La mise en place d'un cache HTTP devant des serveurs web est un bon moyen d'en améliorer les performances. Ce billet a deux objectifs :
Les caches sont utilisés pour améliorer les performances d'accès à une ressource. Cette amélioration peut se faire de 2 manière.
La première est de réduire le temps d'accès à la ressource en copiant la ressource au plus prês de son utilisateur. Quelques exemples : le cache L2 d'un processeur, le cache de base de données, le cache de navigateur web, un CDN.
La deuxième est d'accélérer la construction de la ressource en réduisant son nombre d'accès : par exemple, on va mettre en cache la page d'accueil d'un blog, pour qu'elle ne soit pas reconstruite à toutes les requêtes, mais seulement toutes les 30 secondes. C'est ce principe que nous allons maintenant étudier : un cache HTTP.
Le cache HTTP se place généralement devant votre serveur web. Cela donne une architecture qui ressemble à ça :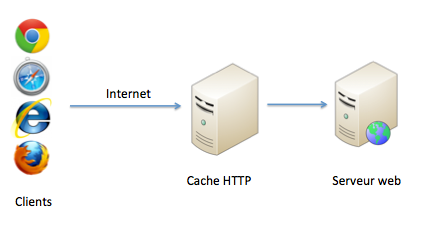
Il y a de nombreuses implémentations de cache HTTP. Les plus connues sont
C'est assez simple : le cache HTTP va réutiliser les headers de cache HTTP prévus pour le cache du navigateur du client. Par exemple, si votre serveur web renvoie pour une URL donnée un header HTTP : Expires: Thu, 31 Dec 2037 23:55:55 GMT, cela indique que cette ressource ne sera pas modifiée avant le 31 décembre 2037. Et cela permet donc à tous les utilisateurs de cette ressource de la récupérer une seule fois et de la stocker jusqu'à sa date d'expiration. C'est exactement ce que va faire le cache HTTP.
En plus de Expires, il existe d'autres headers HTTP impliqués dans les mécanismes de cache, notamment Cache-Control et Vary. Je vous invite à consulter la RFC 2616 pour plus de détails. Et hélas, c'est un domaine assez compliqué : les différents navigateurs / reverse proxy / cache HTTP ne gèrent pas ces headers de la même manière.
L'architecture simplifiée d'un cache HTTP est donc la suivante :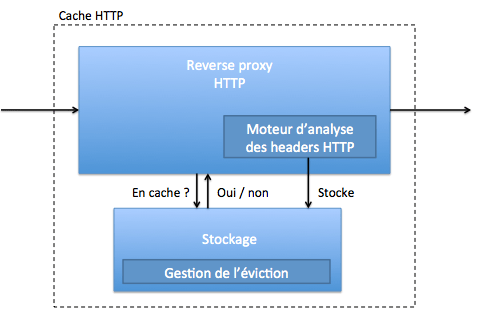
Un point important à noter est que le cache HTTP ne va pas stocker seulement le contenu de l'URL, il va aussi stocker des headers HTTP, des temps d'expiration ...
Certains produits permettent de configurer le caching sans utiliser les headers, si on ne veut pas (ou on ne peut pas) modifier son application. Voir par exemple la VCL de varnish. Je vous invite cependant à utiliser les headers HTTP, car c'est standard et plus simple à déployer (tout est dans l'applicatif).
Dans les implémentations ci dessus, Varnish et Squid vont être des démons séparés du serveur Web. Ces deux outils vont faire du caching en mémoire et/ou sur disque. Apache2 et Nginx vont pouvoir faire du caching HTTP, directement dans le serveur Web. La différence de performances ne sera pas gigantesque (au moins coté Nginx). L'architecture avec un cache séparée a cependant d'autres avantages. Elle permet de mutualiser le cache entre plusieurs applications, ou de lui confier d'autres fonctions : load balancing, aiguillage des certaines urls sur des serveurs spécifiques ...
Le système de cache fonctionne tellement bien qu'on va souvent chercher à lui faire faire autre chose. Prenons un exemple : mon site web affiche un classement. Ce classement est recalculé toutes les 3 minutes par un démon. Il est stocké dans une page web chargée en Ajax. Comment faire ? La solution la plus simple est d'écrire un fichier sur le disque qui sera ensuite servi par un serveur web, comme une page statique. Un problème est que le fichier ne contient que les données : pas de meta data, comme par exemple le temps d'expiration de la ressource. On aimerait donc bien placer notre classement directement dans un cache HTTP, en précisant le temps d'expiration. C'est assez compliqué en fait, puisque c'est un démon qui met à jour notre classement, et que le cache est alimenté par un serveur web ...
Pour ce besoin, on va plutôt chercher une architecture du genre :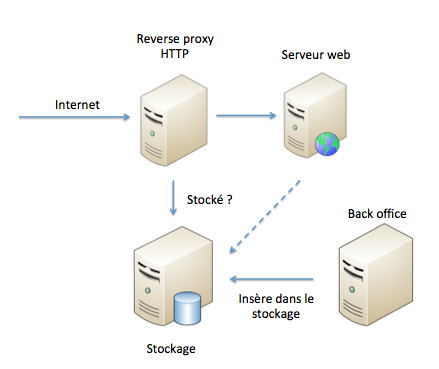
Dans cette architecture, pour chaque requête HTTP entrante (ou seulement sur un pattern d'URL), le reverse proxy HTTP se connecte sur le stockage et lui demande si il contient des données pour l'URL en question. Si oui, le reverse proxy HTTP renvoie les données. Si non, le reverse proxy interroge le serveur Web. Dans ce cas, ce n'est pas le reverse proxy qui remplit le stockage. Il est rempli soit par un autre serveur qui execute des traitements métiers (le serveur back office du dessin), soit par le serveur web, qui le remplit sur certains requêtes en plus de renvoyer des pages HTML.
C'est en fait un cache HTTP "éclaté" : on sépare la partie reverse proxy de la partie stockage, et on supprime l'alimentation du stockage par analyse des headers HTTP.
Cette architecture n'est pertinente que si le coût de régénération de la ressource est supérieur au coût d'aller la chercher dans le stockage. C'est très souvent le cas : une interrogation d'un stockage comme a href="http://memcached.org/">Memcached sera bien plus rapide qu'un appel en base de données. On architecturera le site web pour que toutes les URLs que l'on peut mettre en cache soit facilement identifiables : /cache par exemple, de manière à ne pas faire d'appels sur le cache inutilement.
Ce besoin est en fait de plus en plus important : aujourd'hui, il n'y a plus besoin de démontrer l'impact de la vitesse d'un site web sur son business : "Amazon a découvert que chaque 100ms de latence lui coûte 1% de chiffre d'affaire". Il est donc vital d'accélérer l'affichage des pages. Et une solution pour le faire est de réaliser certains traitements trop long de manière asynchrone. Quelques exemples : envoyer un mail, calculer un classement, mettre à disposition le pdf d'une facture ... Ce mécanisme de jobs asynchrones est intégré dans certains frameworks de dévelopement web, par exemple Rails et ses delayed jobs.
Le module Nginx / Memcached permet de réaliser l'architecture précédente, en utilisant Nginx comme reverse proxy HTTP et Memcached comme stockage. (Note : memcached est souvent utilisé pour stocker les sessions HTTP de manière partagée).
Le module Nginx memcached de base fonctionne très bien. Il a cependant une grosse limitation : on ne peut stocker les headers HTTP avec les données. Par exemple, les pages servies par Nginx et des données dans Memcached ont le Content-Type par défaut de Nginx : impossible donc de stocker plusieurs types de données dans le cache (CSS, JS, images, HTML, json...). On peut ajouter des headers HTTP spécifiques, mais seulement dans la configuration Nginx. Ces headers seront donc communs pour tous les resources servies par Nginx/Memcached (à moins de mettre des ifs partout dans la configuration).
Cette limitation rend donc plus difficile l'utilisation de ce module. Note : le module Nginx Redis présente le même type de limitation.
J'ai donc modifié le module Nginx / Memcached afin de pouvoir stocker des headers HTTP dans Memcached. Pour l'utiliser, il suffit d'insérer dans Memcached quelque chose du genre :
EXTRACT_HEADERS
Content-Type: text/xml
<toto></toto>
Nginx renverra une page qui contiendra juste <toto></toto>, mais avec un header HTTP Content-Type: text/xml.
J'en ai profité pour ajouter des fonctionnalitées :
If-Modified-Since, pour renvoyer un code 304 Not modified quand la donnée dans Memcached contient un header Last-Modified.Un exemple de configuration Nginx, où Nginx regarde pour toutes les URLs si il y a des données dans memcached avant de passer les requêtes aux servers webs :
location / {
error_page 404 = @fallback;
if ($http_pragma ~* "no-cache") {
return 404;
}
if ($http_cache_control ~* "no-cache") {
return 404;
}
set $enhanced_memcached_key "$request_uri";
set $enhanced_memcached_key_namespace "$host";
enhanced_memcached_hash_keys_with_md5 on;
enhanced_memcached_pass memcached_upstream;
}
location @fallback {
proxy_pass http://backend_upstream;
}
Ce module est open source et disponible ici. Il est utilisé en production chez fasterize, et toutes ces fonctionnalités sont utilisées et fonctionnent très bien.
J'espère que ce module vous sera utile !