En mission, nous rencontrons de plus en plus des besoins d'interprétabilité. Ce changement est dû à une évolution de la maturité des organisations sur la data science.
En caractérisant un peu le trait, hier les projets de data science étaient surtout marketing (Ex : prédiction d'appétence ou d’attrition à des fins de ciblage). Ils étaient faits à partir de données versées dans un datalake avec des processus plus ou moins maîtrisés. Ces données étaient manipulées et transformées de manière plus ou moins rigoureuse. L’objectif principal était de prouver la valeur de la data science.
Aujourd’hui, la valeur de la data science a été prouvée. Le marché est entré dans une phase d’industrialisation et de généralisation : usages quotidiens et nouvelles applications. Les nouveaux cas d’usages concernent maintenant la loi, la police, la santé, la voiture autonome. Ils ont un impact de plus en plus important sur la vie des humains.
Ces nouveaux usages à fort impacts poussent les utilisateurs et les régulateurs à être plus exigeant vis-à-vis des processus de data science. Leurs exigences sont multiples. On peut citer la disponibilité des modèles, la performance et plus particulièrement l’interprétabilité que nous allons traiter dans cet article. Nous nous intéressons à celle-ci car elle est nécessaire pour avoir confiance dans les systèmes de data science.
Cet article va d’abord proposer d’affiner la question de l’interprétabilité. Ensuite, nous verrons pourquoi les systèmes de data science sont souvent considérés comme pas ou peu interprétables. Enfin nous proposerons des pistes de solutions.
Nous allons le voir, le besoin d’interprétabilité concerne tous les projets de data science. Cependant, chaque projet va avoir des attentes différentes. Pour les identifier précisément, nous proposons les 4 questions suivantes : pour qui ? pourquoi ? quoi ? et sous quel effort ?
L’interprétabilité concerne l’ensemble des personnes qui interagissent avec le système de data science. Elles peuvent être regroupées en 4 catégories.
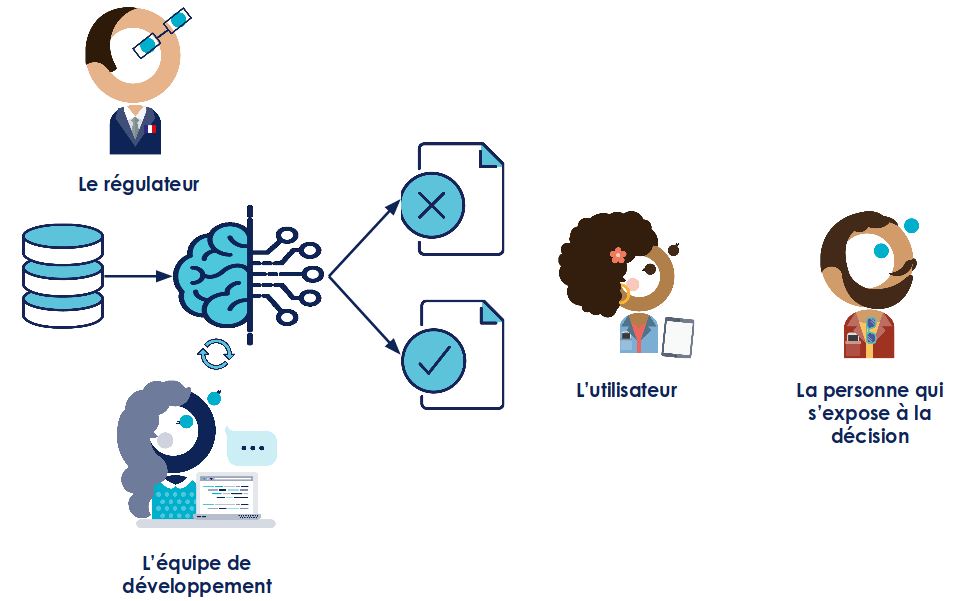
Figure 1 : Les profils qui interagissent avec un système de Data Science
L’équipe de développement, il s’agit de l’équipe qui construit le système : des développeurs, des data scientists, mais aussi des métiers. Elle a besoin de comprendre le fonctionnement du système, identifier ses forces et faiblesses pour pouvoir l’améliorer.
Les utilisateurs, il s’agit des personnes qui doivent se servir des prédictions faites par le système. Ces personnes ont besoin de comprendre les prédictions pour s’en servir au mieux. Un exemple d’utilisateur est un technicien qui s’occupe de la maintenance de machines à qui on prédit que “la machine N va tomber en panne”. Il sera plus efficace pour la réparer si on lui indique que cette prédiction a été faite car “le capteur de température donne une valeur trop importante”. Cette information complémentaire lui permettra de gagner du temps en concentrant son intervention autour de ce capteur. Elle aura également le bénéfice d’augmenter la confiance que l’utilisateur aura dans la prédiction.
Les personnes qui s’exposent à la décision, c’est-à-dire les personnes qui sont concernées par la prédiction. Un exemple est un patient à qui on dit “vous êtes atteint d’un cancer”. Pour pouvoir accepter la décision, le patient voudra comprendre ce qui a fait que le système est arrivé à cette conclusion. Exigence qu’un patient a déjà vis-à-vis de son médecin.
Les régulateurs, c’est-à-dire les personnes en charge de vérifier le bon fonctionnement des systèmes. Par exemple, la Banque Centrale Européenne contrôle les modèles de risque produits par les banques pour s’assurer qu’elles provisionnent suffisamment de fonds. A l’avenir, nous pouvons nous attendre à avoir de plus en plus de régulateurs qui voudront contrôler les systèmes de data science au fur et à mesure qu’ils se généralisent à des sujets sensibles (santé, loi, voiture, …). D’ailleurs, lors de la construction du GDPR, il a été évoqué (mais pas retenu) d’obliger les algorithmes à être interprétables dès lors qu’ils impactent des humains.
Au travers de ces 4 profils, nous commençons à sentir que les attentes en termes d’interprétabilité peuvent varier.
Les nouvelles tendances n’ont souvent pas de définition acceptées et reconnues par tous, l’interprétabilité n’échappe pas à cette règle. Pour cet article, nous avons retenu deux formulations.
La première formulation vient du dictionnaire Larousse. Il dit : “Interprétable [c’est ce] qui peut être interprété”. Pour “interprété” on trouve : “Chercher à rendre un texte, un auteur intelligibles, les expliquer, les commenter : Interpréter une loi, un écrivain.”. Et finalement, “Intelligible: Qui peut être compris[ …]”
En appliquant cela aux approches de data science, on obtiendrait la définition suivante : l’interprétabilité d’un système de data science c’est chercher à rendre un modèle, un processus de décision, intelligible, l’expliquer, le commenter.
La deuxième formulation vient de l’entreprise de conseil PwC qui distingue trois notions dans l’interprétabilité :
Comme on pouvait le sentir en répondant à la question “pour qui ?”, cette deuxième définition nous confirme qu’il y a différentes formes d’interprétabilité.
Ce qui doit être interprétable dépend beaucoup du “qui” et du “pourquoi”. Nous pouvons tout de même citer les 6 points suivants.
Les données utilisées, expliquer d’où elle viennent et ce qu’elles représentent. Par exemple, si une décision est basée sur des agrégations de l'historique de navigation d’un utilisateur, il faudra être capable de lui expliquer comment elles ont étés collectées et l’hypothèse qui a été formulée (seul lui a utilisé ce navigateur).
La structure du système de data science, c’est-à-dire pourquoi ces choix d’architecture ont été faits, et voire prouver que ce sont les bons.
Le processus d’apprentissage, c’est-à-dire le mécanisme qui permet d’extraire les corrélations des données. Sans oublier que le processus d’apprentissage varie en fonction du type d’algorithme de machine learning.
Le modèle appris, c’est-à-dire les poids qui ont été optimisés à partir de la base d’apprentissage. Cela peut être généralisé à l’ensemble de la pipeline de traitement (de l’information collectée à la prédiction).
Une prédiction, un résultat pour une situation donnée. Par exemple le résultat donné par le système à un patient.
Toutes les prédictions : le comportement du modèle pour l’ensemble des situations rencontrées.
Ce qui doit être interprété est l’ensemble des éléments décrit ci-dessus. Mais généralement, un profil de personnes ne va s'intéresser qu’à une sous-partie de ceux-ci.
Il y a deux types d’efforts à évaluer, celui à fournir par la personne qui cherche à interpréter et celui à fournir par l’équipe de développement.
Lorsqu’une personne veut interpréter un système de data science, elle va accepter d’y consacrer un temps limité. Par exemple, un patient y consacrera quelques minutes voir une heure, là où un régulateur y passera quelques jours voire quelques mois. Il faut donc apporter des solutions qui permettent d’interpréter dans le temps imparti.
La limite de temps accordé aura un impact direct sur ce que la personne pourra comprendre. Il est difficilement envisageable de comprendre le mécanisme des réseaux de neurones en moins de 5 minutes.
Pour rendre interprétable, l’équipe de développement devra investir du temps. Pour chacune des méthodes que nous verrons en fin d’article, il sera intéressant de mesurer l’investissement nécessaire pour les mettre en place et le comparer au bénéfice attendu.
Les réponses à ces quatre questions sont souvent corrélées, mais permettent d’identifier précisément l’objectif recherché et ainsi y apporter des réponses appropriées. Pour conclure cette partie, voici quelques exemples de profils.
| Pour qui | Attente | Quoi | Combien de temps |
| Data scientist | Comprendre, optimiser, corriger, améliorer | Le système dans son ensemble, le modèle | Une partie de sa mission |
| Expert métier | Avoir confiance et utiliser au mieux | Les prédictions | Une réunion |
| Client | Comprendre la décision le concernant | La prédiction qui le concerne | Moins de 5 min |
| Régulateur/auditeur | Valider, contrôler | Le processus de construction du système | Quelques jours / semaines |
Figure 2 : Exemples de profils
De l’information initiale jusqu’à la décision, il y a un empilement de complexité. La figure 3 propose une vue d’ensemble de cet empilement.
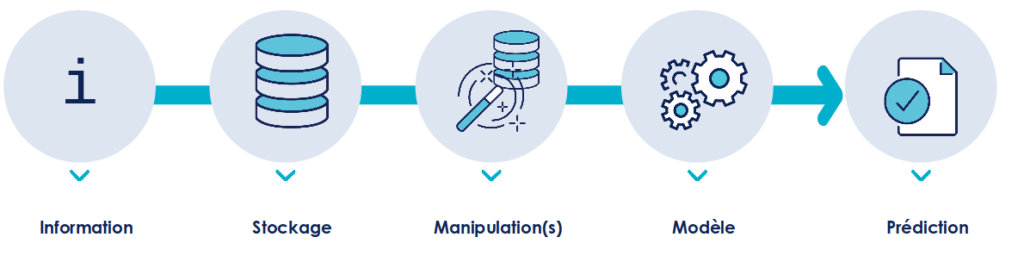
Figure 3 : Empilement de la complexité
Avant d’entrer dans le Système d’Information (SI), la donnée est une information. Cette information peut être plus ou moins complexe. L’âge, la température ou la vitesse sont compris par tous, mais l’EBITA nécessite des connaissances comptables.
Au moment de la collecte des données, des erreurs peuvent avoir lieu. Cela arrive souvent lorsque les données sont saisies manuellement. Il peut également y avoir insertion de biais. Par exemple si vous collectez certaines informations uniquement sur le blog d’Octo, alors la base de donnée correspondante dans votre SI contiendra principalement des technophiles (avec donc une sous-représentation des technophobes).
Une fois collectées, des choix de représentation sont faits au moment de l’insertion dans le SI. Par exemple les index incrémentaux représentent une notion d’ordre voire de temporalité. En utilisant l’index dans un modèle d’octroi de crédit cela pourra aboutir à “votre crédit a été refusé parce que votre identifiant client est trop grand”. La prédiction n’est pas fausse mais il faut décrypter l’explication : “votre crédit a été refusé parce que ça ne fait pas assez longtemps que vous êtes client chez nous”.
Ces données sont ensuite transformées. D’abord avant d’entrer dans le système de data science : elles sont manipulées, transformées, copiées dans d’autres outils … Puis dans le système de data science, il y a la création d’indicateurs métier (Par exemple : Température / Pression) et d’indicateurs du Data Scientist (Par exemple : transformée de Fourier, moyenne mobile).
Ainsi, il y a déjà beaucoup de complexité avant même d’entrer dans l’algorithme de machine learning. Dans celui-ci, trois autres niveaux de complexité sont à considérer : l’outil mathématique, l’algorithme d’apprentissage et le fléau de la dimension.
La complexité de l’outil mathématique. En machine learning nous utilisons différents types de modèles. La figure 4 en représente deux : un arbre de décision et un neurone. Sur cette représentation, l’arbre de décision est plus facilement compréhensible qu’un neurone.
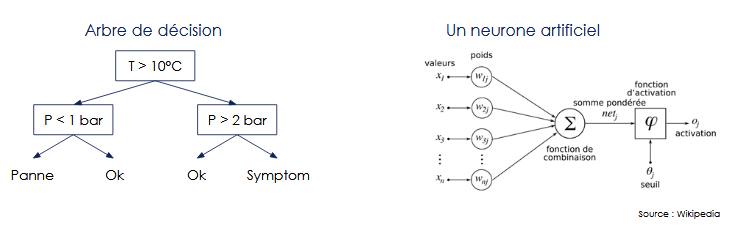
L’algorithme d’apprentissage. Il permet d’optimiser les poids à mettre sur les neurones ou les seuils à mettre dans un arbre pour avoir un modèle entraîné. Par exemple, si le technicien nous demande “pourquoi le seuil sur la température est à 10°C” il faudra lui expliquer le mécanisme d’apprentissage qui a mené à cela. La figure 5 présente la distinction outil mathématique / algorithme d’apprentissage pour quelques exemples de modèles de machine learning.
| Modèle | Outil mathématique | Algorithme d’apprentissage |
| Régression linéaire | Equation linéaire | Descente de gradient ou inversion de matrices |
| Arbre de décision | Question binaire, Si la réponse est oui aller dans la feuille gaucheSinon dans la feuille droite | Identification itérative des meilleures questions par minimisation d’un critère |
| Réseau de neurone | Combinaison de neurones | Rétro-propagation |
Figure 5 : Outil mathématique et algorithme d’apprentissage pour quelques modèles.
La complexité de la dimension. Souvent les modèles de machine learning prennent en entrée un grand volume de données (en nombre d’observations et / ou en dimension), et combinent un grand nombre d’arbres ou de neurones (comme représenté sur la figure 6). Peu importe la simplicité des concepts de bases (données et / ou modèles), en grand volume cela devient incompréhensible par l’esprit humain.
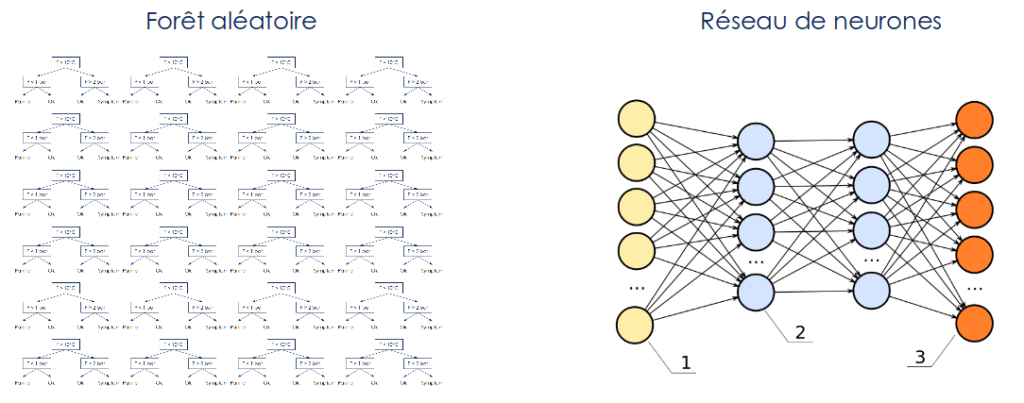
Ainsi la complexité d’un système de data science est composé de nombreuses sous-complexités empilées. Nous allons voir dans la suite de cette partie que ce n’est pas mauvais ou à exclure, mais qu’il convient de n’avoir que des complexités utiles.
Après avoir identifié l’empilement de complexité au sein des systèmes de data science, voyons pourquoi on construit des systèmes aussi complexes.
Une première raison, et la meilleure, est que ce que l’on cherche à modéliser est complexe. Par exemple, il n’est pas possible de modéliser de manière performante le comportement humain avec un seul arbre de décision peu profond.
Une deuxième raison est que nous anticipons mal le comportement de nos systèmes en phase d’apprentissage. Nous leur laissons donc un grand champ de liberté (beaucoup de données en entrée, et un modèle complexe) pour maximiser nos chances d’avoir une bonne performance.
Ainsi, il peut être envisageable de diminuer la complexité pour la deuxième raison, mais si le phénomène à modéliser est complexe une modélisation performante le sera aussi.
L’ajout de complexité est un moyen d’augmenter la performance d’un système de data science. Cette pratique a cependant le défaut de diminuer l’interprétabilité. L’interprétabilité et la performance servent l’utilité du modèle. Il est donc important de trouver le bon niveau de complexité nécessaire pour maximiser l’utilité du modèle.
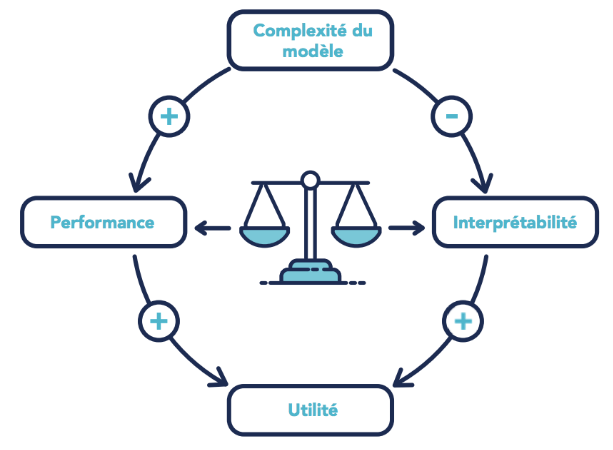
Pour compléter cette illustration, n’oublions pas que :
Il existe de multiples façons de rendre un système de data science plus interprétable. Le choix des techniques d’interprétabilité dépendra beaucoup des réponses apportées aux 4 questions (pour qui ?, pourquoi ?, quoi ?, et quel effort ?). Cette partie est donc un catalogue de solutions dans lequel piocher.
Les solutions ne commencent pas par de la data science, ni de la technique. Elles peuvent être :
Du bon sens métier, en discutant avec les métiers pour bien comprendre ce que l’on cherche à modéliser (et donc pour définir la cible), pour analyser les résultats afin de les comprendre, les simplifier, les fiabiliser. Une pratique simple à mettre en place est de demander au métier : “Quels sont les indicateurs qui te permettent aujourd’hui d’anticiper le phénomène ?”. La personne devra normalement vous donner un certain nombre d’indicateurs riches en information. Implémentez les, cela améliorera grandement la performance du système, et les résultats seront facilement interprétables.
En simplifiant ou en découpant le problème, plutôt que de prédire si en bout d’une ligne de production il y a des défauts, on peut faire plusieurs systèmes qui prédisent l’apparition de défauts à chaque étape. Ce découpage en sous-problèmes rendra la modélisation plus simple et les résultats plus interprétables.
De l’humain, en faisant de la pédagogie, en vulgarisant ce qui se passe. Par exemple, sur Google Actualité, il y a un message qui explique comment les résultats sont classés (cf figure 8). Il est aussi possible de mettre en place une démarche “marketing” pour identifier l’argument qui fera mouche et qui permettra de comprendre rapidement.
Des visualisations, en proposant une visualisation des données ou des processus pour permettre aux personnes d’interagir avec ceux-ci et de se les approprier. La figure 9 est un exemple de visualisation (sur des données fictives) que l’on a été amené à faire sur un cas d’usage de prédiction de la satisfaction. Sur la partie haute, les différents évènements de la relation client sont présentés (notamment les réclamations). Sur la partie inférieure, en trait plein orange sont représentés les notes de satisfactions effectivement constatées, et en trait pointillé bleu clair la prédiction de la satisfaction faite par un algorithme de m_achine learning_.
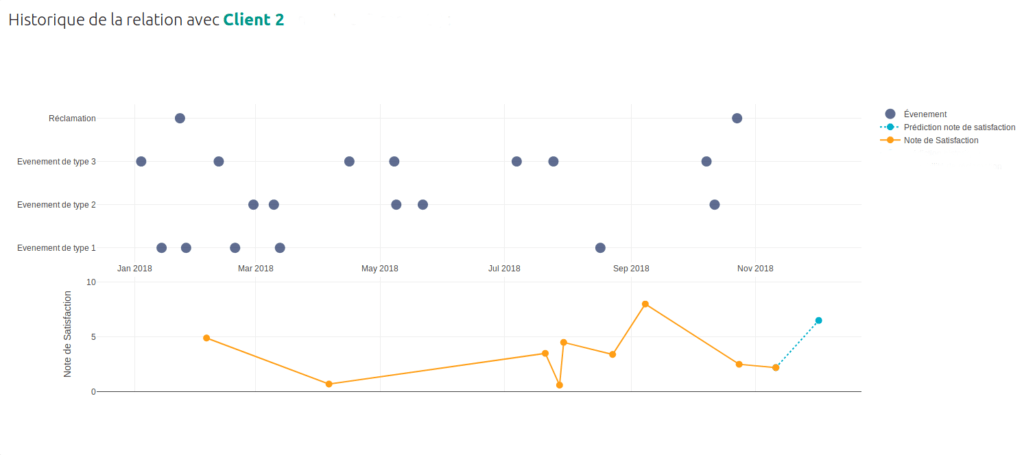
Cette visualisation permet aux utilisateurs de re-contextualiser rapidement la situation de l’utilisateur, de voir l’impact des événements passés sur la satisfaction et ainsi d’identifier si des actions doivent être menées pour améliorer la satisfaction client. Il est possible de créer toutes sortes de visualisations, pour trouver celle qui sera la plus impactante il faut la co-construire avec les utilisateurs.
Il existe également un certain nombre de solutions techniques. Celles-ci sont surtout des solutions existantes appliquées au monde de la data science.
Des bonnes pratiques de développement. Le monde de la data science a pas mal de choses à apprendre du monde du développement logiciel. Les bonnes pratiques de ce dernier permettent notamment de s’assurer de la reproductibilité de nos processus. Ainsi il sera possible de relancer un entraînement ou refaire une prédiction et obtenir exactement le même résultat.
La gestion des versions. Dans un projet de data science les artefacts sont de 3 types : code, données, et modèles. Pour obtenir la reproductibilité, il convient de les versionner. Des exemples d’outils sont Git pour versionner le code, DVC pour versionner les données et les modèles.
Du data lineage. C’est-à-dire être capable de tracer le chemin de l’information initiale à la prédiction en passant par l’ensemble des SI, des transformations et par le modèle de machine learning.
Un modèle simple et itérer. Construire un premier modèle simple puis itérer permet :
Finalement, des algorithmes de data science peuvent apporter des solutions à l’interprétabilité. Avant d’entrer dans le détail, remarquons que ces algorithmes ne répondront pas à l’objectif de transparence car ils ajoutent de la complexité. Ces algorithmes ne servent qu'à apporter des explications sur les prédictions.
Nous n’allons pas citer toutes les méthodes car la littérature est foisonnante. Nous allons parler de 3 approches, l’une spécifique aux modèles à base d’arbres, une agnostique au modèle et une spécifique aux réseaux de neurones utilisés sur des images.
L’approche tree interpreter date de 2014. C’est une méthode adaptée pour interpréter une prédiction donnée par un modèle à base d’arbres de décision. L’idée est qu’un individu ne va pas passer par tous les nœuds de l’arbre mais seulement par une petite partie de ceux-ci (cf figure 10). Cela permet donc d’extraire exactement les variables qui ont participé à la décision et de donner un poids relatif à celles-ci.
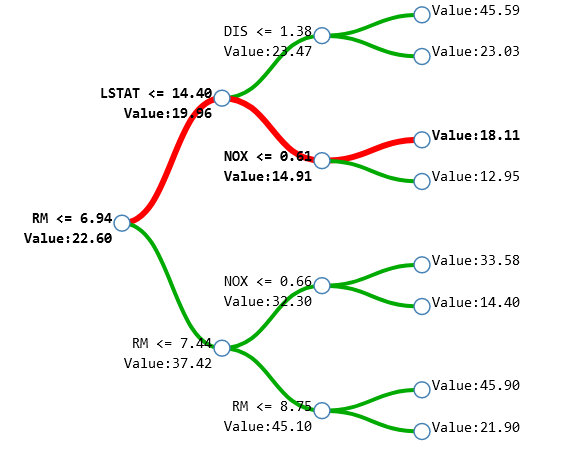
Sur la figure 10, on peut voir que pour l’individu prédit, la variable “RM” a contribué à modifier la prédiction de 22,6 à 19,96 au premier noeud. Puis la variable “LSTAT” de 19,96 à 14,91. Enfin la variable NOX a, elle, augmenté la prédiction de 14,91 à 18,11.
Ainsi la méthode tree interpreter permet d’extraire une justification pour une décision. Cette méthode est spécifique au modèle à base d’arbres et permet de donner seulement des explications concernant une prédiction. La principale limite de cette méthode est lorsqu’il y a un très grand nombre de variables, car l’explication va devenir très longue. Une autre limite est qu’elle n’explique pas pourquoi les différents seuils ont étés choisis (Par exemple sur la figure 10, pourquoi l’algorithme a regardé si RM <= 6,94).
La méthode Shap date de 2017. Elle permet pour tous types de modèles de donner des explications à posteriori sur l’apport de chaque variable. De manière très simplifiée, l’algorithme applique des petites modifications en entrée du modèle et regarde l’impact que cela a sur les prédictions. Les résultats peuvent alors être représentés comme sur la figure 11.

La principale limitation de l’approche shap est qu’elle récupère de manière prioritaire les signaux forts (puisqu’ils ont un fort impact sur la décision). Or, la plupart du temps nos modèles vont chercher des signaux faibles pour améliorer leur performance. Vous pourrez donc vous retrouver dans une situation où 2 individus ont les mêmes shap values représentées mais pas la même décision.
Les cartes de chaleur, pour interpréter les résultats de réseaux de neurones, datent de 2017. Elles permettent d’afficher sur une image les zones qui ont contribué à la prédiction. Plus la zone a servie plus elle est rouge, moins elle a servie plus elle est bleue. Sur la figure 12. sur l’image de gauche on voit que c’est le bas du museau qui a donné la prédiction “chien” et sur l’image de droite, c’est l’ensemble du corps du chat qui a donné la prédiction “chat”.

Cette méthode permet de se rendre compte que le modèle a utilisé une zone aberrante à côté du chien (en vert sur l’image de droite) pour prédire chat.
L’interprétabilité concerne toutes les personnes autour du système de data science. Chaque personne a ses attentes en terme d’interprétabilité. Les techniques à employer dépendent donc de ces besoins et ne sont pas que de la data science.
La difficulté d’interpréter vient d’un empilement de la complexité tout au long du système de data science qui prend en entrée des informations et donne des prédictions.
L'empilement de la complexité est ni une fatalité, ni à interdire. Il convient cependant de la maîtriser :
Ainsi il sera possible de justifier que toute la complexité dans le système est nécessaire. Pour expliquer cette complexité on pourra, alors, utiliser des solutions non-techniques (vulgarisation, pédagogie, visualisation, ...), ou des algorithmes.