Je vous propose dans cet article une revue chronologique des événements et des idées qui ont contribué à l’émergence des technologies Big Data d’aujourd’hui et de demain. Ce que nous pouvons constater au niveau des bottlenecks (=goulots d’étranglements) est qu’ils se déplacent en fonction des avancées techniques que nous faisons. Aujourd’hui c’est le garbage collector de la JVM, demain ce sera un problème différent.
Voici ma version de l’Histoire :
L’ère du Web a changé radicalement les choses en terme de donnée. Nous sommes passé d’un modèle plutôt rigide du RDBMS qui était conçu pour de l’informatique de gestion (gestion des stocks, comptabilité) à l’informatique de contenu, extrêmement varié et en très grande quantité : A ses débuts, l’index de Google référençait 26 millions de pages internet (en 1998).
En partant du principe qu’une page web pèse 100 Ko à l’époque, on peut estimer à 2,5 To le volume de données à indexer ! Deux ans plus tard, le volume à indexer dépassait déjà 100 To…
Une phrase de Nissan Hajaj, ingénieur chez Google Search, symbolise cette prise de conscience :
“We’ve known it for a long time : the web is big.”
Google a besoin de combiner deux éléments pour que son idée fonctionne
A l’époque, il y a deux moyens qui existent pour des calculs intensifs :
Le premier reprend le principe de scale up, de façon simplifiée : il suffit d’ajouter de la RAM et du CPU sur la carte mère pour augmenter la puissance.
Le deuxième applique le principe de scale out, ajouter une machine dans le cluster pour augmenter sa puissance. On le retrouve sous le terme de horizontal scalability.
Le contenu des sites que doit indexer Google est extrêmement variable.
En effet, le HTML produit des pages toutes très différentes (en taille, en contenu, etc…). Il n’est pas concevable de stocker cela dans un RDBMS qui est conçu pour gérer des types précis avec une taille fixe (INTEGER, VARCHAR(255), TIMESTAMP, etc…).
Pour anticiper l’évolution du Web, il est nécessaire de ne pas définir de schéma, de type, au moment du stockage de la donnée afin de faire évoluer le schéma de manière transparente.
Il faut donc à Google un système qui sache interpréter le type de donnée à la lecture, au lieu de le définir à l’écriture. Une sorte de brute force pour réaliser des batchs d’indexation du Web.
L’un est dit paradigme à mémoire partagée. C’est le cas sur une machine seule qui possède plusieurs CPUs (ou cœurs). Les CPUs se partagent une même mémoire RAM dans laquelle ils font des accès.
L’autre paradigme est dit à mémoire distribuée. Nous avons plusieurs machines, chacune possède sa propre mémoire. L’idée est de se passer des informations à chaque étape. Une boucle tourne sur chacune des machines, et à chaque itération, il y a un mécanisme de synchronisation pour se communiquer l’information entre les machines (Message Passing).
Dans le cas du clustering, les stratégies utilisées avec Message Passing pour la distribution et la récupération de la donnée (scatter, gather, broadcast, reduction) utilisent un nœud maître (=master) possédant le dataset et des nœuds exécutants =(workers) sur lesquels la donnée sera téléchargée pour exécuter un traitement, puis le résultat sera rapatrié sur le master.

Si la solution pour traiter notre dataset est de le communiquer d’abord par le réseau, le réseau forme un goulot d’étranglement pour un workload data intensive.
Faisons le calcul rapidement : (26 000 000 de pages * 100 Ko de taille) / 100 Kbits de bande passante par seconde / 60s / 60min / 24h = 2,5 jours de transfert de données
A l’époque, des problèmes de ce type sont rares. MPI (Message Passing Interface) était la bibliothèque utilisée pour du calcul intensif, elle n’était pas conçue pour du traitement de données volumineux. Mais pour Google, c’est un nouveau cas d’utilisation qui n’est traité par aucune solution existante.
Les traitements de Google (calculer le PageRank, construction d’un index inversé) sont de longue durée. Dans un environnement distribué, la probabilité qu’un traitement échoue augmente avec le nombre de machines exécutant le traitement en parallèle. Ce qui veut dire que Google devait penser à une façon de tolérer l’erreur (on parle de fault tolerance)
A partir de ces constats successifs, Google s’inspire de la programmation fonctionnelle pour créer une nouvelle approche dans un contexte distribué : MapReduce
Le principe de base est de supprimer ce goulot d’étranglement qu’est le réseau : déplacer les binaires, plutôt que la donnée.
Au lieu de distribuer les données à la lecture, on va distribuer les données à l’écriture sur plusieurs machines. Au moment de la lecture, il n’y aura seulement que le code compilé qui transitera sur le réseau à la place de 100 To de pages HTML.
En plus de cela, le paradigme MapReduce a pour vocation de grandement simplifier l’écriture de programmes parallèles. Il existait des avancés pour que MPI co-localise les données mais cela n’a jamais vraiment pris car ce n’était pas très intuitif et rajoutait de la complexité.
La tolérance aux erreurs est plus facile à implémenter : à l’écriture de la donnée, on la réplique dans des endroits différents. En cas de panne de la machine contenant l’information, on pourra faire nos traitements sur le réplicat.
Hadoop arrive en 2006. Pour se construire, Hadoop a besoin d’un système de fichier distribué, Nutch File System (qui devient HDFS), et d’une implémentation du papier de Google MapReduce. Le framework est écrit en Java, pour la simple et bonne raison que “Java est portable, facile à debugger et largement plébiscité par la communauté“, disait Doug Cutting, son principal créateur.
Avec MapReduce, on utilise un autre data-modèle pour représenter nos enregistrements : clé / valeur L’avantage de se modèle c’est qu’il est très facilement distribuable. Chaque machine récupère une séquence de clés à gérer. Il est facile d’itérer en parallèle sur chacune des clés et de procéder à un traitement sur la valeur. Le nombre de séquences définit le degré de parallélisme (le nombre de machines qui traitent une séquence parallèlement).
// map phase. Ce code est exécuté sur chaque worker
while(recordIterator.hasNext) {
record = recordIterator.next;
map(record.key, record.value);
}
Il ne reste plus qu’à l’utilisateur (le développeur MapReduce) de préciser ce que fait la méthode map()
Les nouvelles paires de clé / valeur générées par les mappers sont ensuite distribuées aux reducers via le réseau. Cette phase d’envoi se nomme le Shuffle & Sort.
On peut remarquer que MapReduce n’est pas vraiment une solution complète face au problème du réseau. En effet, La phase de shuffle & sort utilise principalement le réseau comme support d’échange des données de sortie de la phase map vers les reducers. La bonne pratique à adopter dans les mappers est de filtrer les enregistrements, projeter (réduire le nombre de colonnes), pré-agréger, ainsi que de compresser afin de réduire considérablement la donnée qui transite sur le réseau dans la phase suivante. Malheureusement, ces pratiques ne sont applicables qu’au cas par cas, il est difficile de trouver une solution globale à ce problème.
Vers 2008, on commence à voir apparaître un nouveau cas d’utilisation : le besoin d’un langage de plus haut niveau pour exprimer un traitement distribué. Un langage conçu pour la donnée, le SQL.
Facebook développe Hive, un moteur SQL générant du MapReduce, en 2009. Google présente Dremel, un datastore distribué interprétant du SQL et “optimisant” le full scan (amusant), qui donnera naissance au projet Apache Drill (porté par MapR). Impala, Presto, Apache Phoenix, Druid, Pinot, sont toutes autant de technologies qui vont adresser ce besoin d’analyse sur de gros volumes.
Bref, l’Analytics est le nouveau cas d’usage.
Parallèlement on commence à voir des essais dans le domaine de l’intelligence artificielle. Le Machine learning fait son entrée sur Hadoop avec Apache Mahout et ouvre de nouvelles perspectives qui affolent la presse spécialisée.
Ces deux nouvelles possibilités sur Hadoop (analytics et machine learning) ont un caractère commun : elles sont constituées d’itérations.
Ainsi, une requête SQL constituée de plusieurs jointures se découpera en plusieurs jobs MapReduce, stockant le résultat intermédiaire sur HDFS. Un algorithme de clustering comme K-means procède par itérations successives jusqu’à ce que les centroïdes atteignent un état stable. On leur donne le nom d’algorithmes itératifs.
A chaque fin d’itération MapReduce, on stocke le résultat intermédiaire sur HDFS pour l’itération suivante. Non seulement on stocke tout sur disque dur, mais la donnée sera répliquée (3 fois par défaut). Ensuite, dans l’itération d’après il faut recharger les données intermédiaires en mémoire (lors du map) pour directement les envoyer aux reducers (avec du shuffle !). Il s’avère qu’HDFS est une abstraction plutôt lente (30 Mo /s en écriture, 60 Mo /s en lecture de moyenne sur SATA) qui vient accroître le temps de traitement global.
Vous l’aurez sûrement deviné, les I/O disques sont le nouveau goulot d’étranglement.
Ce goulot existait déjà en réalité, mais il était masqué par celui des I/O réseau, et puis, pour du batch ça n’était pas trop douloureux.
Pour minimiser l’impact d’une itération, on va faire ce que l’on fait habituellement lorsque qu’on a un besoin de lire / écrire rapidement de la donnée : cacher en RAM.
 Ça tombe bien, le prix de la mémoire vive a beaucoup baissé et il est commun depuis quelques temps de trouver des serveurs avec 128 ou 256 Go de RAM.
Ça tombe bien, le prix de la mémoire vive a beaucoup baissé et il est commun depuis quelques temps de trouver des serveurs avec 128 ou 256 Go de RAM.
On peut donc imaginer qu’un dataset d’1 To (répliqués) tiendrait en mémoire sur un petit cluster d’environ 12 serveurs…
C’est ainsi que l’article de recherche). Le Framework est introduit par l’université de Berkeley pour résoudre justement ce type de workload itératif. Pour ce faire ils vont penser une abstraction du modèle de donnée transitant à travers les itérations : le RDD (Resilient Distributed Dataset paper))
Un RDD est une collection d’enregistrements, distribuée à travers un cluster, récupérée à partir d’un contexte initialisé au début du job.
//records représente un RDD
JavaRDD<String> records = spark.textFile("hdfs://...");
On y applique successivement des transformations ou des actions. Ces deux concepts propres au vocabulaire de Spark peuvent être généralisés par ce que l’on appelle une opération. Il existe des opérateurs de type map side, des opérateurs de type reduce side (shuffle operator). La différence entre l’un et l’autre, c’est que la reduce side est un type d’opérateur qui déclenche le shuffle (phase de redistribution par le réseau des paires clé/valeur) avant de s’exécuter. Spark n’étant pas la seule abstraction s’appuyant sur MapReduce, la majorité des frameworks type dataflow (pour exprimer une suite de transformations) utilisent ces mêmes concepts : Apache Flink, Apache Crunch, Cascading, Apache Pig, etc…
records.filter(...) // est une opération map-side
records.groupByKey() // est une opération reduce-side
Dans Spark, une action génère une exécution, avec une phase de shuffle.
Il y a différents types de RDD, dont certains offrant des fonctions de caching notamment pour préciser qu’un dataset sera utilisé sur plusieurs itérations (donc cacher le résultat intermédiaire). Le Dataset sera conservé dans un cache local, en RAM, ou bien sur disque, ou encore partagé entre la RAM et le disque.
records.cache();
Mais ce n’est pas le seul facteur d’accélération des temps intermédiaires. Spark recycle les “executors” - les JVMs utilisées pour exécuter les traitements - intelligemment. On s’est rendu compte qu’une partie de la latence d’Hadoop venait du temps de démarrage d’une JVM. Le recyclage permettait de réduire le temps de traitement de 30 secondes par itération (dans le cas d’Hadoop, un conteneur met 30 secondes à s’initialiser). L’astuce existait déjà dans Hadoop (la propriété mapred.job.reuse.jvm.num.tasks dans la configuration d’Hadoop v1) mais n’était pas activée par défaut.
Avec les améliorations en terme de latence grâce au recyclage des JVMs et grâce à l’utilisation de caches, on commence à voir de plus en plus de systèmes proposant de l’interactif. Spark propose une console interactive (bin/spark-shell) permettant de taper et d’exécuter du code au fur et à mesure (langages Scala et Python).
C’est une sorte d’algorithme itératif. Le SQL, comme on l’a vu, est devenu un point important sur Hadoop. Le raccourci rapidement fait sur les technologies Big Data supportant le SQL, sera de comparer la latence avec les anciens systèmes qui faisaient eux aussi du SQL (mais sur de bien moins gros volumes) : sous la minute en moyenne pour afficher le résultat d’une requête.
On donne accès aux équipes métier, aux analystes, aux ingénieurs BI à toute cette puissance afin qu’ils puissent “interagir” avec les données et en sortir de la valeur.
Hive - avec les initiatives Stinger et Stinger.next - évolue dans ce sens. Il propose de nouveaux moteurs d’exécution, plus adaptés à l’interactif (Tez, Spark) pour diminuer les temps de traitements sur les requêtes adhoc.
L’enjeu de ces nouveaux moteurs d’analyse (Spark, Flink, Tez, Ignite) est de pouvoir stocker de très grosses quantités de données en mémoire. On augmente donc la taille de la Heap Java des conteneurs (options Xmx et Xms de la JVM). Elle va prendre plus de RAM. De 2 à 4 Go en moyenne pour MapReduce, elle passera à 8 ou 16 Go pour Spark, Tez, et Flink. Pour les I/O disque, elles seront réduites par l’augmentation de la taille de la Heap simplement parce que nous avions la possibilité de stocker plus d’objets en mémoire.
Les traitements interactifs amènent donc à des tailles mémoire plus conséquentes à gérer pour la JVM, alors qu’on alloue beaucoup de petits objets (les enregistrements d’un dataset), fréquemment (à chaque nouvelle requête adhoc).
On se retrouve devant un nouveau goulot d’étranglement : le garbage collector
Le garbage collector de la JVM est un mécanisme très puissant, facilitant grandement la gestion de la mémoire de la JVM (la Heap). Il automatise la des-allocation des objets inutilisés.
Pour gérer ses objets, il constitue un graphe dans lequel un nœud représente un objet, et un arc relié à un autre nœud correspond à une référence (un objet qui référence un autre). Si un objet n’a plus d’arc le reliant, cela signifie qu’il n’est plus référencé par aucun autre objet, donc il peut être des-alloué à la prochaine collecte (il est “marqué”). Logiquement, le temps de parcours de la collection d’objets est proportionnel au nombre d’objets existants dans la Heap, et donc la taille de la Heap (plus elle est grande, plus on peut y en mettre).
Le garbage collector met le système entier en pause dans certains cas (problème de concurrence). Voici des exemples de cause de pause :
Si cela vous intéresse de creuser un peu plus le fonctionnement du GC, Martin Thompson en a fait une très bonne explication.
Dans le schéma ci-dessous, on constate que les pauses arrêtent totalement le système pour procéder à leur traitement, qu’ils soient effectués parallèlement ou non. On appelle aussi c’est pauses STW pour Stop The World. 
Les collections Spark sont bien souvent composées de millions ou milliards d’enregistrements, représentés par des instances. Toutes ces allocations et des-allocations rapides fragmentent beaucoup la mémoire. 
Le garbage collector est déclenché à une fréquence qui varie en fonction de l’utilisation de la Heap. Si celle-ci ne propose plus assez de mémoire aux demandes d’allocation, le garbage collector procédera à une collecte pour libérer de l’espace. Si celle-ci est trop fragmentée, la JVM procédera à une compaction suite à une collecte.
Ces passages sont parfois trop longs pour de l’interactif (imaginez 30 secondes de pause GC). C’est pourquoi les principaux travaux actuels sur les performances de Spark traitent du garbage collector. Daoyuan Wang de la société Databricks (principal contributeur de Spark) fait un tour d’horizon des tweaks possibles dans un billet intitulé Tuning Java Garbage Collection for Spark Applications
Philippe Prados soulève la question de l’avenir du GC dans un précédent article du Blog OCTO : La mort prochaine du ramasse-miettes ? “Aujourd’hui, la configuration a suffisamment évolué pour mettre le ramasse-miettes sous tension. Les évolutions incrémentales, qui sont réelles, suffisent de moins en moins à répondre aux demandes. Les GC évoluent, mais pas assez vite par rapport à leur environnement.”.
C’est pourquoi les ingénieurs vont commencer à chercher des solutions ailleurs…
Dans les systèmes distribués de traitement de donnée (utilisant la technologie Java), on constate deux variantes pour essayer de diminuer l’impact du garbage collector dans la JVM.

Ces deux variantes utilisent la même classe du JDK : le ByteBuffer Un ByteBuffer est un type d’objet qui encapsule un tableau d’octets avec des méthodes d’accès. On sérialise en binaire l’information au préalable avant de l’insérer dans le ByteBuffer. C’est une sorte de conteneur bas niveau, dans lequel on va stocker nos collections d’objets. Il existe deux types de ByteBuffer comme la documentation le décrit : 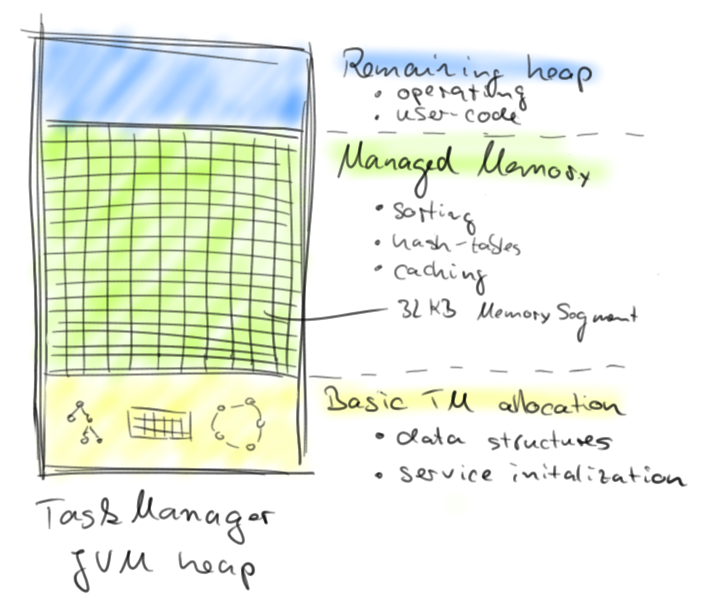
size(), il faut donc connaitre exactement la taille de ses objets en mémoire (variant en fonction du hardware) pour allouer de nouveaux objets à côté, sans réécrire par dessus, ou sans dépasser du buffer. Son deuxième atout est de ne pas copier le contenu du buffer dans un buffer intermédiaire lors d’un accès.Le GC n’est pas pour autant mis sur la touche. Il gère toujours les objets dé-sérialisés et les structures temporaires que l’utilisateur alloue dans son programme (le développeur qui utilise l’API Spark).
Flink a d’abord implémenté la première solution, c’est à dire l’utilisation de Non-Direct ByteBuffer alloués dans la Heap. Les ByteBuffer sont nommés MemorySegment, ils sont fixés à 32 Ko en taille et sont gérés par le MemoryManager. Ce dernier a pour rôle de distribuer les bons segments aux opérateurs (filter, join, sort, groupBy, etc…).
Flink prévoit de migrer vers la deuxième méthode : l’utilisation de la mémoire off-heap afin d’accélérer encore les accès (pas de copie dans un Buffer tampon) et de contourner presque entièrement le garbage collector (il y a toujours l’objet dé-sérialisé qui est stocké dans la Heap).
Avec ces nouvelles astuces (les ByteBuffer), la sérialisation est le mécanisme qui devient le plus important. C’est pourquoi il devient primordial de développer des sérialiseurs pour chaque type d’objet. Flink intègre des sérialiseurs “faits maison”, mais la tâche est plutôt lourde (quid de la généricité de Java qui transforme tout type en Object ?) et les classes de l’utilisateur sont sérialisées à partir d’une sérialisation basée sur de la réflexion (Kryo), bien moins performante que la version “fait maison”.
Spark a prévu de rattraper son retard sur Flink en lançant le projet Tungsten, et pour l’heure la dernière version (1.4) intègre un mécanisme intéressant qui permet de générer du code de “custom-serializer”. La génération de code facilite la vie du développeur tout en étant bien plus spécifique que l’utilisation de bibliothèque comme Kryo.
Ils n’en sont qu’au début, mais le projet prévoit d’intégrer un MemoryManager avec l’apparition de page mémoire à la manière de Flink dès la version 1.5, et l’apparition de structures utilisant efficacement les caches processeur (L1, L2, L3).
Les ByteBuffer sont très utiles mais ils ont un gros défaut c’est qu’ils sont coûteux en terme de sérialisation / dé-sérialisation (même avec custom-serializer). Les frameworks comme Flink et Spark passent leur temps à effectuer ces deux tâches pour accéder aux enregistrements. Pour supprimer la charge de dé-sérialisation systématique des objets dans les opérateurs, on voit donc apparaître des structures de donnée dites “cache aware”. C’est à dire une structure capable d’utiliser efficacement le cache partagé des processeurs .
Le modèle est le suivant : on stocke une collection contiguë de pointeur+clé dans un ByteBuffer. Lorsqu’un opérateur (join, groupBy, sort, etc…) effectue la comparaison entre les enregistrements, il le fait sur les clés. Il est donc plus intéressant de les séparer de leur valeur (souvent plus volumineuse). Les clés sont de taille fixe ce qui rend le parcours de la collection efficace sans dé-sérialisation (vous vous rappelez les RDBMS au début, c’est la même chose). On va faire une comparaison binaire entre les clés (ou les premiers octets des clés de type string), et accéder à la valeur seulement quand on en a besoin. Cet accès se fait via le pointeur qui se trouve à côté de la clé. Une fois les octets récupérés depuis le ByteBuffer, on les dé-sérialise en objet.
Voici un schéma qui récapitule cette explication : 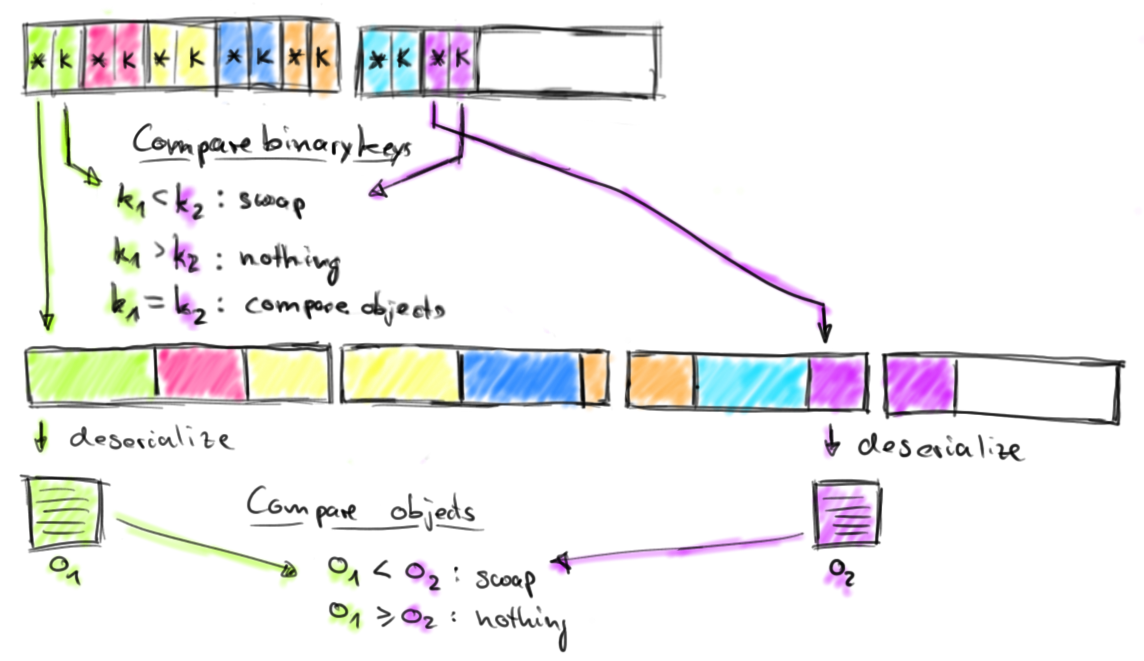
Pourquoi ces structures sont “cache aware” ? En fait, ces structures sont accédées très fréquemment, et elles utilisent peu de mémoire (car elles n’ont que des clés et des pointeurs), ce qui fait que l’OS va les placer dans le cache partagé des processeurs (L1, L2, L3).
En analysant tout cela, je me suis fait la réflexion suivante :
En voyant tous ces efforts pour contourner le garbage collector, on est en droit de se demander pourquoi utilise-t-on une plateforme dont le principal atout est de proposer une mémoire managée, si c’est pour éviter de l’utiliser ?
Dans la pratique, l’utilisateur de frameworks tel que Flink et Spark possède le meilleur des deux mondes. Ces frameworks limitent l’impact du GC pour leur mécanique interne, optimisant la gestion de datasets volumineux, ce qui les rend extrêmement performants. Mais ils permettent aux développeurs d’utiliser un langage de haut niveau, qui les abstrait de la gestion de la mémoire, ce qui est un argument de poids vis à vis de leur adoption.
Résoudre les problèmes de goulot d’étranglement, c’est un éternel recommencement (une boucle infinie). Avant même que Spark n’ait intégré ces évolutions, on peut déjà parier une pièce sur le fait que le cache partagé des processeurs sera le prochain bottleneck des systèmes Big Data. Comme le disait Carlos Bueno : Cache is the new RAM
Le futur nous dira comment le contourner…

Merci aux OCTOs pour leur relecture.
Restez à l'écoute, le Whitepaper Big Data d’OCTO arrive prochainement !