Nous constatons au quotidien dans les SI traditionnels rencontrés qu’un volume important de données qui peuvent s’avérer d’une grande utilité ne sont, soit pas collectées, soit non exploitées à leur juste valeur.
Aussi, les données sont souvent cloisonnées au sein d’applicatifs qui ne communiquent pas entre eux et ne permettent donc pas de les faire fructifier en les croisant avec d’autres données internes ou externes et d’en tirer une plus-value.
Pour atteindre ce niveau de maturité, proposer à vos clients de nouveaux services et vous différencier de la concurrence, l’enjeu est d’abord technique. Comment mon SI peut stocker, traiter un volume de données de plus en plus important dans un minimum de temps ? Les technologies adéquates se démocratisent sous l’impulsion des Géants du Web.
L’enjeu est également métier, puisque le traitement croisé, voire temps réel de ces données font émerger de nouvelles perspectives qu’il faut savoir appréhender.
Le secteur du E-Commerce et de la grande distribution n’échappent pas à la règle. C’est ce secteur et ses cas d’utilisation que nous avons choisi de développer en particulier dans ce billet.
En avant-propos, voici quatre stories montrant le potentiel des technologies actuelles appliquées au secteur de la grande distribution.
Nous sommes jeudi, il est 14h15. Le directeur de magasin consulte le tableau de bord, comme il le fait souvent. En un coup d’œil, il observe :
Aujourd’hui, la famille “jambon cuit” est en top des ventes, plus que d’habitude: il serait temps d’approvisionner le stock. Le magasinier est averti, le bon de commande est auto-généré et prêt à être envoyé avec les quantités recommandées par l’algorithme de prédiction des achats qui croise les historiques de vente avec d’autres données, notamment le calendrier des vacances et la météo. Toujours sur le tableau de bord, il voit qu’à l’inverse, les ventes des produits “ultra frais enfant” tirent la langue : un retard de 40% par rapport à jeudi dernier est indiqué. Il demande alors la courbe d’évolution des ventes de la journée pour cette famille :
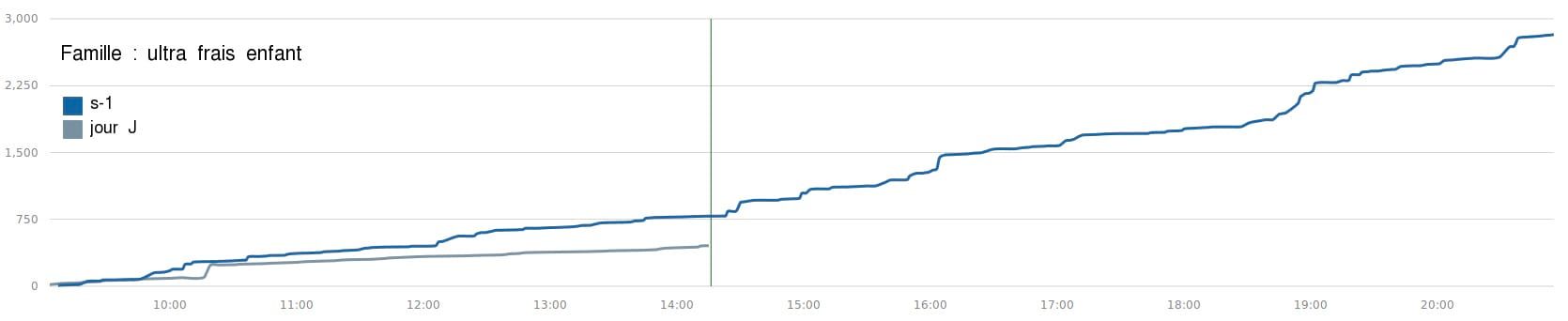
Effectivement, voilà plusieurs heures que les ventes ont stagné. Ces produits là périmant rapidement, il doit limiter la casse : une promotion flash est lancée. Magali, au micro, passe l’annonce tous les quarts d’heure jusqu’à nouvel ordre…
2h15 plus tard, il retourne voir le tableau de bord. Il demande la courbe d’évolution des ventes :
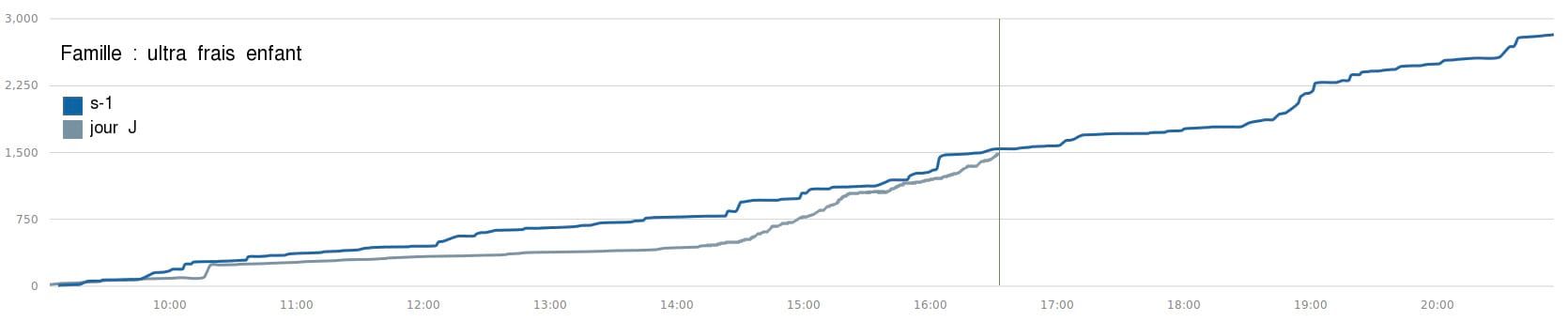
La barre est redressée ! La promotion a porté ses fruits, nous pouvons l'interrompre.
De la même façon, le directeur régional voit les mêmes indicateurs cités plus haut et suit les opérations et les alertes heure par heure afin de déclencher des actions d’optimisation plus globales.
Un client est en train de naviguer sur le site Drive, connecté avec son compte habituel. C’est un client fidèle, qui a ses habitudes de consommation. Dans la plupart de ses paniers, nous retrouvons souvent plus de 50% de produits invariants. Proche de finaliser son panier, ce client n’a pas inclu l’un des produits qu’il achète de façon récurrente, ce qui est assez inhabituel. A-t-il oublié ce produit ? S’en est il lassé ? Ou peut être ce produit n’est-il pas dans sa liste aujourd’hui ? Il suffit de remonter son parcours pendant sa session sur le site du Drive. Si le client a effectivement consulté le produit mais ne l’a pas mis dans son panier, on est peut être face à un symptôme de lassitude. Dans ce cas, un algorithme calcule les produits similaires (produits de substitution). Exemple : si le produit est un déodorant de type roll-on, on peut proposer :
En revanche, si l’utilisateur n’a même pas consulté le produit, on est peut être face à un oubli. Le produit lui-même peut alors être suggéré. Ainsi, avant de procéder au paiement, le produit approprié est proposé à l’internaute. Ce dernier saute aux yeux du client qui est heureux : surpris d’avoir oublié cet indispensable, il ajoute ce produit au panier et passe à la caisse.
Vendredi, un consommateur fait ses courses sur le Drive. De par certaines de ses consommations (produits jardinage, charbon de bois, allumettes longues), le client est catégorisé comme “possède un jardin” et “adepte aux barbecues”. Or la météo de ce week-end indique un temps clément : plein soleil, température raisonnable. Un croisement du profiling client avec la date et la météo permettent de générer un pack incluant une promotion : pour l’achat d’un ensemble “merguez, brochettes et bouteille de rosé”, le paquet de chips fabrication artisanale est offert… Suggéré à l’utilisateur sur la page web, ce pack apporte deux avantages au consommateur :
En un clic, l’utilisateur peut profiter de cette offre personnalisée en l’ajoutant à son panier.
Sur le mois dernier, nous avons étudié l’ensemble des tickets du groupe pour essayer de mettre en avant des patterns de consommation des clients. L’étude statistique révèle que lorsqu’un ticket contient les produits A et B, il y a beaucoup de chances qu’il contienne le produit C. En s’intéressant aux produits, on remarque que les produits A et C appartiennent au rayon alcools et bières, alors que le produit B est issu du rayon épicerie sucrée.
Un client qui n’a pas de carte de fidélité passe en caisse. Son panier contient les produits A et B. Après son passage, la caissière lui remet un ensemble de promotions ciblées, dont le produit C. Le client jette un œil aux promotions et s’intéresse au produit C: “ce sera une bonne idée pour la prochaine fois”.
Ces histoires ne relèvent pas de la science fiction. Techniquement, elles sont mêmes toutes réalisables, voire déjà réalisées. Nous connaissons tous la puissance des moteurs de recommandation d’Amazon ou encore d’Ebay : le parcours du client et son profil sont passés au crible par des algorithmes de machine learning qui, quasi instantanément seront capables de prédire votre comportement futur, et vous influenceront en ce sens. L’expérience montre que cette approche prédictive basée sur le comportement d’achat et le détail de l’achat est bien plus efficace que les approches classiques de classification (basée sur la récence ou la fréquence par exemple). Et pourtant ce sont bien ces méthodes de classification qui sont les plus répandues aujourd’hui en France.
Vous vous rappelez sans doute aussi de l’histoire de la firme américaine de grande distribution Target dont le système de recommandation basé sur le comportement d’achat a déduit qu’une adolescente américaine était enceinte bien avant que son propre père ne soit au courant. Au-dela du buzz que cette histoire a engendré et des questions éthiques qu’elle a soulevées, il se cache la même réalité, celle de l’importance de l’analyse du comportement d’achat et la pertinence de la recommandation proposée à l’utilisateur dans ce secteur. La tendance est donc de collecter l’ensemble des tickets d’achat avec leurs détails, le jour et l’heure d’achat, la référence produit, la quantité, le magasin concerné, le rayon concerné, et toute autre information permettant d’identifier avec précision l’acte d’achat ainsi que l’identité de l’acheteur (souvent liée à une ou plusieurs cartes de fidélités) afin de l’utiliser dans l’immédiat ou ultérieurement.
Nous recevons (presque) tous en tant que consommateurs des grandes chaînes de distributions que nous fréquentons des promotions, des produits recommandés etc. Mais il s’agit la plupart du temps d’analyses sous formes de batchs, calculés avec les données collectées au maximum à J-1 (la veille), avec plus ou moins de détails et avec une recommandation plus ou moins pertinente, car la plupart du temps le détail du ticket n’est pas traité dans son intégralité. En effet, une analyse temps-réel du comportement d’achat des clients nécessiterait des changements importants dans les SI. Il s’agirait tout d’abord de collecter le détail de tous les tickets de caisse dans les magasins physiques et sur d’autres canaux (site web et applications mobiles, vus la plupart du temps comme des magasins virtuels), stocker tout ce flux d’information qui peut représenter plusieurs téras de données par semaine voire par jour pour les plus grandes enseignes, puis ensuite analyser (en temps-réel pour un maximum de réactivité) tout ce flux de données, faire du nettoyage et en déduire une information utile et pertinente pour l’utilisateur.
Par exemple, suite à la détection d’un retour d’article, essayer de faire une promotion sur un article équivalent d’une autre marque disponible en abondance dans le stock (croisement avec les données de stock local ou global) ou encore envoyer une promotion par mail au client pour lui proposer une promotion sur le site pour l’acquisition de 4 paquets de piles pour la brosse à dent électrique qu’il aurait achetée en magasin le jour même (en partenariat avec le constructeur par exemple). En effet, il s’agit de saisir l’opportunité d’avoir la disponibilité du client à un moment donné et réagir au plus vite afin de lui proposer des offres au plus près de ses attentes.
La prévision de la demande client, la mise en avant des clients récurrents, des clients potentiellement quitteurs, l’étude de l’impact d’une promotion, l’optimisation continue du stock ou bien la recommandation de produits, ce sont autant de cas d’utilisation qui recquièrent de collecter toutes les données, de les filtrer, de les nettoyer et de les enrichir, étapes indispensables avant de les faire ingérer à des algos de machine learning, dont la complexité n’est pas forcément linéaire en espace et en temps. Il est alors nécessaire de réfléchir aux aspects architecture et performance en amont.
Dans ce second article, nous présentons la mise en place concrète d’une solution pour l’un des use cases présentés précédemment comprenant la modélisation des données et leur chemin à travers la plateforme, une solution technologique pour chaque niveau de l’architecture ainsi qu’un regard sur les fondements de ces technos et leur interaction.