Après avoir décrit le monitoring de flux et les bonnes pratiques pour le mettre en place, passons à un cas pratique. Nous allons détailler un exemple complet et documenté de monitoring d’un mini-système d’information combinant appels de services et envois de messages, avec des modèles de code.
Les composants applicatifs présentés dans cet article ont des noms génériques (frontend, middleend et backend) afin que chacun puisse facilement les adapter à son propre contexte. Nous aurions pu, par exemple, imaginer le frontend comme une application mobile ou une application web monopage javascript, le middle-end comme une couche de services REST (API), et enfin le backend comme un système de persistance ou encore d’analyse des transactions.
Le code proposé dans cet article a été écrit dans un but illustratif. Il est donc le plus simple possible et ne comprend par exemple ni gestion des erreurs ni optimisation. À vous de vous en inspirer et de l’adapter (il est sous licence open source Apache) mais surtout ne le réutilisez pas tel quel.
Les étapes permettant de tester le code vous-même sont décrites dans la documentation du projet.
Pour que l’article ne soit pas trop long, nous avons utilisé des liens plutôt que du code source inclus dans le texte.
Si des portions du code vous semblent peu claires ou que vous avez des suggestions, merci de créer un ticket ; si vous avez des idées d’améliorations les pull requests sont les bienvenues.
Le premier article expliquait que les services métier ont deux caractéristiques:
Un système d’information qui combine ces deux aspects nécessite d’avoir des outils de monitoring flexibles et qui reposent sur des technologies interopérables.
L’architecture applicative présentée ici prend en compte ces éléments:
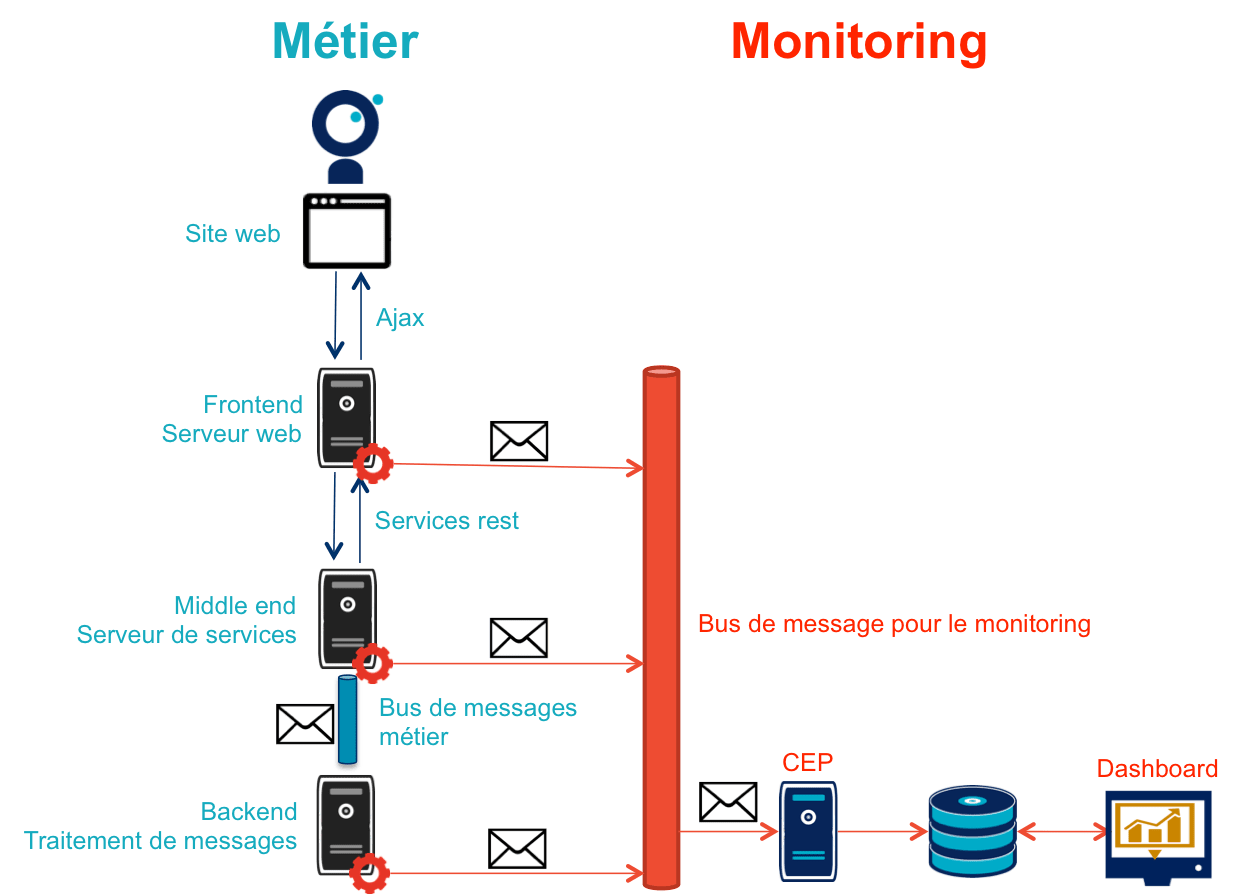
Côté métier :
Côté monitoring :
Il est important de bien définir le format des messages de monitoring, même si le système de traitement doit être conçu pour pouvoir s’adapter facilement à différents cas. L’utilisation d’un gabarit commun permet de simplifier l’exploitation des messages dans le CEP et les dashboard.
Dans notre cas, nous avons choisi d’utiliser des messages au format JSON:
{
"correlation_id": "octo.local_MonitoringBase_24389_2015-01-30 11:05:29 UTC_36cddd01-7bcd-4ced-8024-919ff1dbe6ca", // l'id de correlation
"timestamp": "2015-01-30T12:05:29.230+01:00", // horodatage du message
"module_type": "FrontendApp", // nom du module qui envoie le message
"module_id": "FrontendApp_octo.local_001", // identifiant du module qui envoie le message
"endpoint": "GET /messages", // nom du service
"message_type": "Send message to backend", // type de message
"begin_timestamp": "2015-02-19T22:11:15.939+01:00", // optionnel: horodatage du début de l'action en cours
"end_timestamp": "2015-02-19T22:11:15.959+01:00", // optionnel: horodatage de la fin de l'action en cours
"elapsed_time": 0.020169, // optionnel: temps mis pour l'action en cours
"service_params": {
// optionnel: paramètres d'appel du service
},
"headers": {
// optionnel: en-têtes d'appel du service (en-têtes http par exemple)
}
"result": {
// optionnel: résultat de l'appel du service
}
}
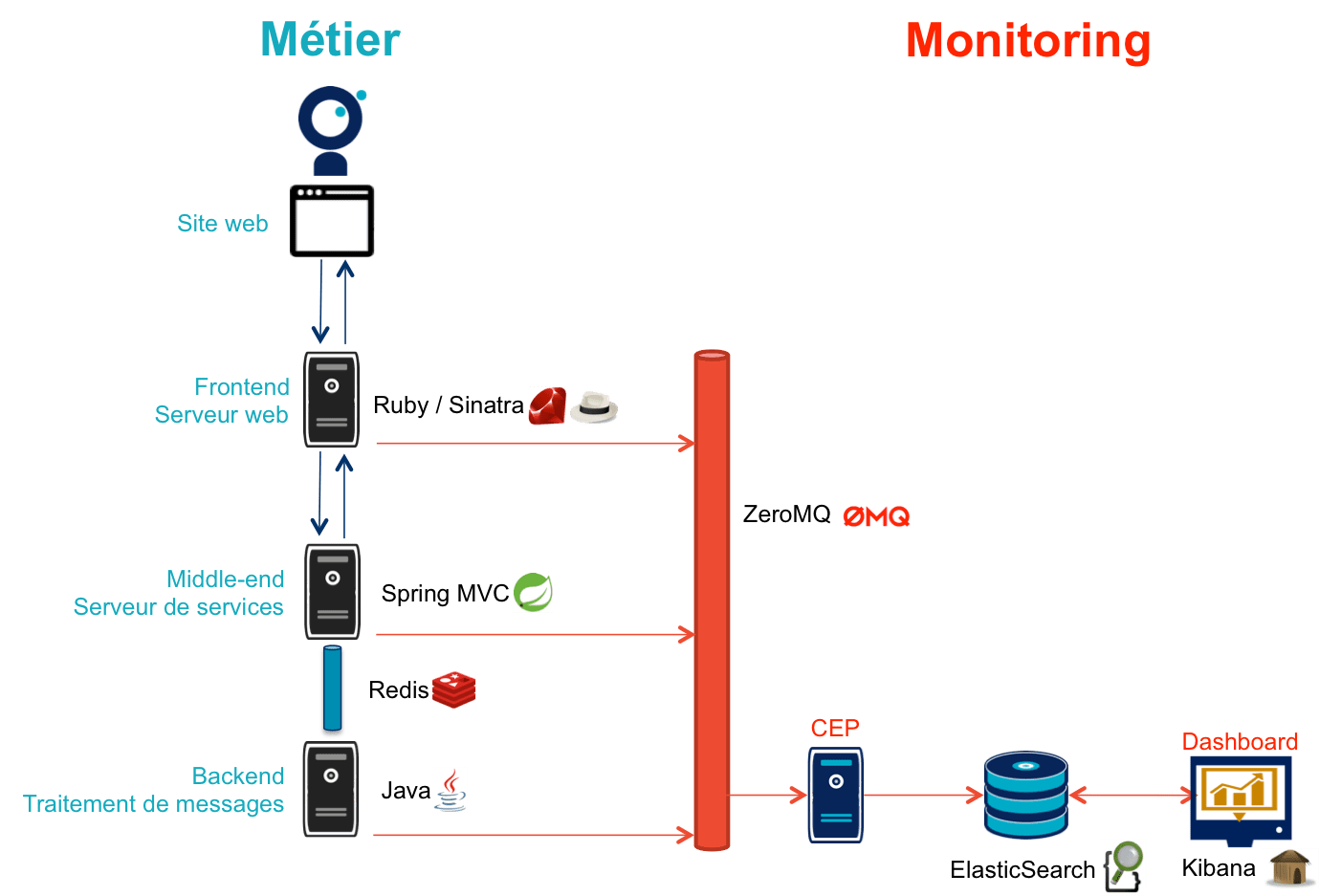
Pour fournir les données nécessaires, chaque brique embarque du code permettant de récupérer les informations utiles et de les poster dans un bus. Pour pénaliser au minimum les performances du code applicatif, l’envoi des messages s’effectue systématiquement dans un thread dédié, et une gestion d’exception isole le code de monitoring du code métier.
Conformément aux recommandations du premier article, c’est un bus ZeroMQ qui a été choisi pour ses très bonnes performances.
Le serveur frontend est en Ruby et utilise le framework web Sinatra qui est parfait pour comme ici exposer facilement des services web.

Le code de monitoring est situé dans la classe monitoring_base.rb
Le framework Sinatra fournit les points d’entrées nécessaires pour le monitoring sous forme de méthodes before et after où toutes les informations de la requête en cours sont accessibles. Pour pouvoir stocker des informations pendant l’exécution de la requête, comme l’heure du début de son exécution, un champ est ajouté à la classe Request.
La méthode permettant d’appeler des services est surchargée pour faire deux choses :
Les données sont postées dans une queue et consommées dans un thread séparé.
Le serveur middle-end utilisé Spring, Spring Boot permet de configurer facilement une application et Spring MVC d’exposer des services REST.
Du fait du choix de la technologie Spring, la mise en place de monitoring demande quelques acrobaties :
Le résultat se trouve réparti dans 5 classes :
Le code en charge de l’envoi des messages est situé dans un projet partagé car il est utilisé par le middle-end et le backend. L’essentiel du code est situé dans le MonitoringMessageSender qui utilise un thread dédié à l’envoi des messages et alimenté par une queue.
RedisProvider a été modifié pour transmettre l’identifiant de correlation dans les messages envoyés au backend.
Il s’agit d’un serveur Redis : il est principalement utilisé comme un cache clé-valeur mais son API lui permet également de servir de bus de messages. Ses principaux avantages sont sa facilité de mise en œuvre et sa vitesse de traitement.
Nous avons simulé une application de traitement de messages à l’aide d’un pool de threads :
Comme le code de réception est spécifique à l’application, le monitoring est complètement intégré au socle applicatif. Pour l’envoi des messages, il s’appuie sur le même projet partagé que le middle-end.
Le composant de Complex Event Processing dépile les messages en provenance des différents modules (frondend, middle-end, backend). Il réalise alors en parallèle l’insertion dans la base de données et la mise à jour d’un état en mémoire. L’évolution de cet état peut générer des alertes qui seront à leur tour persistées dans la base.
Il est implémenté en Java à l’aide du framework d’intégration Apache Camel et se présente comme une application autonome.
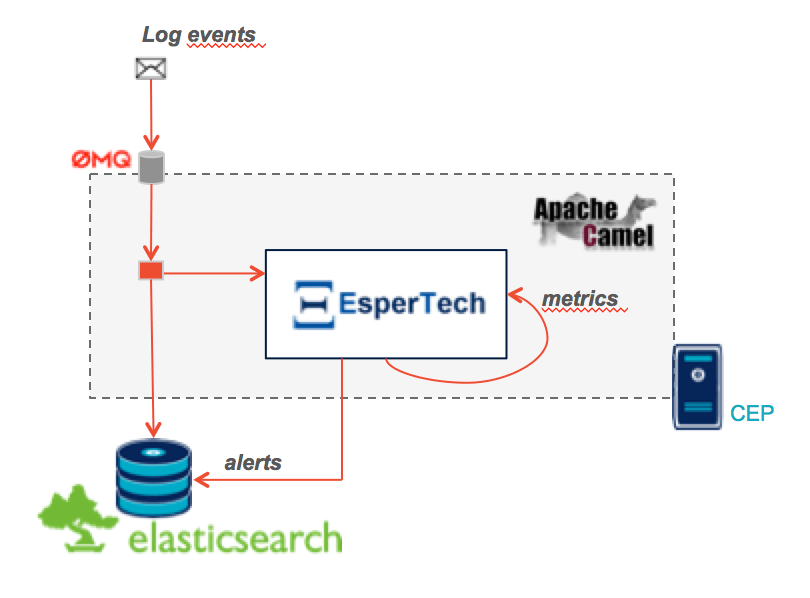
Le flux d’évènements est interprété pour construire des indicateurs en temps réels grâce au language d’analyse Esper Process Language (EPL). Ces statuts sont requêtés à intervalles réguliers afin de détecter des comportements anormaux comme des dépassements de seuils.
Nous avons cherché ici à remonter trois types d’alerte :
elapsed_time des messages.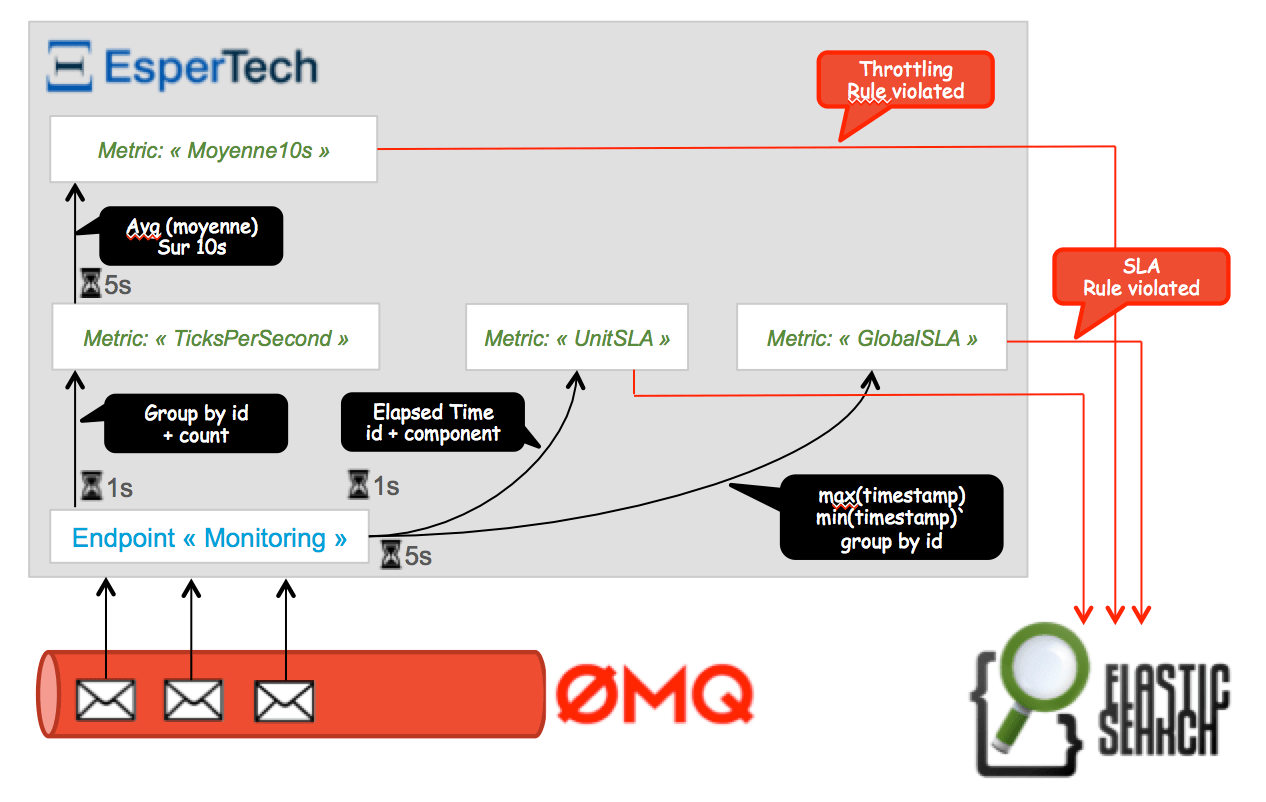
Il s’agit d’une base Elasticsearch qui indexe automatiquement les données à leur insertion. Pour que les données soient indexées au mieux, il suffit de créer un index à l’avance pour que les champs soient indexés de la bonne manière.
Avec les données déjà structurées et stockées dans Elasticsearch, Kibana est la solution naturelle pour les dashboard : des assistants permettent de facilement créer les différents graphiques en fonctions des données présentes dans la base.
Voici par exemple un dashboard des percentiles des appels sur les différents serveurs (la configuration de ce dashboard est disponible dans les sources) :
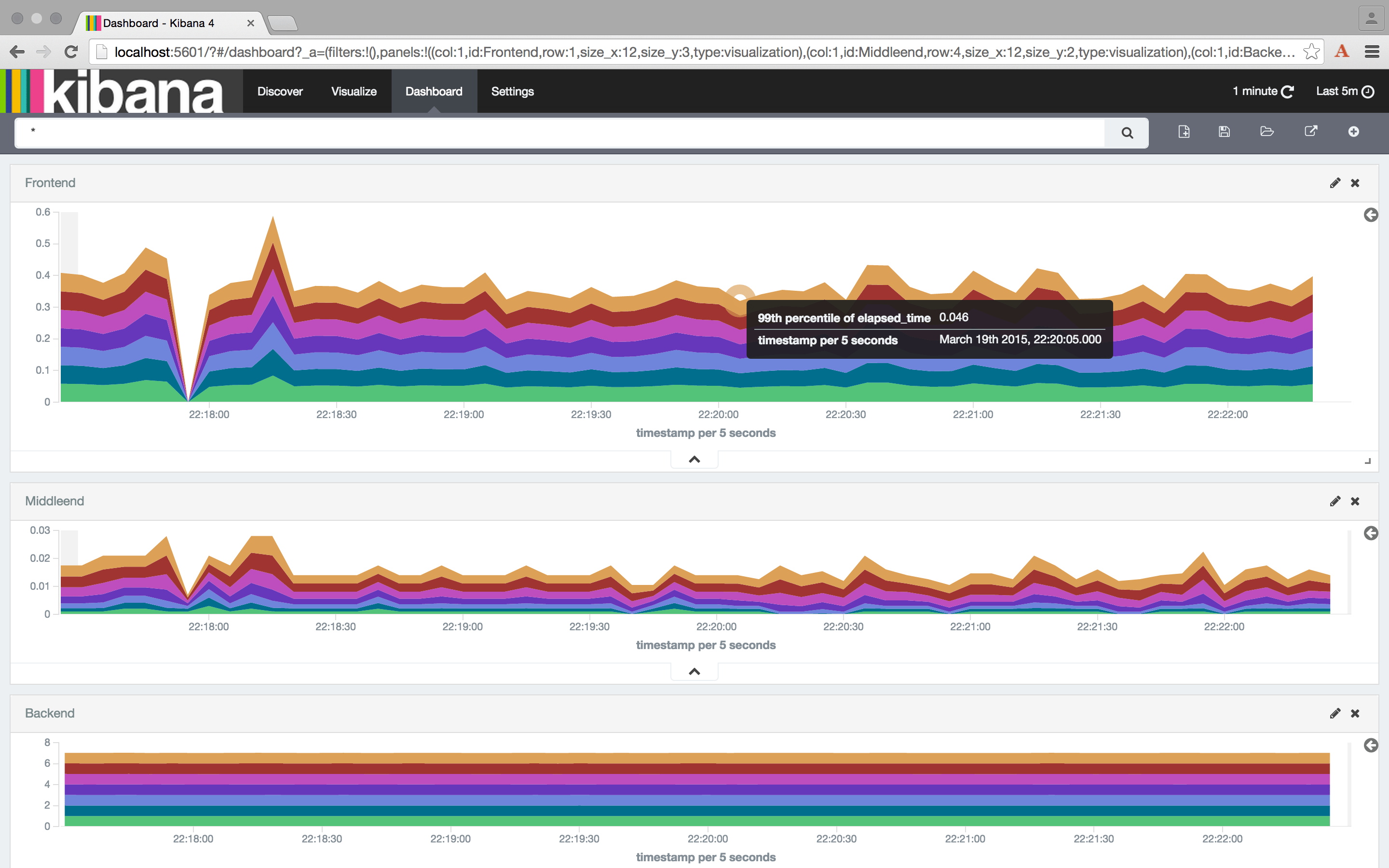
Les cas présentés ici sont favorables car les composants ne sont pas trop compliqués à monitorer, même si le middle-end demande un peu de gymnastique. Malheureusement dans tout SI d’une certaine taille, il existe toujours au moins une brique "boite noire", type portail ou plateforme e-commerce, qu’il est difficile d’outiller convenablement. Pour ces composants deux choix sont généralement possibles :
Cette solution est la plus conforme. Cependant ces API sont souvent d’une qualité inférieure au reste et avant de vous lancer il y a trois choses à vérifier :
En fonction des réponses à ces trois questions, la deuxième solution sera peut-être préférable.
Si les échanges avec le composant se font par http, l’autre solution est de mettre en place un proxy comme nginx pour générer les messages de monitoring. En configurant les logs vous devriez pouvoir obtenir les informations dont vous avez besoin, et un composant custom est nécessaire pour les pousser vers le serveur de CEP.
Cette solution a le désavantage d’ajouter une couche supplémentaire d’infrastructure, mais évite d’avoir à développer du code trop spécifique à un outil.