No artigo “Deploy Contínuo”, vimos como melhorar o Time to Market sem impactar a qualidade do desenvolvimento.
O passo seguinte é assegurar a disponibilidade do site ou aplicativo apesar desses deploys freqüentes. O Zero Downtime Deployment (“Deploy sem interrupção”) é uma estratégia que visa fazer um deploy sem interromper o funcionamento do aplicativo a fim que a troca fique transparente para os usuários.
Como colocar novas versões do aplicativo em produção sem impactar a experiência dos usuários?
A aplicação do Zero Downtime Deployment é baseado em alguns padrões e boas práticas.
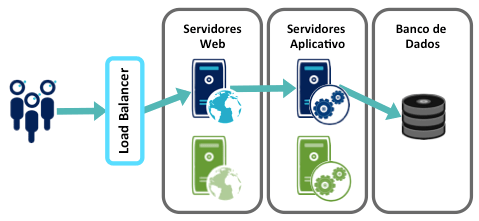
O Blue/Green Deployment é o padrão clássico do Zero Downtime Deployment. Ele assume que o aplicativo fica em produção em, pelo menos, dois conjuntos de maquinas. O objetivo é o de subir a versão N+1 num conjunto (verde aqui abaixo) enquanto o serviço é mantido num outro conjunto (azul) na versão N.
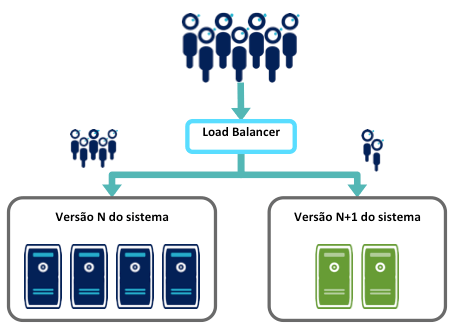
Esse padrão combinado com o Blue/Green Deployment permite de confrontar a versão N+1 com uma população limitada de usuários enquanto a maioria dos usuários usam a versão N. Os mecanismos envolvidos são os mesmos que para o Blue/Green Deployment.
Esse padrão é usado pelo Facebook, onde os seus funcionários utilizam a nova versão do site durante um dia antes de deixar accessível para todos os usuários caso tudo esteja correto.
Esse padrão permite colocar em produção de maneira invisível uma funcionalidade para simular progressivamente um teste de carga com o tráfego que existirá na utilização real.
O objetivo desse padrão é de validar as performances e a escalabilidade da plataforma. Simulando de maneira progressiva o tráfego esperado ajuda para preparar e otimizar os sistemas para que ocorra tudo bem durante o lançamento da funcionalidade no dia D.
O objetivo é combinar o mecanismo de distribuição de carga (Load Balancing) com o processo de deploy:
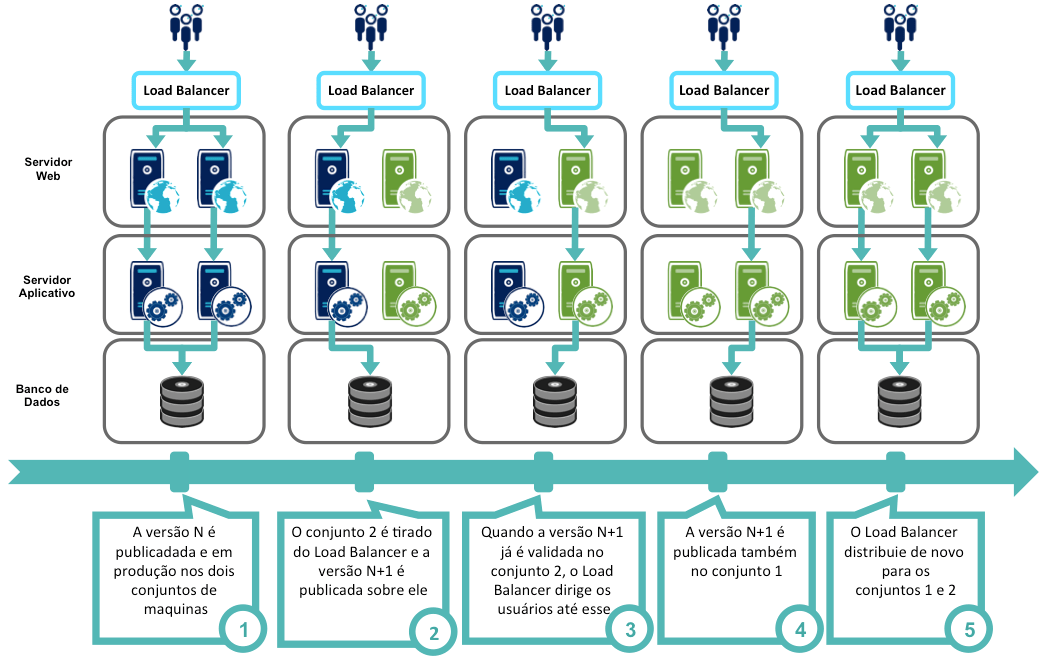
Existe dois pontos de atenção nesse conceito de Zero Downtime Deployment. O primeiro trata das sessões usuários, e o segundo é as mudanças de modelo de dado.
Há duas maneiras de gerar as sessões usuários quando distribuamos a carga entre vários servidores aplicativos:
Afinidade de sessão
O mecanismo é o seguinte:
Esse mecanismo traz alguns problemas com o Blue/Green Deployment, porque os usuários que têm uma sessão num servidor saindo da distribuição de carga vão perder as suas sessões e precisarão fazer o login novamente.
Sessões compartilhadas
No caso de os servidores de aplicação compartilharem o mesmo cache de sessões, os usuários não estarão ligados com um conjunto de maquinas específico.
Essa maneira de gerar as sessões é obviamente ideal para aplicar o Blue/Green Deployment pois tirar um servidor não impacta os usuários.
Esse tipo de mecanismo é o padrão dos principais servidores de aplicação do mercado (Tomcat Cluster, WebSphere ND, etc). Para evitar a adesão com um produto, é possível implementar os seus próprios mecanismos utilizando ferramentas de cache de memória distribuído como memcached ou CouchDB.
No processo de deploy com a estratégia Blue/Green Deployment, um possível problema é o fato de a versão N+1 da aplicação impor mudanças no modelo de dados:
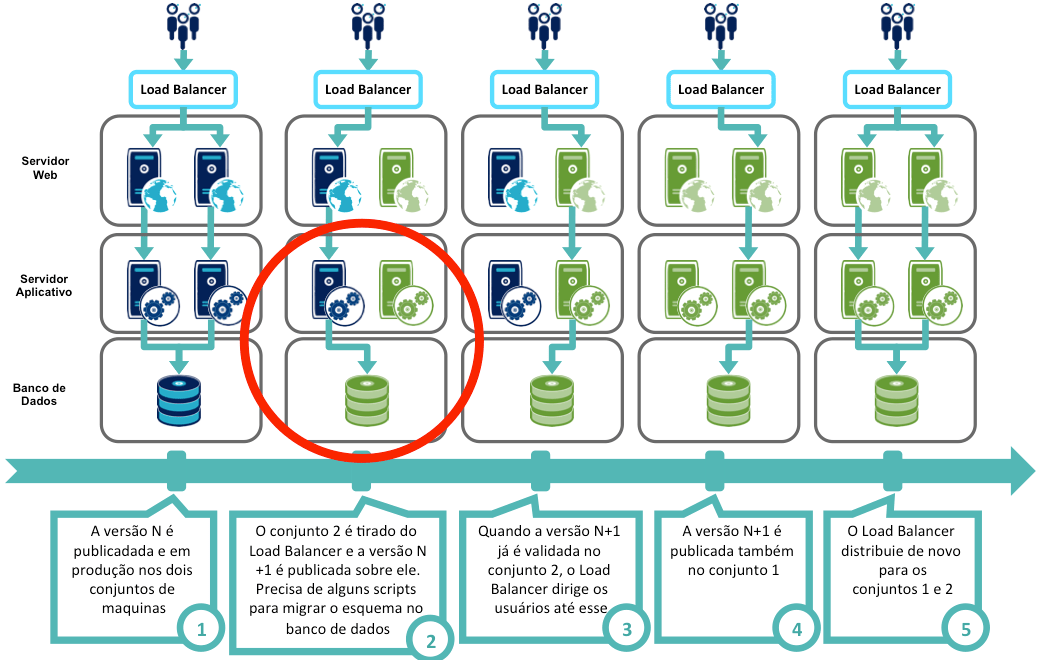
Tal problema aparece no segundo passo: o código do aplicativo na versão N é incompatível com o modelo de dados da versão N+1. Como assegurar que a versão N funcionará com a versão N+1 do modelo de dados?
A palavra chave é antecipação, tanto no lado do banco de dados quanto do código da aplicação:
Não entendeu? Segue um exemplo com uma tabela!
Historicamente, nossa aplicação utilizava somente um campo único para guardar o endereço do usuário na tabela Pessoa:

Isso não é o ideal para várias razões. Por isso, criaremos uma nova tabela Endereço para guardar os diferentes elementos de um endereço
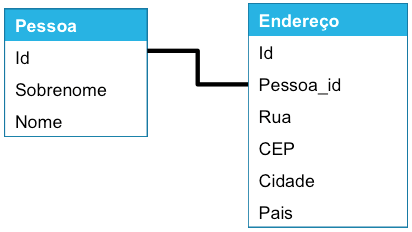
Na realidade, essa migração será feita em dois tempos, usando temporariamente um esquema de transição para assegurar o rollback se um problema surgir:
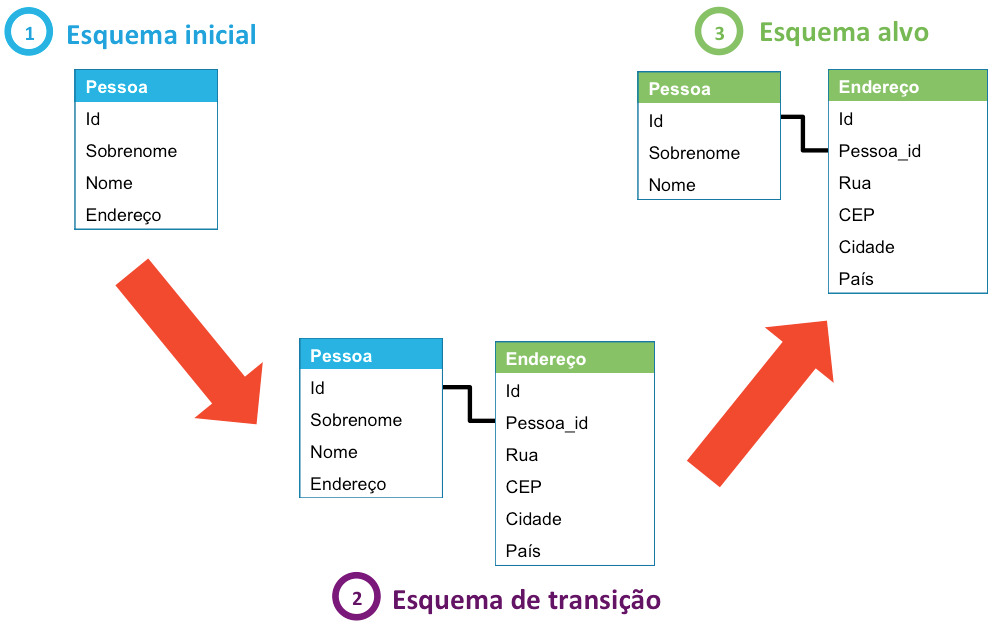
Para tornar possível essa migração de esquema, três scripts SQL são necessários:
O código aplicativo deve:
○ Ex: durante o período de transição, o código deve atualizar o endereço nas duas tabelas Pessoa e Endereço;
○ Para os casos simples (sincronisar duas colunas), podemos também usar os triggers.
Para o código ser capaz de usar as diferentes versões do esquema do banco de dados, a melhor solução é de implementar o Feature Flipping, usando um parâmetro para escolha de qual versão do esquema deve-se utilizar:
schema.mode=[ORIGINAL,TRANSITIONAL]
Sobre a consistência dos dados, o código deve simplemente escrever nas duas tabelas Pessoa e Endereço, idealmente em uma transação única.
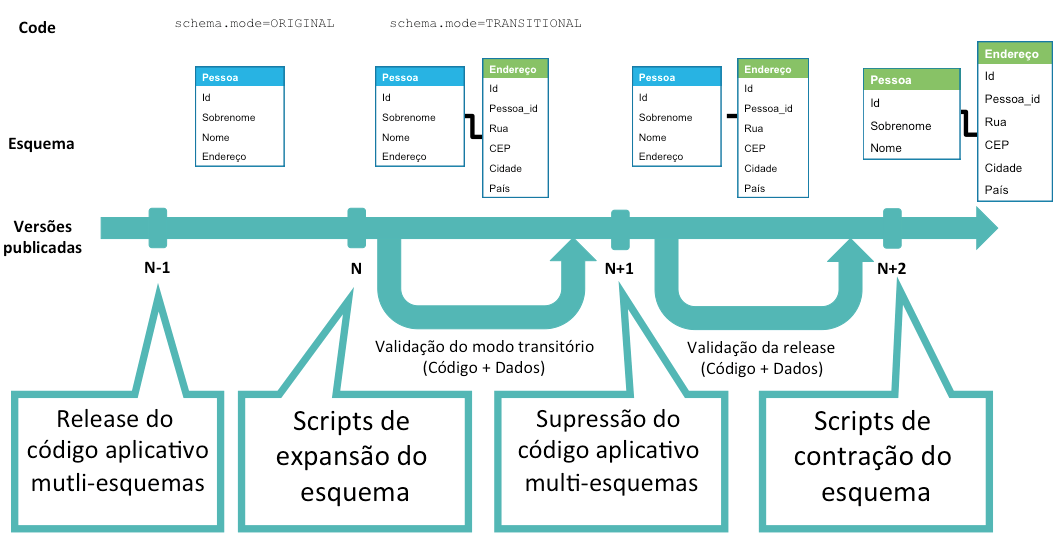
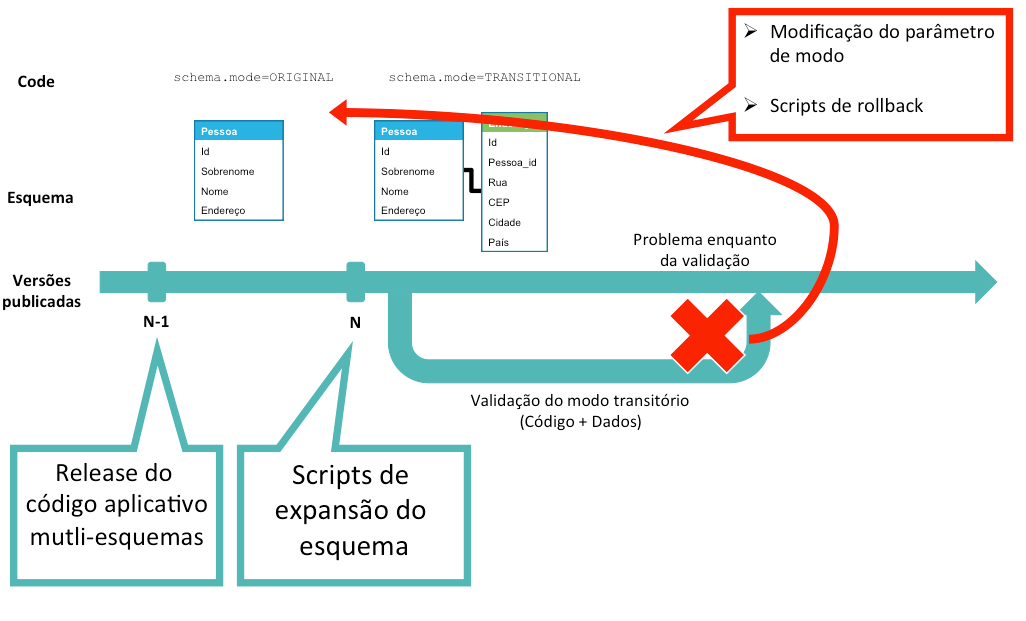
As migrações de esquema podem ter impactos negativos sobre as performances do aplicativo:
Para limitar os impactos, é bom evitar a utilização da palavra chave ALTER que causa locks sobre os objetos atualizados. Uma boa prática é criar novos objetos (colunas e tabelas). É bom saber que existem ferramentas para limitar os impactos dos ALTER: Toolkit de Percona ou Online Schema Change de Facebook que fazem evoluir uma tabela duplicando-lhe, assim não precisa de lock. Essas duas ferramentas são só para bancos de dados MySQL.
Um deploy que impõe uma migração de esquema não é um deploy como os outros, então é necessário limitar a sua freqüência. Na Etsy, os desenvolvedores fazem mais de 30 deploys a cada dia mas somente um deploy com mudanças de esquema na semana, na quinta-feira.
Porque não fazer sem esquema? É uma outra possibilidade que os bancos de dados de tipo NoSQL ditos “schema-less” (sem esquema), como MongoDB, permitem.
Os Gigantes da Web nunca param os seus serviços para atualizarem suas versões, por uma razão bem simples: quando fazemos um deploy cada mês ou semana, pode acontecer uma interrupção de alguns 10 minutos, mas o que vá acontecer se eu aplico o Deploy Contínuo e eu faço 10 deploys cada dia?
Assim, os campeões do Deploy Contínuo que são a Etsy e a FlickR aplicam o Zero Downtime Deployment.
O Netflix tem uma visão diferente do Zero Downtime Deployment. Toda a sua infraestrutura está na Amazon Web Services, o paradigma é diferente:
Para gerar melhor os deploys, o Netflix desenvolveu a sua própria sobreposição em cima das ferramentas da Amazon: ASGARD.
Essa ferramenta permite de gerar clusters de instancias na AWS e integrar com as outras ferramentas de Netflix, oferecendo uma interface de serviços.
O processo é o seguinte:
Com essas ferramentas e uma monitoria eficiente, a Netflix funciona sem ambiante de homologação.
Tudo depende da freqüência de deploys na sua infraestrutura de produção. Se você já uas vários servidores de aplicação com um mecanismo de distribuição de carga, você pode aproveitar para aplicar a estratégia do Zero Downtime Deployment mesmo se você ainda não está fazendo Deploy Contínuo mas faz um deploy a cada mês!