Après l’arrivée des opérateurs Kubernetes comme moyen d’étendre le comportement interne de Kubernetes, un faisceau de réflexions émergent autour d’une même idée : celle que l’API Kubernetes pourrait finalement devenir la seule et unique API permettant de gérer intégralement son SI, venant abstraire tous les autres types de ressources qui le composent.
Il est désormais acquis que les administrateurs K8s vont vraisemblablement ajouter dans leurs clusters des services à forte valeur ajoutée : cluster de bases de données (SQL ou NoSQL), de traitements distribués (Airflow, Spark…). Les CRD (Custom Resource Definition) et des opérateurs sont une réponse très intéressante, même si ambitieuse. La gestion des cycles de vie des opérateurs eux-mêmes, du monitoring, des sauvegardes restent de très forts points de vigilance.
Désormais, on en vient à envisager d’utiliser l’API de Kubernetes (étendue avec d’autres CRD) pour piloter des ressources externes à Kubernetes. Étudions donc cette idée sous quelques axes. 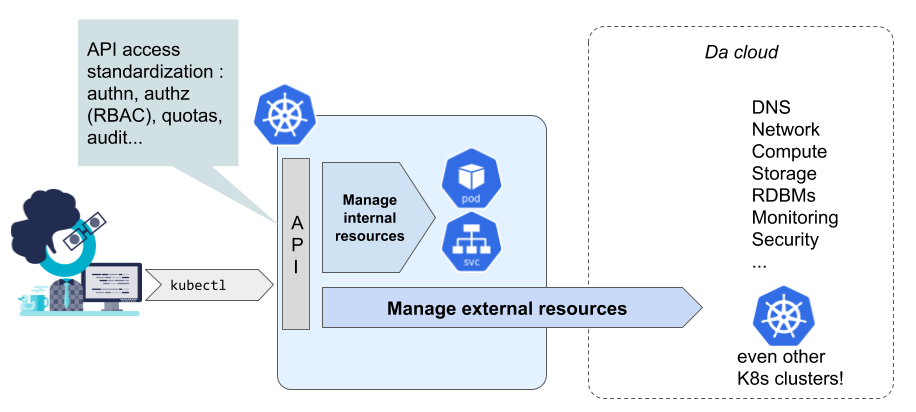
Voici quelques exemples de ressources externes qui peuvent être directement gérées au travers de Kubernetes. Elles sont triées suivant le niveau de disruption qu’elles apportent.
Pour commencer, il faut bien se rendre compte que dans un environnement cloud, un cluster Kubernetes a déjà tendance à manipuler des composants externes : les LoadBalancers cloud (lors de la création de services éponymes) et les volumes (souvent au travers du couple PV/PVC).
Ce n’est donc pas complètement irrationnel d’envisager cette idée qu’un cluster K8s pourrait avoir la capacité à sortir stricto sensu de son cadre.
External-DNS est une solution qui a rapidement été adoptée par la communauté car elle permet de déclarer des enregistrements DNS en fonction des services ou des ingress créés dans K8s. L’implémentation permet de s’intégrer avec une vingtaine de technologies différentes à ce jour, même si encore peu sont considérées comme stables.
Citons à présent comme exemple OPS kube DB operator. Son objectif est de permettre l’allocation de ressources type AWS RDS simplement en manipulant une CRD dans Kubernetes :
❯ cat db.yaml apiVersion: myob.com/v1alpha1 kind: PostgresDB metadata: name: example-db namespace: my-namespace spec: size: "db.t2.small" storage: "10" ❯ kubectl apply -f db.yaml
De premier abord, on pourrait croire à un opérateur Kubernetes classique qui instancie des StatefulSets et de pods dans un cluster K8s, mais il s’agit bien de tout autre chose. La base de données est créée extra-cluster, sans devoir faire l’usage de la console ou du CLI AWS, ni de Terraform.
Google propose KCC comme une solution pour exposer dans l’API K8s des ressources GCP de tout poil. Ici, passage à la vitesse supérieure puisqu’il existe des dizaines de types de ressources Cloud GCP, de la règle de Firewall, aux instances type SQL, Spanner, Redis BigTable…
Côté AWS, deux projets implémentent la même initiative : AWS Service Operator et AWS Service Broker. À noter que ce dernier a une ambition plus large que Kubernetes : implémenter Open Service Broker API Specification. Il s’agit d’un projet tendant à standardiser l’approvisionnement de ressources cloud dans un autre système, dont Kubernetes (au moyen du catalogue de service).
L’intérêt, vous l’aurez compris, est de provisionner toutes les ressources directement depuis vos pipelines CI/CD au moment du déploiement de l’application, avec les même manifestes YAML K8s.
Derrière ce titre surprenant se cache l’idée qu’un cluster Kubernetes d’administration pourrait permettre de piloter d’autres clusters Kubernetes, externes. La cluster API est une abstraction relativement identique à d’autres solutions comme Rancher 2 par exemple. Il devient alors possible de créer, mais aussi gérer sur la durée des clusters Kubernetes simplement en manipulant des ressources avec kubectl.
Charge à différentes implémentations de réaliser le lien avec les fournisseurs cloud (ou on-premise comme le projet Pacific de VMWare) pour faire les opérations techniques sous jacentes. L’approche est agnostique en modélisant sous forme de CRD des concepts génériques (Cluster, Machine, MachineSet, MachineDeployment).
On peut en effet légitimement se poser la question : qu’a-t-on à gagner à tordre (de premier abord) l’API d’un gestionnaire de conteneurs pour lui faire supporter tant de choses ? Un élément de réponse pourrait se résumer ainsi : K8s dispose de qualités intrinsèques qui en font un bon candidat. Voyons cela plus en détails.
La consommation de ressources dans Kubernetes se fait dans un cadre généralement pensé pour l’entreprise :
Sans revenir sur le principe de l’API aggregation et les CRD, rappelons simplement qu’ajouter des nouveaux types d’objets dans K8s est possible par construction, avec une capacité à versionner et optionnellement contraindre le schéma de ces nouveaux objets. Des SDK de plus en plus aboutis permettent de développer des opérateurs. Le déploiement des opérateurs est prévu pour profiter des mécanismes natifs de K8s : mise en haute-disponibilité sous forme de Deployment, gestion des permissions des opérateurs en utilisant des ServiceAccounts et les permissions RBAC associées...
Pour finir et sans grande surprise, évoquons la pénétration de Kubernetes. Sans aller jusqu’à parler de l’API universelle, les promesses de portabilité et de réversibilité de K8s en font clairement une brique vouée à apparaître de plus en plus souvent, dans des contextes cloud et on-premise. Nous rencontrons K8s souvent, croisons chaque jour davantage de personnes familières avec son utilisation et son administration.
Pas de mauvaise surprise a priori. Au pire, pour manipuler des ressources non standard, il est nécessaire de connaître le schéma de CRD qui auraient été installées dans le cluster. La mécanique est bien huilée. Le client kubectl est le dénominateur commun que l’on trouve dans toutes les situations, comme l’étaient ssh et le bash sur les VMs il y a quelques années. Que l’on utilise Helm ou non le formalisme des ressources en JSON ou YAML est connu.
Quand on a pris l’habitude de déployer ses manifestes dans Kubernetes, on peut assez rapidement imaginer le confort d’appliquer ce principe à tout. Il pourrait être très pratique de déployer dans un même manifeste YAML des ressources d’une application dans son intégralité, que lesdites ressources soient internes ou externes à Kubernetes. Les projets disposent d’une vision unifiée, dans un seul chart Helm si on pousse le raisonnement jusqu’au bout.
Inutile de faire une partie des déploiements dans K8s et une partie avec Terraform pour approvisionner d’autres ressources managées sur le cloud. Un point unique, une méthodologie de déploiement unique, qui abstrait en partie la façon dont les ressources sont réellement approvisionnées.
À date, et même si beaucoup d’implémentations sont encore expérimentales, il est important de se demander s’il faut se méfier de cette tendance. Les arguments précédemment cités, s’ils restent valides, ne doivent pas masquer de réelles questions de gouvernance des API de son SI.
Voici donc quelques questions pour résumer notre sentiment qui, à ce jour, n’est pas franchement tranché.
La réponse semble plus opportuniste que réellement étayée : il est assez simple de tirer profit d’un composant déjà (ou bientôt) présent dans les SI. Mais cela ne présume pas que le degré d’abstraction des ressources, ni que le nombre et la localisation des clusters K8s soient les bons.
Le succès des API REST laissent à penser que oui, il est possible de représenter des opérations même complexes simplement à base de verbes classiques des CRD : list, get, create, update, patch, delete. Mais dès que l’on souhaite reproduire des workflows de provisioning complexes notamment avec des étapes de validation manuelle, ils seront problématiques à implémenter. Deux options sont alors possibles :
Le travail de développement d’un opérateur K8s reste cependant éminemment technique. Pour être fonctionnellement complet, il faut envisager que cet opérateur soit également un ValidatingWebHook. Cela lui permettra d’interdire pour des raisons fonctionnelles les opérations (create, update, delete…) sur les ressources. Même si le cadre est présent et permet une bonne productivité, nous ne devons pas sous-estimer le coût et les compétences requises. Un opérateur K8s est nécessairement asynchrone, cohérent à terme, idempotent, autant de principes qu’il est parfois laborieux d’implémenter.
La réponse de normand s’impose : oui et non. Si votre code Ansible a pour but de déployer des applications et approvisionner des ressources sur le cloud, la réponse est probablement oui. Votre quantité de code Ansible va fondre comme neige au soleil.
En revanche, il reste probablement quelques ilôts de résistance où Ansible garde son sens : lorsque les besoins sont si spécifiques qu’il n’existe pas de service managé pour y répondre et que la conteneurisation dans K8s ne peut être la solution. Il est alors nécessaire de re-basculer vers une approche IaaS plus conventionnelle, et utiliser Ansible pour l’installation la configuration voire l’orchestration de middlewares et d’applications spécifiques.
Les plus énervés d’entre nous pourront toujours rétorquer que rien n’empêche un opérateur de lancer du code Ansible, faire des connexions SSH...
C’est en effet un risque réel. Cependant, il est contrebalancé par deux éléments majeurs :
Indépendamment de la pertinence ou non d’utiliser K8s pour exposer des API tierces, la finalité d’aller vers plus d’API d’infrastructure pour son SI est parfaitement louable et doit être poursuivie. Si l’adoption de Kubernetes comme un socle pour ces API permet d’accélérer leur mise en place, le jeu semble en valoir largement la chandelle.