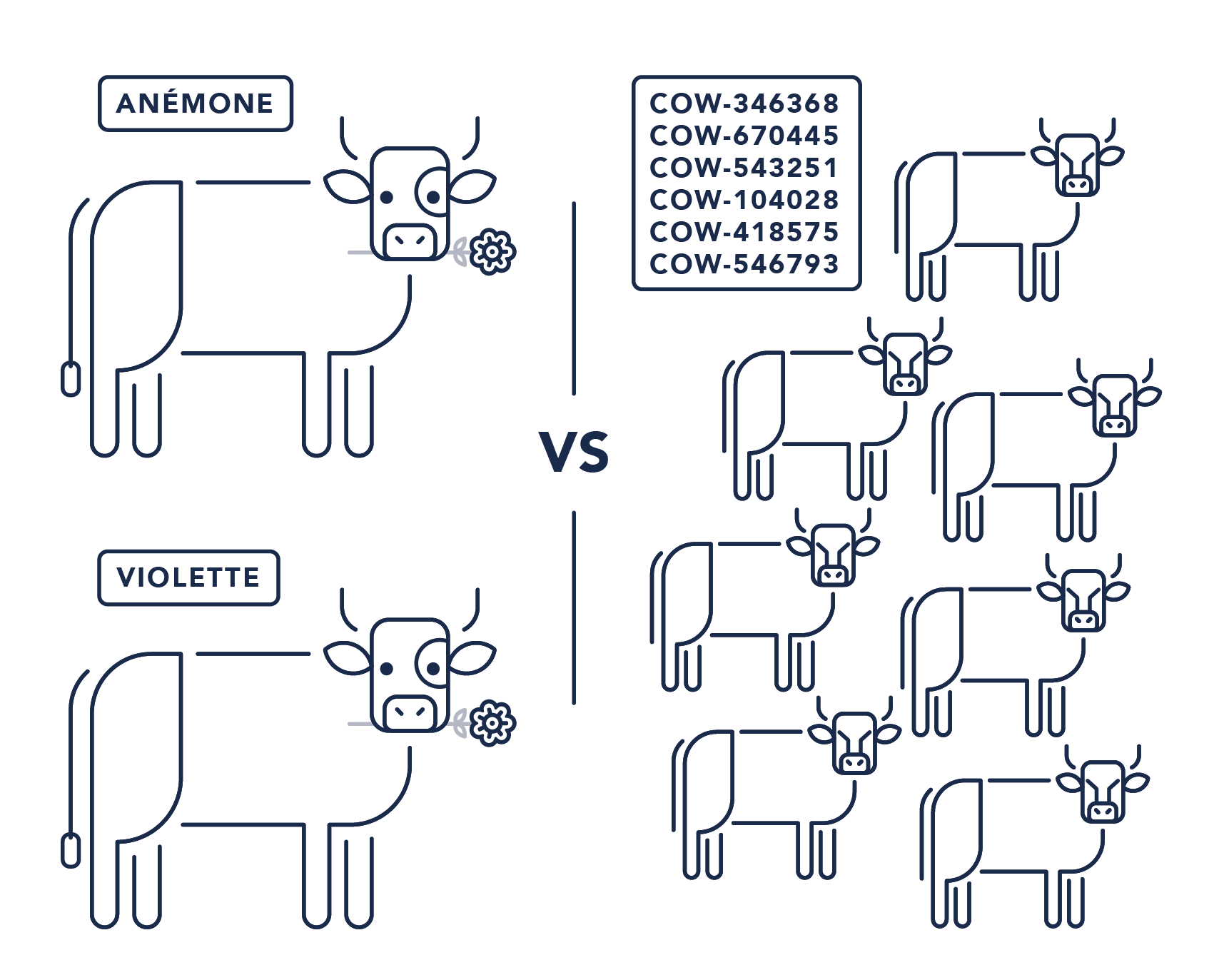
Et que dire d’une pratique aussi sauvage qu’inhumaine que le blue-green deployment ? Cela consiste à effectuer des montées de version en créant des VMs avec la nouvelle version de l’application, de faire une bascule sur le load-balancer avant de détruire les anciennes VMs. De qui se moque-t-on ?
Il faut bien se rendre à l’évidence pourtant. Cette approche est diablement efficace. Les tâches manuelles et fastidieuses se réduisent, une partie des loupés dûs à des configurations hétérogènes disparaissent. Du temps est gagné et il est possible de gérer de façon plus facile des centaines voire des milliers de machines. L’automate devient votre bras armé, c’est lui qui, par construction, effectue laborieusement toutes ces opérations répétitives que vous avez codées. Seul petit hic, quand vous lui demandez de faire une bêtise, il la fait avec obéissance, sur 1000 machines d’un coup...

Ces questions commencent à s’accumuler dans votre tête. Vous devenez propriétaire par la même occasion d’un petit patrimoine de code qui décrit votre infrastructure et qui commence à s’accumuler discrètement…
fix_mysql, version troisième âge :
# Édition du template Ansible de configuration de MySQL $ vim roles/mysql/templates/my.cnf # Édition du rôle Ansible MySQL $ vim roles/mysql/tasks/main.yml # Lancement en mode dry-run pour vérifier les changements à faire sur tous les serveurs de base de données de prod $ ansible-playbook -i inv/prod -l db-servers configure.yml --check --diff # Vrai lancement sur la plateforme sur tous les serveurs de base de données de prod $ ansible-playbook -i inv/prod -l db-servers configure.yml --diff -vvv # Oups, après une vérification manuelle, il faut repasser sur tous les serveurs pour corriger notre bêtise... $ vim roles/mysql/templates/my.cnf # Lancement sur la plateforme sur tous les serveurs de base de données de prod $ ansible-playbook -i inv/prod -l db-servers configure.yml --diff -vvv # Ouf, c’est réparé, personne n’a rien vu...
Dans cet exemple, un outil (Ansible, un choix parmi tant d’autres) permet de déployer un changement de configuration sur tous les serveurs de base de données. Comme il n’y a pas de garde-fou, si on fait une coquille, celle-ci se déploie sagement sur toutes les machines concernées. Reste alors à vite repasser derrière pour réparer…
| #### Troisième âge : niveau de confort | |
| #### Pourquoi ça marche<br><br>Comme avec les golden images : ce qui a fonctionné hier continuera de fonctionner demain.<br><br>Un rolling update revient à paramétrer des valeurs dans mon code.<br><br>Le code représente “la vérité” de ce qui est censé se passer en production, tout le monde peut s’y référer pour prendre une décision. | #### Pourquoi ça ne marche pas<br><br>Je n'écris pas de tests : j'ai du code mais je ne sais pas si il fonctionne à un instant T.<br><br>Je n'ai pas confiance dans l'idempotence de mon code et donc je ne peux pas l'appliquer en prod pour la réparer.<br><br>Je modifie à la main les machines dans le dos de mon automate et il casse tout en repassant |
Concernant la gestion du code que vous donnez à votre automate, une transformation s’opère et elle pourrait être la voie du salut. En allant voir ce qu’il se fait du côté des développeurs d’applications, vous vous rendez compte que c’est un nouveau monde parfois mal-connu qui s’ouvre à vous.

Les développeurs ont donc mis au point tout un écosystème d’outils et de pratiques pour faire leur boulot.
En discutant avec eux, vous vous rendez compte qu’ils ont fait ça car ils aspirent à quelque chose qui résonne délicieusement en vous. Ils aiment faire du travail de qualité, rendre leur code beau, expressif, maintenable, bref, être aux petits soins avec lui… Ils ont même un terme pour ça : le software craftsmanship ou l’artisanat du logiciel.
Version quatrième âge de fix_mysql :
# Bascule sur la branche master pour récupérer la dernière version du code $ git checkout master # Mise à jour par rapport au référentiel $ git pull --rebase # Création d’une branche pour la correction $ git checkout -b amz # Recréation d’une plateforme de dev from scratch $ ansible-playbook -i inv/amz vm-reinit.yml # Lancement sur une plateforme de dev $ ansible-playbook -i inv/amz -l db-servers configure.yml --diff -vvv # Édition du test serverspec MySQL pour vérifier la nouvelle caractéristique attendue $ vim tests/spec/nodetypes/db/mysql_spec.rb # Vérification que le test est bien faux $ ENV=amz rake -f tests/Rakefile spec:mysql # Édition du template ansible de configuration de MySQL $ vim roles/mysql/templates/my.cnf.j2 # Édition du rôle Ansible MySQL $ vim roles/mysql/tasks/main.yml # Vérification de la syntaxe du rôle Ansible MySQL $ ansible-lint roles/mysql [ANSIBLE0012] Commands should not change things if nothing needs doing /home/amz/projets/trucs/infra-as-code/roles/mysql/tasks/main.yml:17 Task/Handler: Ch{mod,own} file # Oups, j’ai fait une coquille, ansible-lint l’a attrapé avant que je lance la commande $ vim roles/mysql/tasks/main.yml # Vérification de la syntaxe du rôle Ansible MySQL $ ansible-lint roles/mysql # Cette fois, c’est bon, lancement sur une plateforme de dev en dry-run $ ansible-playbook -i inv/amz -l db-servers configure.yml --check --diff # Lancement sur une plateforme de dev $ ansible-playbook -i inv/amz -l db-servers configure.yml --diff -vvv # Lancement des tests qui doivent passer au vert $ ENV=amz rake -f tests/Rakefile spec:mysql # Vérification des fichiers modifiés $ git status # Ajout des fichiers modifiés au prochain commit Git $ git add tests/spec/nodetypes/db/mysql_spec.rb roles/mysql/templates/my.cnf.j2 roles/mysql/tasks/main.yml # Commit git en référence au ticket $ git commit -m “#678 ajout de la gestion des key_buffer_size” # Pousse dans la branche pour faire une merge-request + pair review # La plateforme d’intégration continue se charge du reste $ git push origin amz # Purge de la plateforme temporaire de dev $ ansible-playbook -i inv/amz vm-destroy.yml
Dans cet exemple, l’écriture du code Ansible est étayée par un analyseur de bonnes pratiques de codage (ansible-lint) et des tests (en serverspec) qui sont écrits (si possible) avant l’implémentation. La capacité à disposer d’environnements jetables à la demande (via test-kitchen ou toute autre solution) permet de valider les changements sur un environnement anté-prod. La stratégie de branche et de code-review participe à la qualité et au partage du référentiel de code. C’est notamment l’occasion de faire relire le code et le paramétrage à un petit nouveau sur le projet ou un DBA qui vérifiera le paramétrage. Une plateforme d’intégration continue se charge de repasser tous les tests et un mécanisme de promotion (manuelle ou automatique) envoie les changements en production.
| #### Quatrième âge : niveau de confort | |
| #### Pourquoi ça marche<br><br>Il y a plusieurs niveaux de tests qui contribuent chacun à la qualité du code.<br><br>Je profite du versionning du SCM pour versionner toute mon infra. | #### Pourquoi ça ne marche pas<br><br>Non, stop, ça marche. |
L’outil de déploiement devient donc pour les sysadmins/devops une sorte de chien de berger. C’est finalement lui qui devient le nouvel animal de compagnie, celui dont vous avez besoin et dont vous prenez le plus grand soin. Celui dont chaque ligne de code est écrite avec amour, avec toute la qualité possible puisque c’est lui qui vous permet de manipuler un tel parcs de serveurs et d’applications.
La transformation du métier d’ops n’est finalement pas une remise en question des valeurs de ce métier. C’est plutôt un changement de l’objet de son attention. Au lieu de s’attacher aux machines, il s’agit de s’attacher à l’automate (et au code qui le pilote) qui les fait vivre, en conservant le même goût du travail bien fait, celui qui donne envie de se lever tous les matins.

Et demain ?
Vous êtes fiers de votre travail, pourtant déjà se présentent devant vous de nouveaux défis : cloud (IaaS, auto-scalling, PaaS), conteneurisation (Swarm, Kubernetes...), Clusters applicatifs (MongoDB, Cassandra, Kafka, Spark...)… La différence ? Des durée de vie des conteneurs encore plus courtes, un mécanisme de cluster qui participe à la vie du cheptel. Finalement, peu importe, vous avez mis en œuvre toutes les bonnes pratiques vous préparant aux changements (d’outils et de technologies).