Il existe au sein des systèmes d'information des indicateurs qui permettent d'anticiper les problèmes et dysfonctionnements en production afin d'éviter les coupures de service pour les utilisateurs : le log (message horodaté).
Lors de l'exploitation des solutions informatiques, le log est souvent négligé alors qu'il apporte une vraie valeur pour les exploitants (que nous appellerons ici OPS), les développeurs (que nous appellerons ici DEV) et les personnes du métier.
Si vous avez répondu oui à l’une de ces question ou si vous êtes curieux, vous êtes au bon endroit !
Imaginons l'infrastructure suivante :
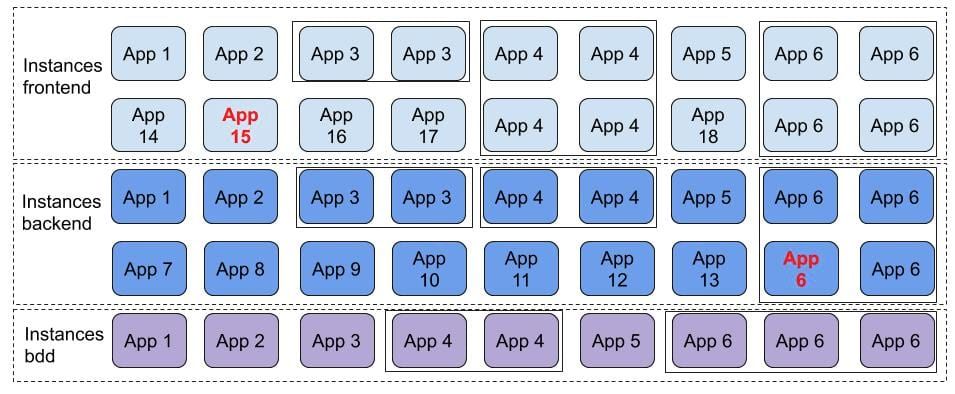
Dans ce schéma, les applications App 15 et App 6 produisent des logs d'erreurs.
Malheureusement l'équipe d'exploitation ne remarque pas ces messages d'erreurs. En effet, n’ayant pas le temps de scruter tous les logs des serveurs un à un, l’équipe d’exploitation a pris la mauvaise habitude de regarder les logs qu’une fois qu’un événement survient en production.
Avec la centralisation des logs, l'équipe d'OPS aurait constaté que des erreurs se produisent périodiquement et de plus en plus fréquemment. Par conséquent, les OPS auraient donc pu mettre en place des solutions pour éviter une coupure de service en production.
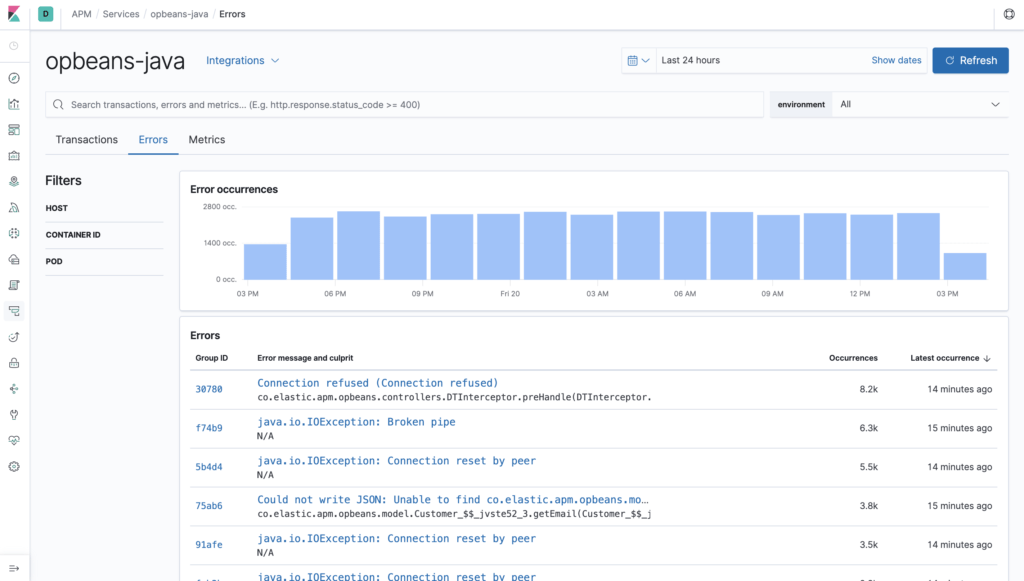
https://www.elastic.co/guide/en/kibana/current/errors.html
Sur l'exemple ci-dessus, on constate qu'il se produit beaucoup d'erreurs “java.io.IOException: Connection reset by peer” ce qui révèle un service remote utilisé par une application inopérante (si l'application appelante n'a pas implémenté de circuit breaker, il y a une très forte probabilité qu'elle soit défaillante elle aussi).
Aussi, après cet incident, l'équipe de développement a exprimé le besoin d'accéder aux logs de la machine pour comprendre et corriger les dysfonctionnements applicatifs.
Malheureusement, l'incident s'étant produit en production, les DEV n'ont pas accès aux machines concernées par souci de sécurité et de “stabilité” .
Pour y avoir accès, ils ont dû écrire un ticket à l'équipe d'exploitation pour que ceux-ci leurs envoient le log dont ils ont besoin (“c'est la procédure…”).
Par manque de "chance", l'OPS n'a pas envoyé la liste de logs contenant l'information permettant de corriger l'incident. On ne peut pas lui en vouloir puisqu’il ne connaît pas vraiment l'application et ne sait pas quoi rechercher exactement.
Encore une demande par ticket et hop ! le DEV a enfin son message d'erreur complet.
Bilan de l'opération : 2 jours pour avoir l'information permettant de corriger l'incident et donc autant de jours de décalage pour corriger l'incident de production. Bref, un processus d'investigation compartimenté et lourd ne permettant pas un TTR (Time To Repair) optimal.
Les outils permettant de faire de la centralisation de logs donnent tous un moyen d'accéder aux logs sans avoir à se connecter à la machine (j'expliquerai cela dans la suite de l'article) contenant le log source. Donner l'accès à ce moyen de visualisation aux développeurs permet de faire gagner du temps aux deux équipes (DEV et OPS) :
Établir un diagnostic sur un problème qui survient sur une application distribuée utilisant un lot important de services peut s'avérer compliqué.
La plupart du temps, on investigue en regardant les logs de l'application en erreur. Si l'erreur vient d'un service qui est utilisé par l'application alors on se connecte sur le service en question pour voir ses logs et ainsi de suite. Pour peu que l'architecture soit très distribuée, trouver la root cause peut s'avérer peu trivial. Pour peu que l’on se soit aperçu de l'erreur trop tard et qu'il y ait une rotation des logs un peu trop agressive, le message de log serait perdu et il faudrait attendre une nouvelle erreur pour pouvoir investiguer en détail.
Avec la centralisation des logs, il est possible de diagnostiquer plus simplement les erreurs : les logs de toutes les applications sont centralisés au même endroit, découplés des vrais logs (la recherche ne se fait pas sur les logs de l’application mais sur une copie) et visibles sur une seule et même interface.
Ces interfaces de visualisation ont pour la plupart des moteurs de recherche qui permettent de rechercher un log en fonction d'une date, d'un pattern ou d’un mot clé.
Il est donc possible de ressortir les logs répondant aux questions suivantes :
En utilisant un tel moteur de recherche, il est assez simple de naviguer à travers les logs de son SI et de déterminer la root cause d'un problème applicatif.
NB: Le format des logs ainsi que la manière de faire cela techniquement sera abordé dans un article ultérieur.
En complément des outils classiques permettant d'avoir une surveillance de son système (tels que Nagios ou Zabbix), la centralisation des logs permet d'avoir une vue sur l'état de santé de son système et de mettre en place des indicateurs sur l'utilisation de ses services ou interfaces web.
Sans entrer dans le détail des dashboards, le fait de centraliser les logs permet par la suite de mettre en place tout un ensemble de graphes permettant de voir à un instant t ce qu'il se passe au sein de son SI.
Ainsi un OPS pourrait avoir un écran contenant un graphe des applications down avec un tableau contenant par exemple :
Cet ensemble d'indicateurs permet d'anticiper les futurs problèmes de production. Grâce à l'aide de ces écrans, il est beaucoup plus facile de détecter les futurs problèmes tels que les fuites mémoire par exemple (l'indicateur de mémoire étant tracé au sein de l'outil et visible via les dashboards associés).
Maintenant imaginons que nous avons une API REST dans notre système mais comme cette API est noyée dans les diverses autres API, nous n'avons pas de visibilité sur la volumétrie d'appels sur les différentes ressources.
A l'aide de la centralisation de logs, il suffit d'écrire un message de log dès qu'un appel est fait sur une ressource en incluant également les paramètres entrants (saufs données sensibles comme les mots de passe bien sur ;-) ), les données sortantes et le code http de retour.
Avec ces informations, nous pouvons donc :
Cela permet par la suite de piloter l'évolution de l'API (refactoring, décommissionnement, nouvelle ressource, etc.).
J'ai pris l'exemple d'une API REST mais il est tout à fait possible de faire la même chose sur toutes les applications à partir du moment où vous avez la main sur le développement de celle-ci.
Ce qui est intéressant avec la centralisation des logs, c'est qu'il n’y a rien à ajouter techniquement au sein de l'application en elle même car les logs sont la plupart du temps déjà intégrés au sein des solutions logicielles (si vous n'avez pas de logs dans vos applications alors vous savez par où commencer). Pour piloter vos applications, il suffit d’ajouter les bons messages aux bons endroits.
"Ok mais quel est le bon endroit ?" vous allez me dire.
Et je vous répondrais que cela dépend de vos applications. En règle générale, logger les entrées sorties des applications est déjà révélateur de nombreuses informations et suffit à avoir une vue de l'utilisation des applications. Cependant à vous de voir au sein de votre application quelles informations vous voulez voir remonter.
Comme je l'ai écrit précédemment, ajouter des logs au sein d'une application est peu coûteux en terme de développement pur.
La centralisation des logs ayant les messages de toutes les applications du SI, qu'est ce qui empêcherait d'effectuer un suivi des informations métier ?
Par exemple prenons le cas d'une application de gestion de commande qui aurait l'architecture suivante :
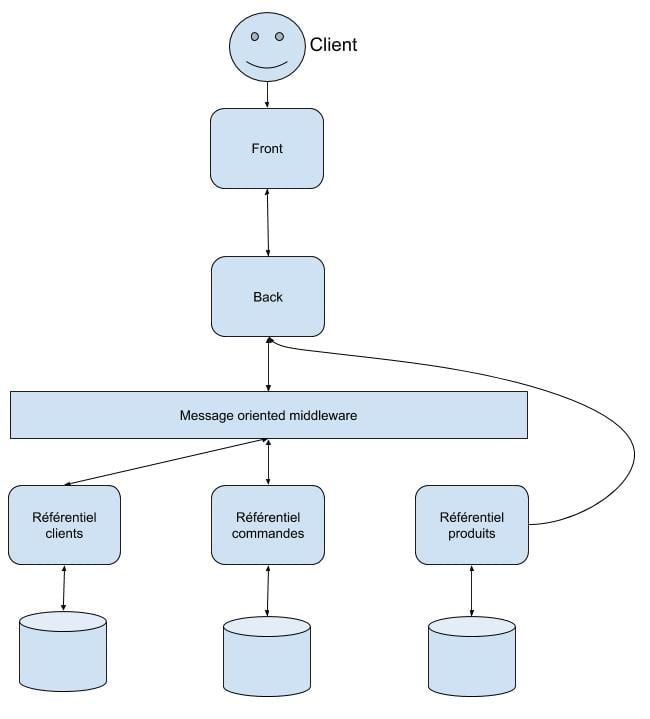
Monsieur Jean Dupont n'a pas de compte sur l'application et souhaite effectuer une commande. L'interface de l'application permet d'effectuer une commande sans avoir de compte. Les informations sur les produits sont récupérées d'un référentiel externe et pour finir tout passe un MOM (Message Oriented Middleware).
NDLR : oui je sais cette architecture n'est pas vraiment optimale pour ce type de besoin mais c'est pour l'exemple :-)
Lors de la commande, il y a donc deux informations mémorisées dans les référentiels :
Une fois que Monsieur Dupont a validé sa commande, il reçoit un beau message d'erreur lui indiquant que sa commande n'a pas pu être traitée.
Monsieur Dupont frustré, annule sa commande et se tourne vers un autre site marchand.
Après investigation, l'équipe d'exploitation se rend compte que les informations sur le client sont présentes dans le référentiel clients mais qu’il n'y a pas de commande dans le référentiel commandes (rien ne persiste dans le référentiel produits car ce n'est que de la lecture) :
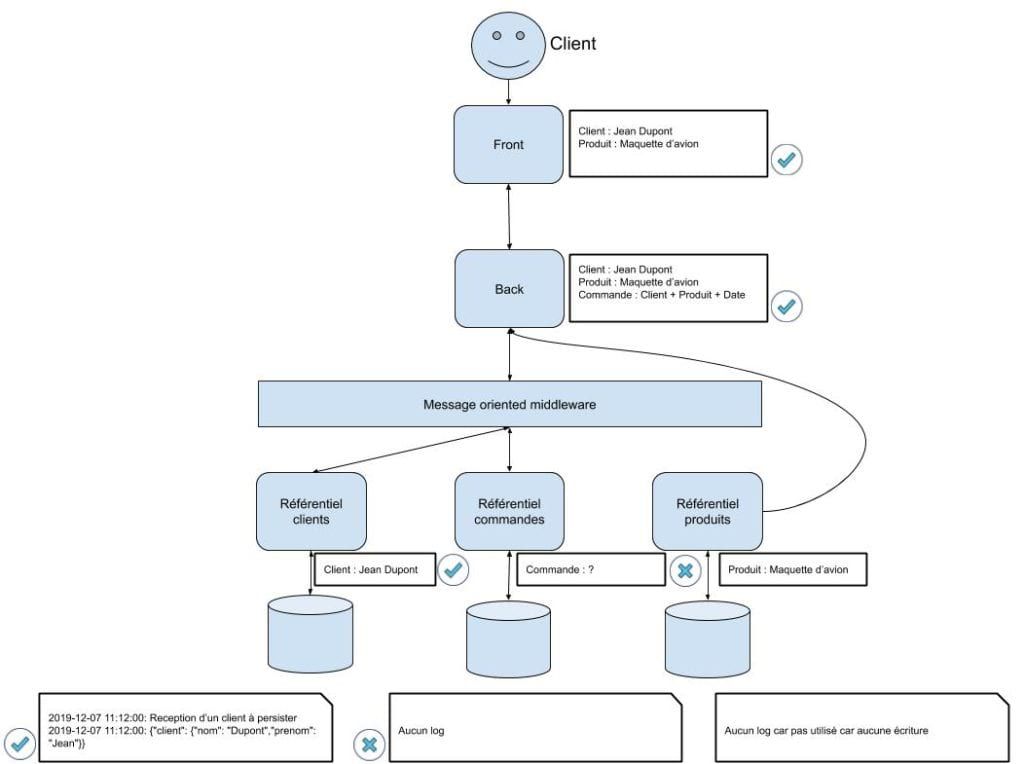
En regardant les logs applicatifs, on s’aperçoit que :
Il y a donc un problème du côté du MOM :
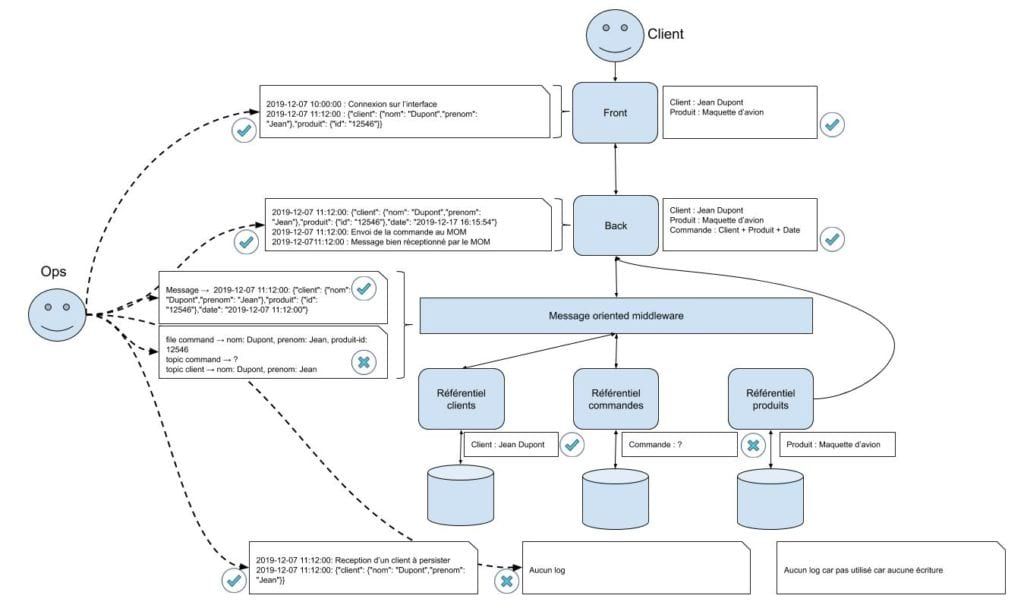
Ceci est un exemple très simple. Cependant au sein d'un SI complexe, diagnostiquer et déterminer là où l'information se perd peut s’avérer beaucoup plus difficile et chronophage.
Avec la centralisation de logs, il est possible de mettre en place des indicateurs permettant de compter le nombre d’occurrences données d'un élément. Si on reprend l'exemple de la commande, on pourrait mettre en place des KPI en se basant sur les logs comme le temps qu'un client met entre la connexion et la commande, le nombre de commandes par jours, combien de nouveaux clients par jour, etc.
Le schéma ci-après représente l'architecture avec la solution de logs intégrée au système :
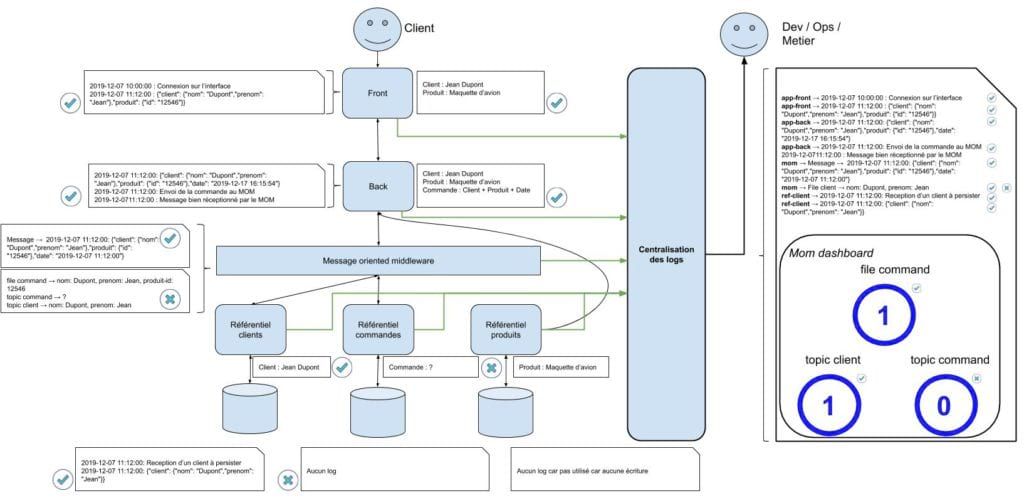
Avoir une vue centralisée de ses logs c'est bien. Cependant, on ne peut pas être en permanence connecté sur l'outil pour visualiser l'état ou les métriques de son système d'information.
Pour pallier à cela, il existe des solutions de notification qui permettent d'être informé. Par exemple en cas de gros volumes entrants, ou alors quand il y a beaucoup d'erreurs 503 sur une ressource ou encore quand un utilisateur se connecte de plusieurs endroits.
Les notifications se déclenchant en fonction de seuils, il est très facile d'être informé de beaucoup d'événements au sein du système (attention à ne pas vous noyer sous les notifications, ce qui aura pour effet que plus personne ne traite ces notifications (syndrome de la boîte mail avec les 1000 messages non lus).
Il n'y a pas de “bonne pratique”, chaque système étant différent c'est à vous de déterminer avec vos équipes quels sont les indicateurs qui nécessitent la mise en place de notifications.
Les canaux d'informations peuvent être différents selon les solutions. Sur certaines, les notifications ne se font que par email, pour d'autres c’est peut être par chat (slack par exemple) ou webhook…
Se doter d'un outil de centralisation de logs peut sembler être dans un premier temps un outil superflu et non prioritaire à mettre en place dans un système complexe. Néanmoins, il s'avère incroyablement efficace dans une utilisation quotidienne.
De plus, avec des pratiques de développement homogénéisées au sein des équipes, le coût de mise en place d'indicateurs et de monitoring des applications devient très faible.
Avant de vous lancer dans la mise en place d'un tel outil, posez-vous ces questions :
Si vous avez répondu oui à l'ensemble de ces questions alors vous n'avez pas forcément besoin d'une telle solution.
Dans le cas contraire, vous avez une idée de piste de progrès ;-)