L’image est depuis maintenant quelques années, l’un si ce n’est le terrain de jeu favori en Deep Learning. Les réseaux de neurones profonds sont devenus si performants dans la reconnaissance d’objets qu’il fallait un nouveau challenge dans le domaine. Depuis quelques mois, nous voyons apparaître des modèles capables de générer des images cohérentes à partir de texte. Cela peut paraître anodin mais demande pourtant de comprendre la cohérence entre les pixels à différentes échelles, une tâche extrêmement compliquée. Après s'être penché sur les CNN, je vous propose dans cet article de jeter un œil dans les coulisses du modèle unCLIP, poulain de l’écurie OpenAI, et pionnier dans la génération d’images. Peut-être le connaissez vous mieux sous le nom de la plate-forme sur laquelle il a été déployé, DALL-E 2.
Comment générer une image à partir de texte ? La question paraît si vague qu’on ne saurait par où commencer.
DALL-E 2 procède en trois étapes.
La première étape consiste à comprendre le texte donné en entrée du modèle. Celui-ci peut être n’importe quoi, tant que la syntaxe est correcte.
Le tour de force est d’extraire l’information d’un texte et de la représenter dans le même espace que l’information d’une image (on parle d’embedding du texte, grossièrement c’est un encodage du texte sous forme d’une liste de nombres). Le lien entre une image et sa légende peut paraître trivial pour un être humain, mais dans les faits comment passer de l’un à l’autre ? Voilà une question extrêmement complexe pour un réseau de neurones.
La seconde étape consiste à transcrire la représentation du texte en représentation d’une image (ou passer de l’embedding du texte à l’embedding d’une image). Celle-ci peut paraître plus abstraite, nous y reviendrons ci-dessous.
La troisième et dernière étape consiste à générer une image à partir de la représentation précédente. Pour cela, DALL-E 2 utilise un modèle entraîné à générer une image à partir d’un encodage de celle-ci (grossièrement un tableau de nombres, le fameux embedding d’image de la deuxième étape).
OpenAI utilise le modèle CLIP pour relier du texte à une image. CLIP est un modèle de vision comparatif. Il permet de déterminer à quel point un texte représente une image. On peut voir cela comme quantifier la pertinence entre une légende et une image. Pour cela, CLIP est entraîné à maximiser un score de pertinence (la cosine similarity) entre une image et un texte quand le texte décrit parfaitement l’image, et à le minimiser quand le texte et l’image n’ont rien à voir.
Afin de comparer un texte et une image, CLIP a d’abord besoin de les transformer en listes de nombres, ce sont les fameux embeddings. Dans le cas du texte, c’est un transformer qui permet d’obtenir l’embedding. Pour l’image, on utilise un vision transformer.
L’entraînement de CLIP se déroule comme suit:
OpenAI a créé un nouveau dataset de paire (image, texte), spécifiquement pour l’entraînement de CLIP. Ce dataset comporte environ 400 millions de paires et a été nommé WebImageText. Il a été constitué à partir de diverses sources publiques, par exemple Wikipedia. Le but est d’avoir une grande variété d’images afin notamment d’augmenter la diversité au sein de DALL-E 2 et de réduire les biais (ethniques, sociaux, etc…).
Une fois le modèle CLIP entraîné, on gèle ses poids et on l’injecte dans DALL-E 2.
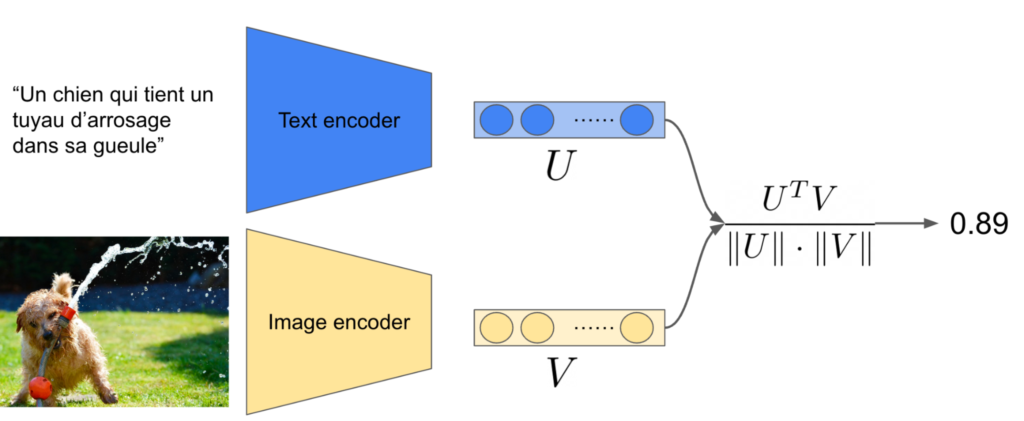
Figure 1: calcul du score de pertinence entre une image et sa légende
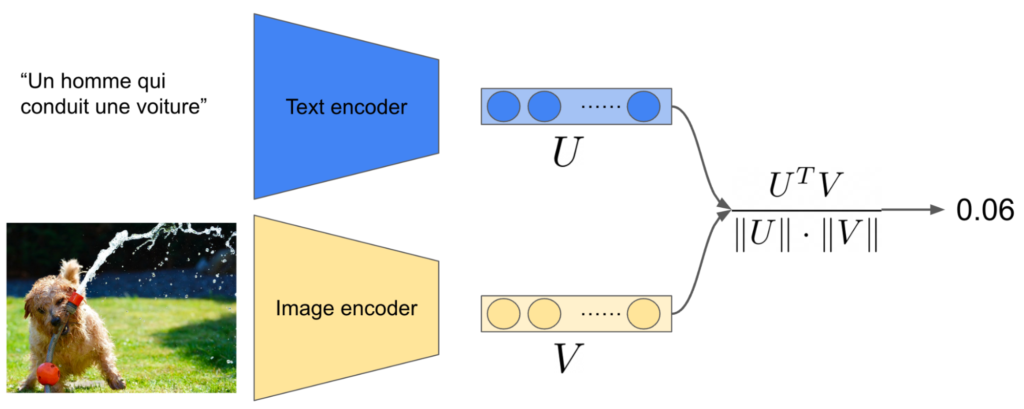
Figure 2: calcul du score de pertinence entre une image et un texte aléatoire
DALL-E 2 prend un texte en entrée. On va donc uniquement se servir de l’encodeur de texte qui a été entraîné dans CLIP. À l’issue de cette première étape, on obtient l’embedding du texte dans un espace où on peut le comparer à l’embedding d’une image.
CLIP permet d’encoder du texte dans un espace latent qui représente “l’information”. Dans cet espace, l’encodage est un vecteur de taille m dans lequel chaque élément représente un concept.
Cependant, DALL-E 2 n’utilise pas directement ce vecteur. En effet, le modèle de génération d'image qu'il utilise (voir l'étape 3) a été entraîné à partir d'embedding d'image, pas de texte. Il faut donc d’abord “traduire” cette représentation de texte en représentation d’image.
Rappelons que CLIP est un modèle comparatif, il permet de comparer l’information d’un vecteur texte à celui d’un vecteur image. Mais il est incapable de transformer l’un en l’autre seul. La seconde étape du modèle consiste donc à "traduire" l’encodage du texte en encodage d’image. Pour cela, OpenAI utilise un modèle de diffusion.
Les modèles de diffusion sont inspirés de la physique, en particulier de la thermodynamique. Ils consistent en deux parties:
Les modèles de diffusion sont donc un type d'encodeur-décodeur. On peut les comparer aux VAE.
Le processus de décodage est aléatoire. Le décodeur ne permet pas de retrouver exactement l’image d’origine mais une image qui lui ressemble (on dit qu’elle partage les mêmes caractéristiques principales). C’est cet aléa qui permet la diversité d’images de DALL-E 2. En effet, si on retrouvait exactement l’image d’origine, le modèle ne renverrait que des copier-coller d’images sur lesquelles il a été entraîné.
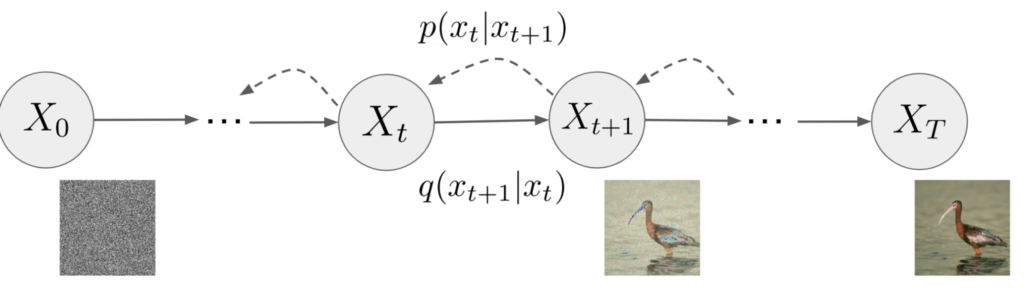
Figure 3: représentation d’un modèle de diffusion
Dans la seconde étape, on utilise donc un modèle de diffusion dont le décodeur est entraîné à générer un embedding d'image à partir d’un embedding de texte. Dans l’article de recherche, ce modèle est appelé le prior. En plus d’un modèle de diffusion, OpenAI a essayé un modèle auto-régressif pour le prior. Il s’avère que le modèle de diffusion donne de meilleurs résultats à taille équivalente et est plus rapide à entraîner.
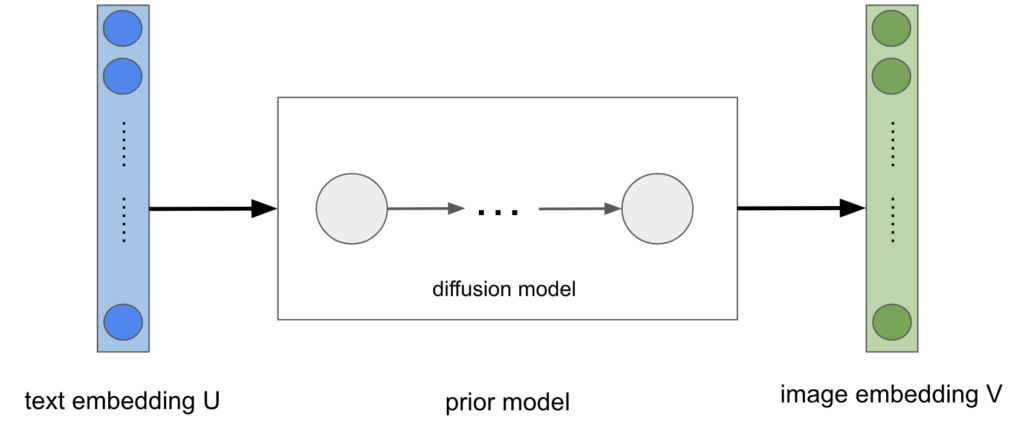
Figure 4: modèle de diffusion prior pour passer de la représentation du texte à celle de l’image
On peut se demander pourquoi cette étape est nécessaire. En effet, elle paraît très abstraite par rapport au reste de DALL-E 2. N'aurait-on pas pu simplement générer une image à partir de l’embedding de texte ?
Les auteurs ont comparé plusieurs approches. Ils ont tenté de générer une image à partir de l'embedding d'image de CLIP, de l'embedding de texte, et à partir d'un texte encodé avec un modèle de type Transformer. Il s’avère qu’utiliser directement l’embedding de texte ou l'encodage produit des images correctes, mais pas aussi bonnes qu’avec l’embedding d’image. Il apparaît aussi qu’utiliser l’embedding d’image améliore la diversité des images générées. Pour plus de détails, voir la partie 5.1 de l’article d’OpenAI en bibliographie.
Une fois le mapping effectué, il reste à générer une image cohérente à partir de l’embedding. À ce stade, on a simplement un vecteur qui contient la sémantique visuelle de l’image, c.a.d les éléments qui doivent être dedans et leurs relations.
Pour cela, DALL-E 2 utilise un autre modèle de diffusion nommé GLIDE. Celui-ci est fondamental dans la génération d'images. Sa particularité est qu’il peut guider le décodage dans un modèle de diffusion. En effet, un modèle de diffusion classique tel que représenté dans la figure 3, ne génère que des images qui correspondent au jeu de données sur lequel il a été entraîné (par exemple, s’il est entraîné sur des images d’oiseaux, le décodeur ne produira que des images d’oiseaux). Si on utilisait ce type de modèle dans DALL-E 2, il en faudrait un pour chaque type d’image qu’on voudrait générer. Vu la diversité de DALL-E 2, la tâche serait impossible.
GLIDE permet d’orienter la génération d’image grâce aux informations de l’embedding d’image_._ Comme nous l’avons vu dans l’étape précédente, le décodage dans un modèle de diffusion est aléatoire. Ainsi à partir du même embedding, GLIDE peut générer une image différente à chaque fois, mais qui conserve les mêmes caractéristiques.
Note: DALL-E 2 utilise une version légèrement modifiée de GLIDE. On conditionne le décodeur de GLIDE sur le texte en plus de le conditionner sur l'embedding d'image.
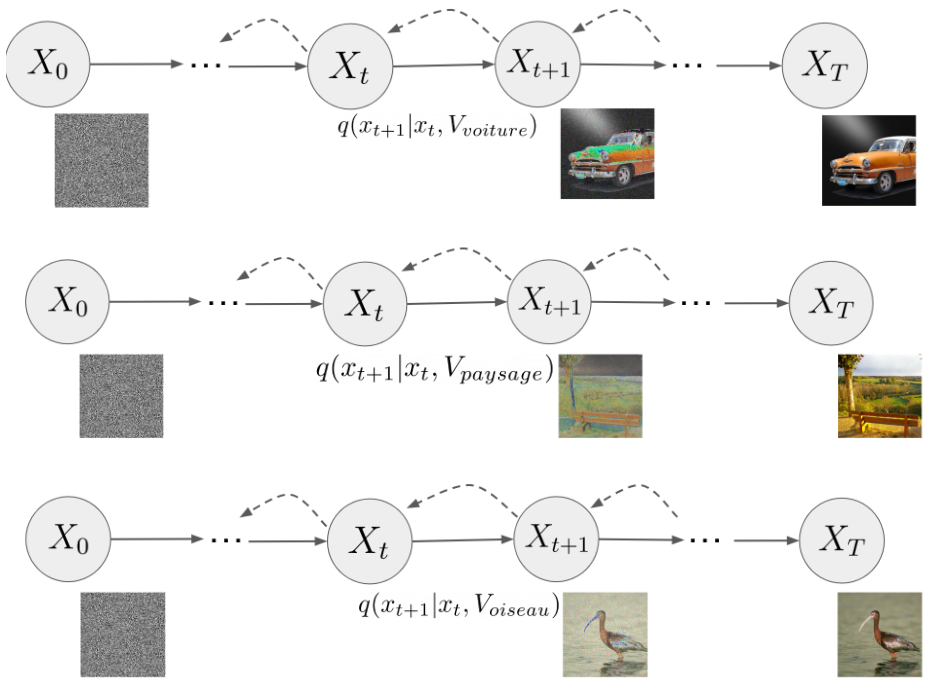
Figure 5: exemples d’images générées par GLIDE avec le conditionnement sur l’embedding (haut: voiture, milieu: paysage, bas: oiseau)
Pour résumer cette première partie, le fonctionnement de DALL-E 2 se décline comme suit:
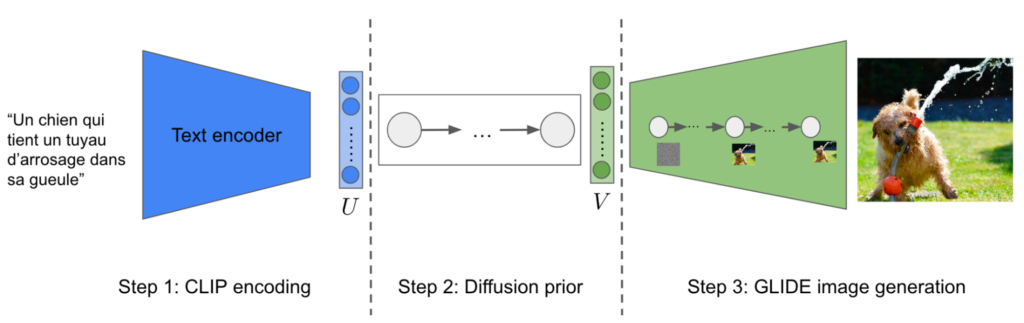
Figure 6: Fonctionnement général de DALL-E 2
L’évaluation d’un modèle comme DALL·E 2 est complexe. En effet, l’appréciation d’une image est hautement subjective.
OpenAI a donc eu recours à des évaluateurs humains pour noter le modèle sur plusieurs axes, notamment photo-réalisme, diversité, et adéquation au texte proposé.
Ils ont également utilisé une métrique objective, appelée FID, qui sert aussi pour l’évaluation des GANs.
Dans la seconde partie, nous verrons les performances du modèle en pratique ainsi que ses limites. Le modèle n’est pas accessible au public mais OpenAI a récemment ouvert une bêta. _UPDATE: L_a beta de DALL-E 2 est maintenant ouverte au grand public !
OpenAI a annoncé plus tôt dans l’année l’accès à la bêta de DALL-E 2 pour un million de personnes. Je me suis inscrit sur la liste d’attente, et depuis le 15 août je fais partie des lucky few ! Dans cette partie je vais vous livrer mes impressions et remarques sur le modèle.
Avant toute chose, je tiens à dire que le modèle est absolument bluffant. J’avais déjà essayé la version mini du modèle (disponible ici) et la version d’OpenAI est à un tout autre niveau. De plus, la génération d’image prend environ 30 secondes, contre presque 2 minutes pour la version mini.
Voici le résultat de DALL-E pour la phrase suivante: “a pink horse on a mountain next to the sea in Brazil":

Figure 7: Comparaison de DALL-E 2 et DALL-E mini - côté DALL-E 2
Et voici le résultat de la version mini pour la même phrase:
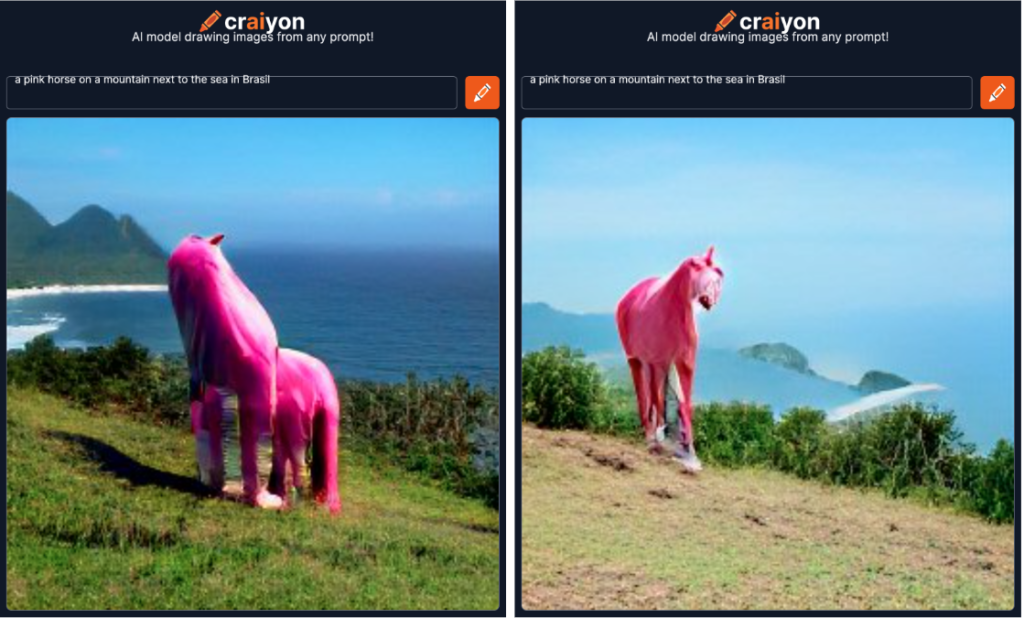
Figure 8: Comparaison de DALL-E 2 et DALL-E mini - côté DALL-E mini
DALL-E 2 produit des images plus détaillées et cohérentes. Même si la version mini intègre tous les éléments, on remarque que le paysage est plus flou et surtout, le cheval est à peine reconnaissable. La cohérence globale des images restent impressionnantes dans les deux cas.
Voici le résultat pour “two sisters playing tennis in wimbledon”:

Figure 9: Performance de DALL-E 2 sur les visages
On remarque d’importants artefacts sur les zones les plus détaillées: le filet, les chaussures, les visages. Cependant j’aimerais revenir sur la difficulté de générer une image. Cela nécessite que le modèle comprennent les différents éléments, ainsi que les liens entre ceux-ci, et les échelles (ex: les humains sont sur le sol, à la verticale, leur échelle est cohérente avec le décor, etc…). C’est une tâche extrêmement complexe que de comprendre la disposition des différentes parties d’un visage (nez, yeux, bouche, oreilles, etc…) entre elles, et par rapport au reste de l’image (contours de la tête, corps, autres personnages, décors). DALL-E parvient à produire des images à la fois cohérentes globalement (tous les éléments sont là bien disposés entre eux) et localement (le maillage du filet est bien en grille, les visages sont relativement cohérents).
Cependant, le modèle n’est pas parfait et il est relativement simple de le pousser dans l’erreur.
Voici le résultat du modèle pour la phrase “a plate on a table in a summer field with absolutely no bananas on it”:

Figure 10: Limites de DALL-E 2 sur les négations
À la surprise générale, l’assiette contient des bananes malgré notre insistance. En effet, la prise en compte des négations est un problème classique en traitement du langage naturel, auquel DALL-E ne fait pas exception. Globalement le modèle est très bon pour comprendre ce qu’il y a dans l’image, mais pas pour comprendre ce qu’il n’y a pas.
En voici d’autres exemples:

Figure 11: Génération de DALL-E 2 avec la phrase “a fruit plate with neither bananas nor oranges in it”

Figure 12: Génération de DALL-E 2 avec la phrase “a diner table with anything but bread and turkey”
Comme beaucoup de modèles de NLP, DALL-E 2 échoue à comprendre les négations. Dans le cas de la table, il est incapable d’extrapoler proprement en dehors des éléments que nous lui donnons. On voit là une différence fondamentale entre les humains et les réseaux de neurones artificiels, l’imagination.
En dehors des négations, la rétention d’information sur le long terme est un autre défi du traitement du langage naturel. Testons DALL-E avec la phrase suivante: “a couple on a beach in hawaii, he is wearing a white shirt and she is wearing a blue dress, he has a red hat, she has golden shoes, he holds their bag”

Figure 13: Performance de DALL-E 2 avec beaucoup d’éléments de contexte et détails
Globalement, le modèle comprend les concepts principaux: il y a un couple, sur une plage, il y a une robe et un t-shirt, et les couleurs demandées. C’est dans les détails et l’attribution que le modèle a du mal. Les couleurs ne sont pas attribuées aux bons objets, ce n’est pas forcément l’homme qui porte le sac, etc…
Le modèle a des difficultés à relier objets, couleurs et pronoms dans la phrase. De même, le modèle peine à se “souvenir” des éléments en début de phrase, comme illustré dans l’exemple suivant: “a dog as an astronaut in space next to the international space station in a synthwave fashion with a red collar”

Figure 14: Performance de DALL-E 2 avec de l’attention
Le collier rouge est passé à la trappe, alors que dans le cas simple “a dog with a red collar”, il n’a aucun mal à s’en “souvenir”:

Figure 15: Génération de DALL-E 2 avec la phrase “a dog with a red collar”
DALL-E 2 est l’un des premiers modèles de génération d’images à faire autant de bruit. Ce domaine de recherche semble être la nouvelle obsession des laboratoires, car de nombreux autres lui ont emboîté le pas, notamment imagen chez Google Brains quelques semaines plus tard, ou encore Stable Diffusion de Stability AI. On peut aussi citer MidJourney, dont le modèle a récemment gagné un concours d'art.
Comme ils l’avaient fait avec GPT-3, OpenAI ouvre la voie avec des résultats bluffants. Même si DALL-E 2 souffre encore des inconvénients classiques en traitement du langage naturel et d’artefacts dans les zones les plus détaillées, il n’en reste pas moins impressionnant dans la cohérence des images, leurs variétés, et leur réalisme.
Avec de multiples champs d’applications (graphisme, publicité, rendu 3D, etc…), les modèles de génération d’images ont un bel avenir devant eux. Cependant, il convient d’être prudent quant à leur utilisation (ex: détournements pornographiques) et aux biais dont ils peuvent être victimes.