Obtenir un jeu de données pour l'entraînement de son modèle de machine learning dans un cas d'usage donné reste encore aujourd'hui très difficile. Beaucoup sont issus de travaux réalisés et mis à jour par des communautés (universitaires, centre de recherches, instituts spécialisés…) impliquant un coût non négligeable de collecte des données.
De plus, les entreprises du secteur de l’industrie ne voient plus l’intelligence artificielle (IA) comme étant une technologie expérimentale, réduite au stade de la recherche, mais bien comme un outil déployable sur leur ligne de production permettant d’optimiser les performances de leurs systèmes.
Construire un modèle d’apprentissage automatique nécessite un jeu de données le plus complet et harmonisé possible.
Une problématique souvent observée lors du traitement d’images comme jeu de données est la difficulté d’ajouter des annotations, c’est ce que l’on appelle la « labellisation ». Dans le cadre de détection d’objets, l'apprentissage supervisé nécessite d’ajouter des métadonnées à l’image afin de pouvoir entraîner le modèle à réaliser la détection.
Cela consiste à préciser des informations comme le « où » et le « quoi » de la donnée. Pour une photo, on décrira où se trouve l’objet représenté et la nature de l'objet afin de le différencier.
Cette phase est considérée comme longue, routinière, sujette à l’erreur humaine et coûtant extrêmement cher en ressources spécialisées. Les experts qui savent annoter ces milliers d'images sont rares et leur temps est coûteux.
Aujourd'hui nous vous proposons un retour d'expérience sur le développement d’un POC démontrant qu’il est possible d’entraîner une IA pour la détection d’objets sans données issues du réel. Autrement dit détecter des images réelles (test on real) à partir d'un entraînement sur des données artificielles (train on fake). Dans le cadre de l’utilisation d’un robot autonome se déplaçant sur un site industriel, le flux vidéo remonté par la caméra du robot doit permettre de détecter des manomètres sur son passage. N'ayant pas la possibilité d’accéder à un site industriel afin de récolter un échantillonnage important de photos pour la construction d'un jeu de données, nous avons dû trouver une autre solution pour le générer que nous allons développer dans la suite de cet article.
Nous pourrions aux premiers abords être sceptique quant aux résultats d'une IA pour la détection d'objets en conditions réelles uniquement entraînée avec des objets synthétiques. Des études, dernièrement, se penchent sur la pertinence de ces résultats.
Selon un rapport Gartner, en 2024, 60 % des données utilisées pour le développement d’intelligence artificielle seraient ainsi générées synthétiquement. De nombreux secteurs s’ouvrent ainsi à cette utilisation, comme le milieu médical pour aider à la détection de maladies sans avoir recours aux données sensibles de leurs patients.
Dans notre cas de POC, nous sommes confrontés à deux problématiques : récolter des milliers d’images puis les labelliser. Face à ces deux problématiques, nous nous sommes tournés vers la création d'un environnement en 3D réaliste et le plus proche possible de l'environnement industriel du client.
Nous avons alors réalisé une prise de contexte via des interviews avec plusieurs corps de métier du site industriel. Nous avons agrémenté notre recherche avec des vidéos, des prises de photos du site et des collectes d'éléments 3D déjà en possession du client.
La volumétrie de ces données (photos et vidéos) ne sont malheureusement pas suffisantes pour l'entraînement d'un modèle de ML, mais elles nous permettent d'avoir suffisamment de contexte pour recréer ce site industriel en 3D.
Si nous partons du principe que le modèle de Machine Learning est réalisable alors la création d'un environnement réaliste 3D présente quatre grands avantages :
Nous avons utilisé le moteur de rendu 3D Unity afin d’intégrer le modèle virtuel du site basé sur les différentes informations recueillies.
Dans le cas d'usage de notre POC, la détection de manomètres en milieu industriel, la labellisation consiste à récupérer la position dans l'espace des manomètres.
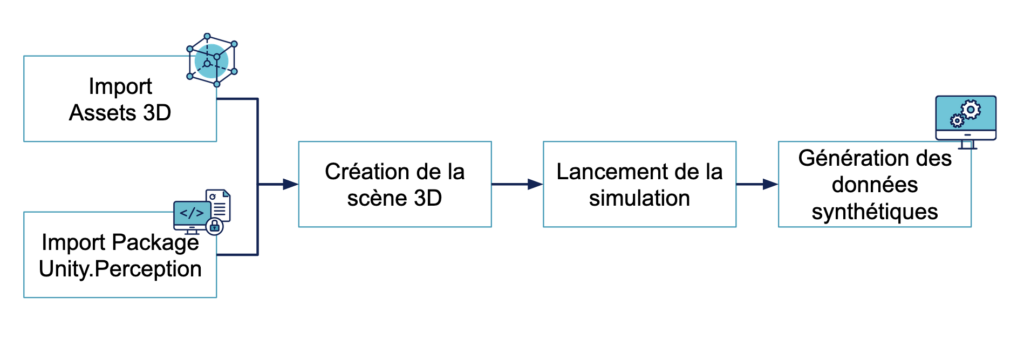
Une solution simpliste serait de programmer manuellement les différents cadres (bounding boxes) entourant nos manomètres. Les coordonnées dans l’espace des cadres seraient fixes, et permettraient de déterminer la localisation des différents objets à détecter.
Cette approche avec des coordonnées statiques n'étant pas optimale car la modification des emplacements des manomètres serait alors réalisée manuellement, cela n'offre pas une bonne maintenabilité. Nous préférons une approche plus automatique pour proposer une certaine industrialisation de notre code afin de s'adapter facilement au contexte d'un autre scénario de tests ou d'un autre cas d'usage.
Un package Unity sorti en 2020 apporte une solution applicable à tout type de projet, il s’agit de Perception. Cet outil permet de générer des datasets synthétiques labellisés automatiquement. Comment fonctionne-t-il ? Dans un premier temps, il faut assigner à chaque manomètre un script fonctionnant comme un tag pour le labelliser automatiquement lorsqu’il est présent dans le champ de vision de la caméra. Puis, il faut rajouter le script principal à la caméra permettant la configuration de Perception et la détection de ces objets 3D. Ainsi en lançant la simulation de la scène, notre caméra est capable de percevoir les objets à détecter et de lancer le processus de labellisation en direct. Nous pouvons observer sur Unity lors de ce processus de labellisation l’apparition de cadre 2D entourant l’objet, appelé bounding box.

Nous avons déterminé le chemin parcouru par la caméra au sein de l’environnement le long duquel nous avons ajouté des manomètres tels qu’ils pourraient être placés dans un cadre réel. A partir du flux vidéo obtenu, chaque image est sauvegardée dans un dossier ainsi que les différentes annotations associées (par exemple la position et taille du cadre dans l’image). Nous sommes alors capables d’extraire les informations de ces fichiers pour alimenter notre modèle de machine learning. Dans Unity nous pouvons personnaliser l'extraction des images au bon format pour l'équipe IA (416 x 416 pixels) et ne retourner dans un fichier JSON que les données intéressantes pour le modèle, ici la position et la taille de la bounding box (les bounding box sont en 3D et nous détectons les coordonnées en 2D en fonction de la position de la caméra).
Perception propose également des fonctions prédéfinies appelées Randomizer permettant de générer un scénario de simulation aléatoire. Il est possible de générer aléatoirement la position, la rotation, la couleur des objets et de faire varier la luminosité de l’environnement virtuel. Si ces fonctions ne suffisent pas, il est possible également de créer ses propres fonctions de randomisation.
Notre modèle de ML peut alors profiter d'une grande variété des données reposant sur de multiples scénarios réalistes.
Le package Perception est encore en phase de preview, il n’est pas officiellement validé par Unity et ne possède donc pas encore de support. Il en reste très prometteur et répond au besoin de génération de dataset synthétique labellisé.
Cependant, nous avons été déçus par la performance de notre premier modèle réalisé avec les textures d’arrière-plan aléatoires proposés par défaut lors de l’installation de Perception.
Face à un nombre important d'acteurs (développeurs Unity, 3D designers, une équipe IA et une équipe métier) il est important d'établir une bonne collaboration avec une boucle de feedback efficace et rapide pour garantir la fiabilité du modèle de ML avec l'amélioration continue. La phase de génération du dataset est la plus déterminante dans notre PoC et repose sur la méthode empirique suivante.
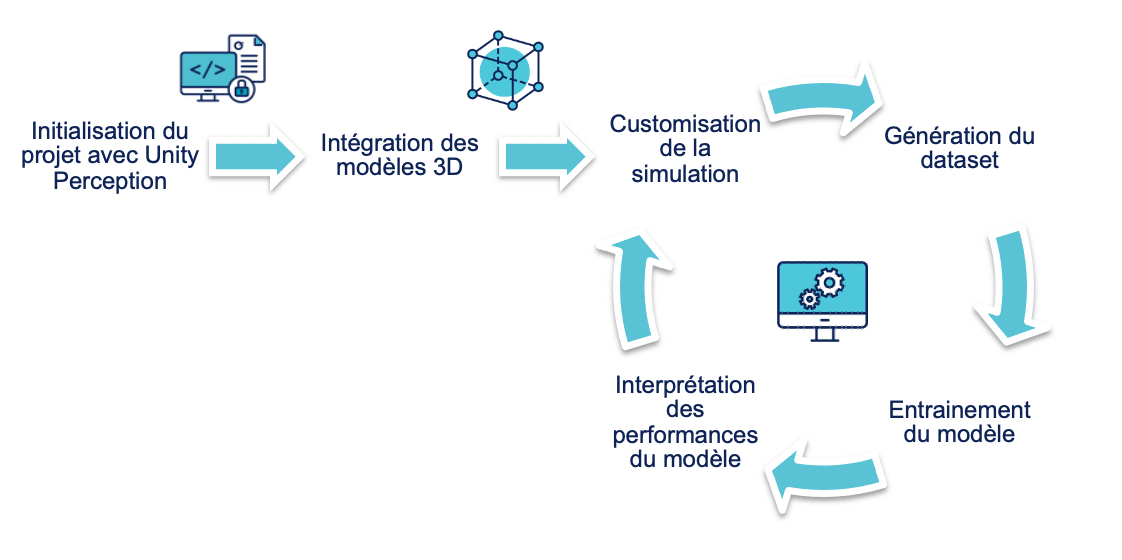
Le projet s’est réalisé en deux grandes phases suivant le même cycle de production :
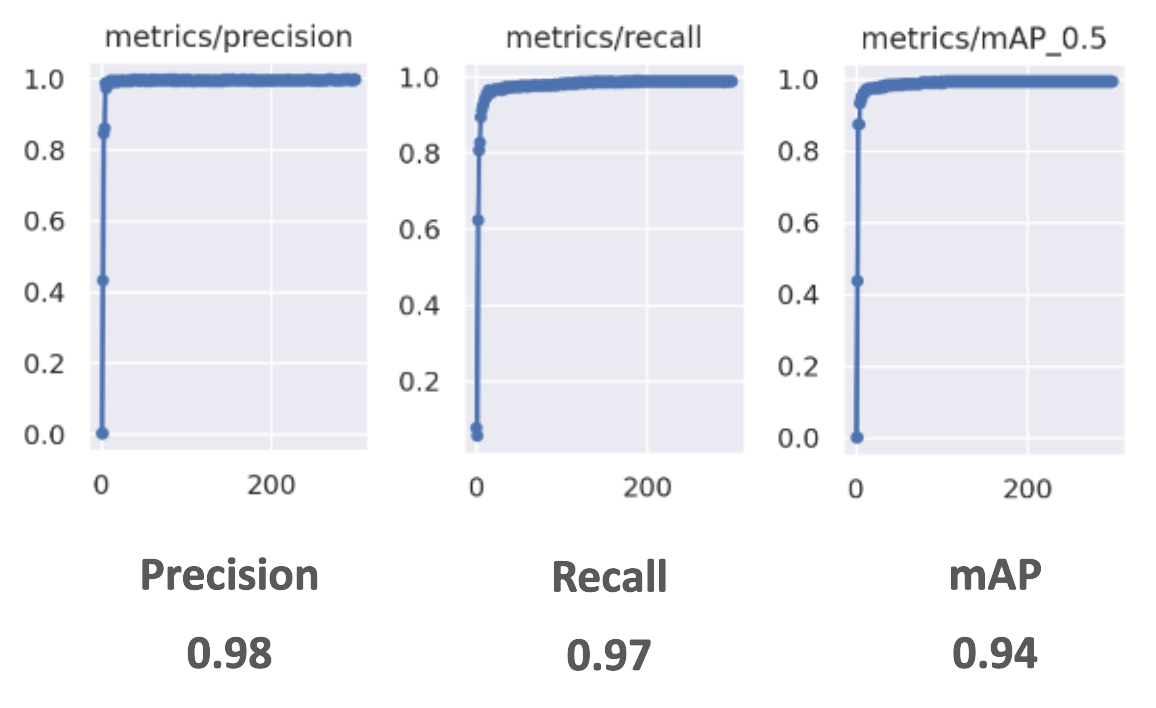
L’obtention des feedbacks avec l’équipe IA se base essentiellement sur les mesures de performance suivantes appliquées à la vidéo de test :

Au cours de ce PoC, nous n’avons eu que les ressources pour faire les tests sur des vidéos issues d'une captation d'un autre chemin de notre environnement 3D (test sur fake). Cependant, dans un objectif de mise en production de ce modèle, il aurait été nécessaire d’effectuer également les mesures de performances sur des vidéos réelles du site industriel (test sur réel). Dans notre cadre d’études, nous nous sommes contentés de détecter les occurrences de faux positifs (le modèle détecte un manomètre alors qu’aucun n’est présent) et faux négatifs (le modèle ne détecte pas les manomètres présents) obtenus et suggérer des causes potentielles.

Avec l'aide des mesures de performance du modèle, des axes d’amélioration peuvent être proposés pour modifier la génération du jeu de données d'entraînement. Il a été également possible d’étudier le comportement de notre modèle sur quelques environnements réels à l'aide de vidéos du milieu industriel. Par exemple, nous avons modifié la bounding box pour qu’elle n’entoure plus que le cadran par rapport à l’entièreté du manomètre. Sur les vidéos réelles, on pouvait remarquer que le modèle détectait mal le manomètre si la fixation de celui-ci n'était pas visible.
Cette boucle liée à l’entraînement du modèle ML et à la réception des feedbacks a une durée incompressible. Avant de conclure, nous vous proposons dans le prochain chapitre de vous montrer en détail nos différentes itérations avec, pour chacune, un exemple d'image issue du jeu de données généré.
Tout d’abord en déterminant les caractéristiques fondamentales du dataset. Nous avons convenu avec l'équipe IA de la résolution souhaitée pour les photos (416 x 416 pixels). Chaque photo doit être accompagnée d’un fichier possédant la liste des différentes positions et tailles de bounding box pour chaque manomètre présent.
La réalisation du premier dataset utilisant les fonctionnalités basiques du package Unity Perception, l'arrière-plan est constitué de textures aléatoires avec une variation de la position et rotation des manomètres.
Les résultats se sont montrés insatisfaisants avec une précision de seulement 0.65. Notre prochaine itération testera avec un arrière-plan réaliste pour améliorer la détection des manomètres de notre modèle.
Cette fois-ci l'arrière-plan est remplacé par des photos ressemblant au milieu industriel. Nous avons alors observé une amélioration de la précision de la détection des manomètres lorsque ceux-ci contrastent avec l’image en arrière-plan, mais également l’apparition de nombreux faux positifs sur le test avec la vidéo réelle. Nous remarquons ainsi la nécessité d'intégrer davantage les manomètres avec l’arrière-plan.

Nous sommes parvenus ainsi à atteindre une précision de 0.75 grâce aux différents ajustements. Cependant, pour notre PoC, nous souhaitons viser une précision supérieure à 0.90. Nous pensons que nous devons encore modifier l'arrière-plan et vérifier si cela peut permettre une meilleure précision du modèle.
La nécessité de dynamiser l'arrière-plan nous conduit à la réalisation d’un chemin vidéo grâce au package Unity Cinemachine. Cet outil permet la réalisation de prises de vue dynamiques, intelligentes et sans code. Pour la réalisation du travelling, Cinemachine au travers d'une timeline permet d’alterner les points de vue de la caméra avec des logiques de zoom à proximité des manomètres.
Cette étape a été très significative dans l’amélioration de notre dataset. Les résultats du modèle sont plutôt bons lors de la détection des manomètres sur des jeux de test vidéo ainsi que sur notre parcours de test en 3D. L’utilisation de Cinemachine a grandement amélioré la qualité des différents angles de vue autour du manomètre et a permis au modèle de s’entraîner avec un environnement virtuel réaliste.


Pour la dernière itération de notre génération du dataset, nous avons finalement atteint une très bonne précision pour notre modèle sur la détection des manomètres entraîné sur des données synthétiques.
La création d'un environnement virtuel 3D réaliste répond à la difficulté de rassembler suffisamment de données d'entraînement spécifiquement appliqué à un cas d'usage non générique ou rare (site inaccessible, simulation d'incidents, variation des conditions climatiques, …).
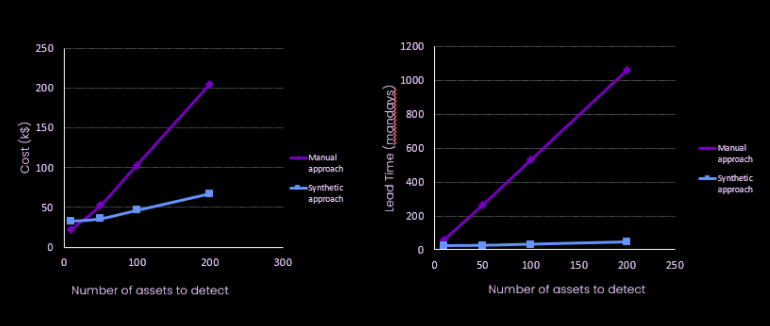
De plus, la donnée synthétique réduit drastiquement le coût humain et financier de la génération et de la labellisation d'un dataset en permettant d’automatiser cette dernière pour des nouveaux objets à détecter. Le coût initial de développement permet par la suite d’ajouter autant d’assets possibles.
Nous avons particulièrement apprécié l’utilisation combinée de Perception et Cinemachine dans Unity, que nous avons trouvé complémentaires. Cinemachine permet d'étendre les capacités de Perception en autorisant une grande variété d’angles de vue autour de l’objet à détecter qui est similaire à notre cas réel, un flux vidéo filmant l’objet et devant le repérer.
Il est primordial de garder en tête que l'étape de génération du jeu de données empirique nécessite une bonne communication entre les équipes IA et Unity 3D, les deux équipes ayant une forte expertise avec un lexique très propre à leurs domaines. Par moment l'équipe 3D a pu manquer de compréhension vis-à-vis des performances du modèle. Certaines propositions d’évolution de l’environnement 3D ont été préconisées par l'équipe 3D sans conviction de l'amélioration des performances. Il est recommandé de prêter une grande attention à la vulgarisation et de présenter les hypothèses en s'appuyant sur des heatmaps, matrices de confusion, etc. afin de sensibiliser chacun sur l'effort apporté lors de la nouvelle itération de création du dataset.
Avec plus de temps, nous aurions également pu pousser plus loin les capacités offertes par le moteur Unity avec une intégration de variations météorologiques plus complexes (pluie, orage, ...) ou des simulations d'incidents difficilement reproductibles en conditions réelles.
Pour aller plus loin:
Un article co-écrit avec Alice Haupais et Kévin Galleron