Je l’avais déjà évoqué mais BigTable.
Hybride tout d’abord parce que Cassandra utilise une modélisation « Column-oriented » de la donnée (inspiré par BigTable) et permet d’utiliser Hadoop et Map/Reduce. Ensuite parce que Cassandra utilise des patterns issus de Dynamo comme « Eventually consistent », « Gossip protocols », une approche Master-Master des requêtes d’écriture et de lecture... Un autre gène de Cassandra (et en fait de beaucoup de solutions NoSQL) est que Cassandra a été pensé et construit pour être complètement décentralisé, gérer de façon transparente (au maximum) la perte d’une partie du Cluster, fonctionner entre plusieurs Datacenter (il est possible de configurer Cassandra de manière à s’assurer que la donnée est répliquée entre plusieurs Datacenter…).
C’est ainsi que Cassandra est utilisée entre les 50+ TB de données réparties sur un cluster de 150 nœuds.
Le modèle “column-oriented” est légèrement plus complexe à appréhender que le modèle Key/Value. Dans un modèle Key/Value, une valeur est identifiée uniquement par une clé et la valeur peut être structurée (par exemple au format JSON) ou non (typiquement un BLOB). La façon la plus intuitive de comprendre le modèle « column-oriented » est de commencer avec un modèle Key/Value et d’imaginer que la valeur est une collection d’autres Key/Value. En somme, c’est une structure qui imbrique des Hashmaps.
Perdu? Voilà les principaux éléments définis par Cassandra (Cet article ainsi que la documentation Cassandra fournissent un point de vue plus complet sur les différents types de structures)
Le partitionnement des données est fonction des solutions envisagées et peut être fait soit par le client soit par n’importe lequel des nœuds du cluster et peut-être calculé en utilisant différent algorithmes (le plus populaire et résilient étant le Consistent Hashing). Un autre enjeu derrière le partionnement de la donnée est lié à la localisation de cette donnée : quel nœud de mon cluster est « responsable » de cette donnée ?
Les nœuds du cluster Cassandra réalisent ce travail et partitionnent la donnée suivant la clé (ie. l’identifiant de ligne). Reste que Cassandra peut utiliser, de base, deux modes de partitionnement. Le premier, le RandomPartitioner, permet d’avoir une distribution équilibré et basé sur le calcul d’un hash. Le second est le OrderPreservingPartitioner et garanti que les clés sont organisées selon leur ordre naturel. Ainsi, là où le dernier facilite la récupération de plage de données, le premier facilite la répartition de charge entre les nœuds (les clés étant uniformément réparties). De plus, chaque ligne (et donc l’ensemble des colonnes qui la compose) est stockée sur le même nœud physique.
Enfin et c’est plus lié à la réplication de la donnée, Cassandra assure bien entendu que la donnée est répliqué au sein du cluster mais peut également vous le garantir entre plusieurs Datacenter (si nécessaire…). Cassandra prend alors à charge de répliquer les données dans au moins un des nœuds du datacenter distant (la propriété de tolérance au partitionnement du théorème de CAP prend tout son sens...)
Les solutions NoSQL comme Voldemort ou Cassandra privilégient la disponibilité et la tolérance au partitionnement à la consistance de la donnée donnant ainsi lieu à ce que l’ont appelle « Eventually Consistent ».
La problématique de consistance est en fait lié à la criticité de la donnée et au besoin de définir – pour chaque donnée – le degré de consistance nécessaire. Cassandra défini différents niveaux de consistance. Sans être exhaustif, les principaux niveaux sont :
Alors bien sûr, à un instant donné, il est fort probable que chaque nœud ait sa propre version de la donnée (en imaginant un système fortement sollicité). La résolution des conflits sera alors faite au moment de la lecture (read-repair). La version actuelle de Cassandra ne fournit pas de mécanisme très poussé de résolution de conflits type Vector Clock (devrait être disponible dans la version 0.7). Cette gestion des conflits est donc simplement basée sur le timestamp : le timestamp le plus élevé gagne et le nœud qui lit la donnée est responsable de cette résolution de conflit. C’est un point important car le timestamp est spécifié par le client, au moment où la colonne est insérée. Ainsi, tous les clients de Cassandra se devront d’être synchronisés (grâce à NTP par exemple) de façon à assurer et fiabiliser la résolution des conflits.
L’atomicité est aussi moins forte que ce à quoi nous sommes habitués dans le monde relationnel. Cassandra garanti l’atomicité pour une ColumnFamily : donc pour toutes les colonnes d’une ligne.
“Cassandra is liquid” aurait écrit n’importe quel marketeur et pour être honnête, la plupart des solutions de l’écosystème NoSQL ont été bâties sur ces gènes. Tout d’abord, l’élasticité est au niveau de la modélisation et de la structure des données. Vos données vivront plus longtemps que vos règles métiers et plus de souplesse dans la manière dont vos schémas peuvent évoluer dans le temps est un point intéressant.
Mais l’élasticité est également au niveau de l’infrastructure et sizing du cluster. Ajouter un nouveau nœud à Cassandra est simple. Positionner la propriété AutoBootstrap à «true » et spécifier l’adresse IP d’un des nœuds du cluster. Le nœud ajouté va ainsi être détecté, ajouté au cluster et la donnée sera « redispatchée » (la temps nécessaire dépend bien entendu du volume de donnée à « redispatcher »). Décommissionner un nœud est aussi simple mais demande une action explicite (nécessaire pour différencier d’une panne passagère) via l’utilitaire nodetool (qui fournit également d’autres options permettant de visualiser les streams entre les nœuds…) ou une commande JMX.
Cassandra tourne sur une JVM et expose de propriétés JMX. Il est ainsi possible de collecter des informations depuis jConsole ou n’importe quel outil compatible JMX. Par exemple, il est possible de superviser :
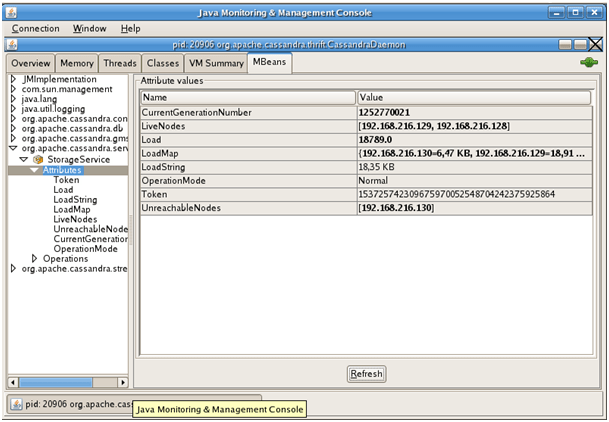
D’autres plugins JMX sont disponibles et fournissent des graphes etc. Il existe même une console Web.
Cassandra utilise Thrift (même si la version 0.6 introduit l’utilisation du protocole Avro). Nous l’avons déjà évoqué mais Cassandra est responsable du routage des requêtes sur le nœud approprié et le client peut donc requêter n’importe lequel des nœuds. Néanmoins, l’API Thrift par défaut ne fournit aucun mécanisme de pool ou de répartition de charge entre les nœuds. Concernant le pool de connexions, les principaux manques sont, à mon avis, (1) la capacité de répartir les requêtes entre tous les nœuds du cluster et (2) la capacité de requêter automatiquement un autre nœud si la première tentative échoue (à cause d’un nœud tombé…).
Reste qu’un plus haut niveau de répartition de charge peut être mis en œuvre au niveau services : 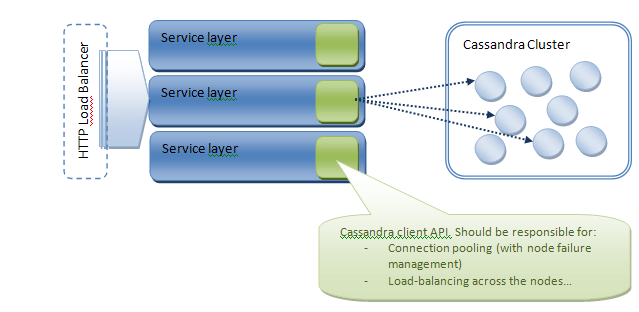
Certaines librairies (par exemple Hector dans le monde Java) fournissent des mécanismes de pool de connections et même de round-robin.
Après cette générale introduction de Cassandra, la prochaine partie se concentrera plus particulièrement sur la configuration d’un cluster Cassandra.