Spark est en évolution constante et maintient un rythme soutenu de sorties de releases, en témoigne la dernière version en date, la 2.2. Dans cette série d'articles, nous allons revenir ensemble sur différentes mécaniques actuellement en place au sein de cet outil et essayer d'en comprendre le fonctionnement.
code {<br /> background-color: #efefef;<br /> font-family: Courier New, Courier,Lucida Sans Typewriter, Lucida Typewriter, monospace;<br />}<br />
Depuis la version 2.0, Spark s'appuie sur un moteur d'exécution retravaillé, nommé Tungsten. Celui-ci embarque avec lui son lot d'améliorations, et confirme la volonté des contributeurs de rendre Spark toujours plus performant et accessible.
En particulier, le gros des efforts de développement s'est concentré sur l'amélioration des DataFrames (et plus récement les Datasets) qui permettent, entre autres, de manipuler de la donnée à partir de requêtes SQL classiques. L'enjeu de ces améliorations est d'offrir aux développeurs une API simple et haut-niveau avec le minimum de contrepartie en termes de performances.
Dans cette optique, une des évolutions du moteur Tungsten semble avoir fait faire un grand pas en avant à Spark puisque, sous réserve d'utilisation des DataFrames, sans aucune modification de code entre Spark 1.6 et Spark 2.0, les performances pourraient être multipliées par 10. Cet exploit serait en majeur parti du à une technique de génération du code à la volée afin d'accroître la vitesse d'exécution… Rien que ça.
Je ne sais pas pour vous, mais pour nous, « plan d'exécution », « génération de code à la volée », « moteur d'optimisation », etc. sont des concepts dont on a tous entendu parler sans trop vraiment savoir ce qui se cache derrière. Et quand on y pense, on pourrait même dire la même chose de Spark, non ?
C'est suite à cette réflexion que nous avons décidé de décortiquer le code source de Spark et d'en extraire l'essence, afin de comprendre en détail ce qu'il se passe sous le capot… Pour cela, nous allons construire ensemble un moteur capable de partir d'une simple requête SQL sous forme de String et de l'exécuter, en s'appuyant sur le code source de Spark.

Nous chercherons à répondre aux questions suivantes :
Ce sera également l'occasion d'appréhender ensemble certaines fonctionnalités de Spark.
Pour cela, nous allons découper cet article en 3 parties : la première traitera du parsing d'une requête, la deuxième de la construction d'un plan d'exécution physique, la dernière partie mettra l'accent spécifiquement sur la génération de code.
L'intégralité du code que nous allons réaliser est présent sur le GitLab d'OCTO : que les plus curieux d'entres-vous n'hésitent-pas à y faire un tour avoir une vision détaillée du fonctionnement de notre implémentation !
La génération de code sera le point d'arrivée de cette série d'article mais nous allons voir qu'avant cela, il y a un certain nombre d'étapes par lesquelles nous devons passer. La première consiste à transformer une requête SQL sous forme de String en quelque-chose d'un peu plus pratique à manipuler avec du code.
L'objectif ici n'étant pas de réimplémenter Spark mais uniquement de comprendre son fonctionnement, nous n'allons pas chercher à supporter l'ensemble de la version 2011 de SQL. Le langage SQL que nous allons implémenter va se restreindre aux contraintes suivantes :
SELECT avec des clauses FROM et JOIN seront interprétéesNUMBER et TEXTConcernant le dernier point, notons que Spark possède une API particulière pour décrire les sources de données (qui seront considérées comme des tables au sein des requête SQL) et qu'il est possible d'ajouter ses propres sources, mais ce n'est pas quelque-chose que nous allons couvrir ici.
La première étape de notre périple va être de transformer une String en quelque chose de programmatiquement utilisable…
Cette transformation se déroule en deux étapes réalisées par deux composants :
SELECT, WHERE, FROM, etc.) et les localise dans une String donnée en entrée. Il transforme ainsi une String en une liste d'éléments qui composent notre lexique. Ces éléments sont ce que l'on appelle des Tokens. Les mots qui ne font pas partie de ce lexique sont identifiés par le token Literal s'il s'agit d'une valeur (un nombre ou un texte entre guillemets), et sinon, il s'agit d'un Identifier.L'AST est un arbre dont le rôle est de représenter une requête SQL parsée, en hiérarchisant les Token identifiés par le Lexer.
Par exemple, lorsque l'on écrit SELECT column, il faut comprendre que le terme column s'applique au terme SELECT. Le premier est donc un argument du second. Dans l'AST, le SELECT se trouve au dessus du column.
Deux catégories d'AST sont à distinguer :
WHERE et ON de nos requêtes) ;FROM et JOIN, mais on peut aussi penser aux SELECT si l'on avait implémenté la notion de sous-requête).En deux mots : la Relation correspond à l'origine de la donnée, et l'Expression à ce que l'on en fait.
Lexer et ParserChacun des types de Token identifiables par le Lexer est représenté par une case class Scala qui étend le trait Token. Le rôle de la classe Lexer va donc être simplement d'associer certains motifs d'une String à la sous classe de Token correspondante.
L'idée n'étant pas d'écrire un parser qui supporte la totalité du langage SQL, nous allons utiliser les Parser Combinators qui suffisent amplement dans notre cas.
def select: Parser[Select] = positioned { "SELECT" ^^ { _ => Select() } }
Exemple d'un Parser Combinator qui permet de parser le mot clé SELECT en un Token Select() (qui est une case class Scala)
Pour une explication détaillée du fonctionnement des Parsers Combinators, nous redirigeons le lecteur vers la documentation de cette librairie.
Comme leur nom l'indique, il est possible d'associer plusieurs Parser Combinators ensemble, chacun étant en charge d'un mot clé. Nous sommes ainsi capables d'identifier tous les termes que l'on souhaite au sein d'une String, ce en itérant sur chacun des mots de la String et en appliquant tous nos Parser Combinators.
L'ensemble des règles ainsi implémentées dans notre code est regroupé dans notre objet Lexer présent dans Lexer.scala. Token.scala contient l'ensemble des Tokens pris en compte par notre Lexer.
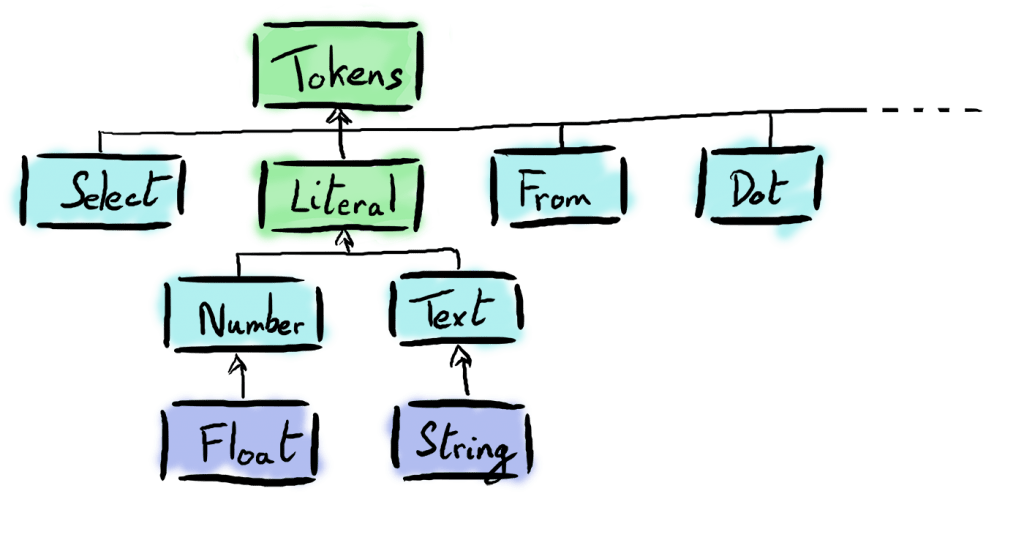
Liste des case classes qui dérivent de Token
L'objet Parser s'appuie également sur les Parser Combinators pour construire notre AST.
Si l'implémentation des différents parsers peut sembler légèrement absconse au premier abord, il n'est pas nécessaire d'en comprendre les détails pour poursuivre la lecture.
L'utilisation des Parser Combinators constitue néanmoins une pratique courante pour le parsing en Scala.
Cette fois, grâce au travail du Lexer, ce ne sont plus des String que l'on identifie, mais des Token, ce qui simplifie le travail et la compréhension du programme.
Pour pouvoir construire un arbre à partir de ces Tokens, on ne peut plus se contenter d'appliquer l'ensemble de nos Parser Combinators à nos éléments (comme nous l'avions fait dans le Lexer). Nous allons devoir appliquer de façon récursive, et dans un certain ordre nos différents Parser Combinator.
Par exemple, nous allons commencer par le parser Select, qui lui même attend en paramètre un nom de colonne, un From, et, éventuellement, un Where. Chacun de ces paramètres correspondent également à des Parser qui attendent, eux aussi, d'autres paramètres. De façon récursive, nous allons ainsi construire notre arbre syntaxique (le Parser Combinator correspondant aux Expressions est un peu particulier, cf. Pour aller plus loin).
Le Select est donc un type d'AST qui attend en paramètre :
SELECTFROMWHERE (sachant qu'il est possible d'appliquer plusieurs filtres en utilisant les expressions AND ou OR)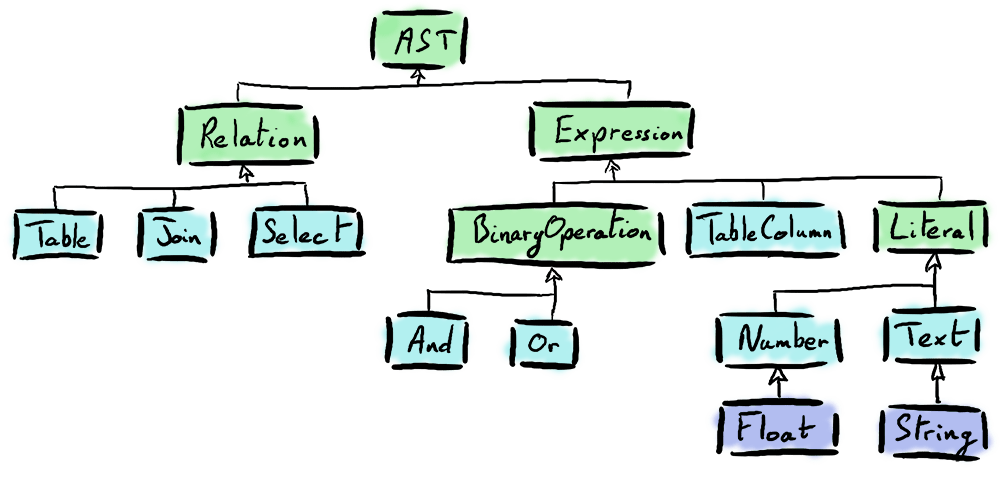
Hiérarchie des case classes qui dérivent de AST
Pour résumer, le parsing se déroule donc en deux étapes :
String en une Seq[Token] grâce à l'objet Lexer qui va valider le vocabulaire utilisé au sein de la requête SQLSeq[Token] en un AST grâce à l'objet Parser qui va valider la sémantique de la requête SQL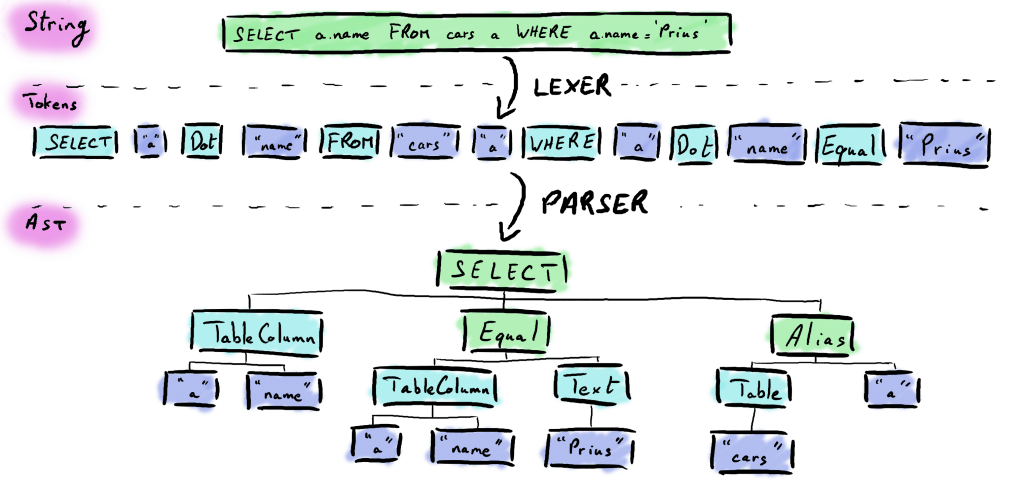
Les deux étapes qui constituent le parsing
Les auteurs de Spark ont quant à eux pris le parti de déléguer cette fastidieuse étape de parsing à un célèbre outil qui mature depuis plus de 20 ans cette problématique : ANTLR !

Je pense qu'on l'a tous déjà croisé quelque-part…
A l'inverse de bon nombre de projets Scala, les développeurs de Spark ont décidé d'utiliser Maven en lieu et place de SBT pour gérer le build. Juste avant la compilation de Spark, c'est donc le plugin Maven d'ANTLR qui va générer les classes nécessaires pour réaliser le parsing (ce que nous avons fait manuellement en implémentant le Lexer et Parser ci-dessus) en se basant sur la grammaire définie ici.
La traduction en case classes est quant-à-elle réalisée ici par l'AstBuilder.
La première implémentation basée sur les Parser Combinator que nous avions réalisée était assez naïve, ce qui a eu pour conséquence des embêtantes StackOverflowException… Tiens-donc.
En effet : bien que relativement simple, la grammaire que nous avons définie est récursive (par exemple, un terme d'une addition peut lui-même être une addition) ce qui n'est pas supporté de base par les Parser Combinators. De ce fait, nous avons dû revoir notre implémentation et mettre en place un Recursive Descent Parser dont le principe est très bien décrit ici. Pour nous aider dans cette tâche, nous nous sommes énormément inspirés de cette classe disponible sur GitHub.
Le parsing de requête SQL est une problématique récurrente : en plus des SGBDR communs, nombre de solutions Big Data s'appuient aujourd'hui sur le langage SQL pour manipuler les données.
Apache Calcite est une initiative d'Apache dont l'objectif est de résoudre différentes problématiques liées à la conception de base de données (SGBDR ou NoSQL), dont - entres autres - le parsing du SQL.
Par exemple, Apache Hive s'appuie sur Calcite pour le parsing du SQL (mais également pour l'optimisation des requêtes, mais ça, c'est pour une autre fois…).
A partir de notre String de départ qui était difficilement utilisable, nous avons pu, à l'aide de notre Parser et de notre Lexer, en tirer un AST beaucoup plus exploitable programmatiquement et qui décrit l'objectif de la requête SQL.
Nous allons voir dans le prochain article comment transformer cet AST en une nouvelle structure qui va cette fois-ci décrire la manière dont la requête va s'exécuter… Rendez-vous la semaine prochaine !