Today, Retail and Private Banks' Core Banking System (CBS) and Portfolio Management System (PMS) are strong assets. They have matured over the years and are often a very solid basis for the rest of the satellite IT systems. They are used to efficiently manage the basic core banking data, like clients, portfolios, their security composition, the pending orders, the market transactions and so on. Portfolio-level and bank-level consolidated metrics however are often based on long running algorithms and are therefore executed either during end of day batches or on-demand, meaning users' have to work with more or less outdated data or data that is long to get.
The issue is that in recent years, banking has seen several shifts:
All of this has underlined an increasing need for up-to-date consolidated information (exposures, performance, variance, volatility, ...) at different levels (position, portfolio, desk, region, bank). While some of this complexity has already been addressed in Investment Banks (IB), Retail and Private Banking have lagged behind, mostly because the need was initially not identified as so important but more importantly because they lack the resources. Indeed the IB solutions are generally plagued by a very high TCO (Total Cost of Ownership) that is neither justified nor bearable for other kinds of banks.
One of the core metric used by portfolio risk managers is the portfolio variance. To calculate a portfolio variance over a time period, one needs to compute the variance of each of the securities held on the time period, their correlation with one another (covariance) and to aggregate them based on the security relative weights in the portfolio. Because this metric needs to integrate a lot of heterogeneous values (numerous security prices, portfolio compositions, forex rates) it generally takes seconds, if not minutes, to compute on classical systems (in some big institutional portfolio scenarii, it even happens that the CBS or PMS cannot do the computation). This is because
Thus, running such heavy computations on the online system adds an unmanageable additional level of contention, lags, slownesses for the users (and sometimes directly for the clients who access data through the e-banking portal for example). And those are the main reasons why banks are struggling with portfolio risk management: the system is not helping the risk managers enough by providing them with the right information at the right time.
Most of the attempts to solve for this problem in the operational system have failed because it either
Another often seen approach is to go through Business Intelligence (BI) components. It is however not perfect either, as it is mostly based on overnight computations on frozen data, which does not fit our stated need for up-to-date, near real-time metrics.
Most of those issues or limitations come from choices that were made based on the available technology and the available budget at the time. But today, a lot of those parameters have changed. Led by the needs of the internet giants and the increased capacity of commodity hardware, new kinds of technologies and architectures have emerged and it is now possible to build within the operational system very efficient ways to perform heavy computations on massive amount of data.
Data access has a cost, and as is well known, typical disk solutions (SAN or NAS) are the weakest link when it comes to throughput speed, and nothing beats local RAM.
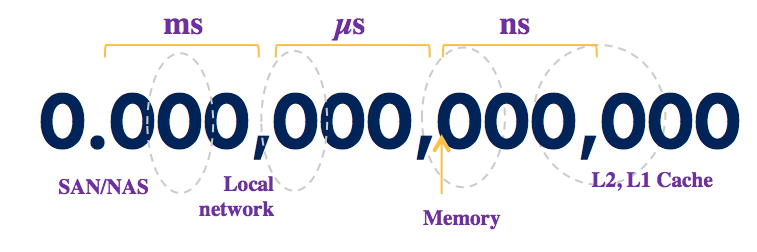
Hardware throughput time
The first thing is therefore to realize that the increased capacity of commodity hardware at a low premium gives access to a lot of RAM as well as accompanying local computing power for a very low cost of ownership.
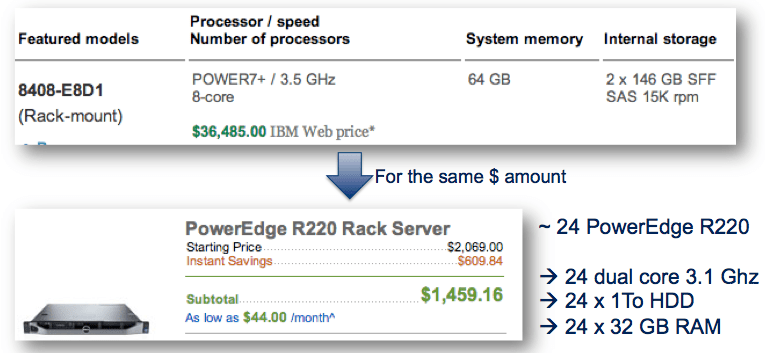
AIX vs Dell Cost
This comparison is a shortcut that we can't really make because you don't get the same support or quality between the 2 products, but it gives a good appreciation of the cost difference between typical servers and commodity hardware
Distributing data and computation is a direct consequence of this trend. While massively distributed processing was reserved to giants (Research institutes, major internet companies), cheap hardware now makes it available to everyone. This allows any IT department of any size to consider grid computing solutions nowadays. And in turns, this ended up with the creation of numerous distribution frameworks that give those setups a level of reliability that is expected from classical server/mainframe.
Commodity hardware and new distribution frameworks therefore make grid storage and grid computing the key basis for a fast, highly available, highly reliable and cheap system.
While those new concepts were key to solve the problem at hand, in our particular case, a paradigm shift in the system architecture was also necessary to achieve the best result possible. The classical paradigm is a pull model (intraday values are computed on-demand) but we are now going to look at some kind of push based one. Indeed, while with a pull model one can consider adding resources to try and bear the load, it is still very difficult to give users fluid and reactive interfaces but more importantly, it is not possible to build proactive systems that will react on thresholds because the consolidated data is just not there! This is actually not a new paradigm but it is definitely novel in the banking industry.
Thinking about what would be an ideal world for our risk manager. We can see 2 main axis:
Think about volatility for example. A portfolio manager might want alerting level on volatility. In the case of long term trading, he might want to move away from a security that becomes volatile. In the case of tactical trading, he might rather wait for a high volatility time to try and trade during the peaks.
Once a distributed architecture is chosen, the challenge is to make it highly available. Indeed, commodity hardware will fail, and software solutions are therefore used to cope with that. Partionning and replication are the keys here and will be provided by a software solution (in our case we chose Infinispan) that will be configured (typically the replication factor) depending on performance consideration and most importantly on the cluster topology.
The second thing is about changing how systems are built in banks. Rather than staying with a single type of paradigm, best of breed architectures must be considered for each use case. Banks classically only build systems based on a pull model. They have a strong data layer, and when some consolidated data is needed, the computation is done on the fly. To improve response time, some consolidations are made and persisted in batches (often overnight) but that means the user accesses outdated information (think back on the volatility use case from before). The shift is therefore to open the information system to other architectures, and in the considered use case, to introduce a push one where consolidated values are constantly recalculated and the user just gets instant access to the latest computed data, that is generally only a few seconds old at most.
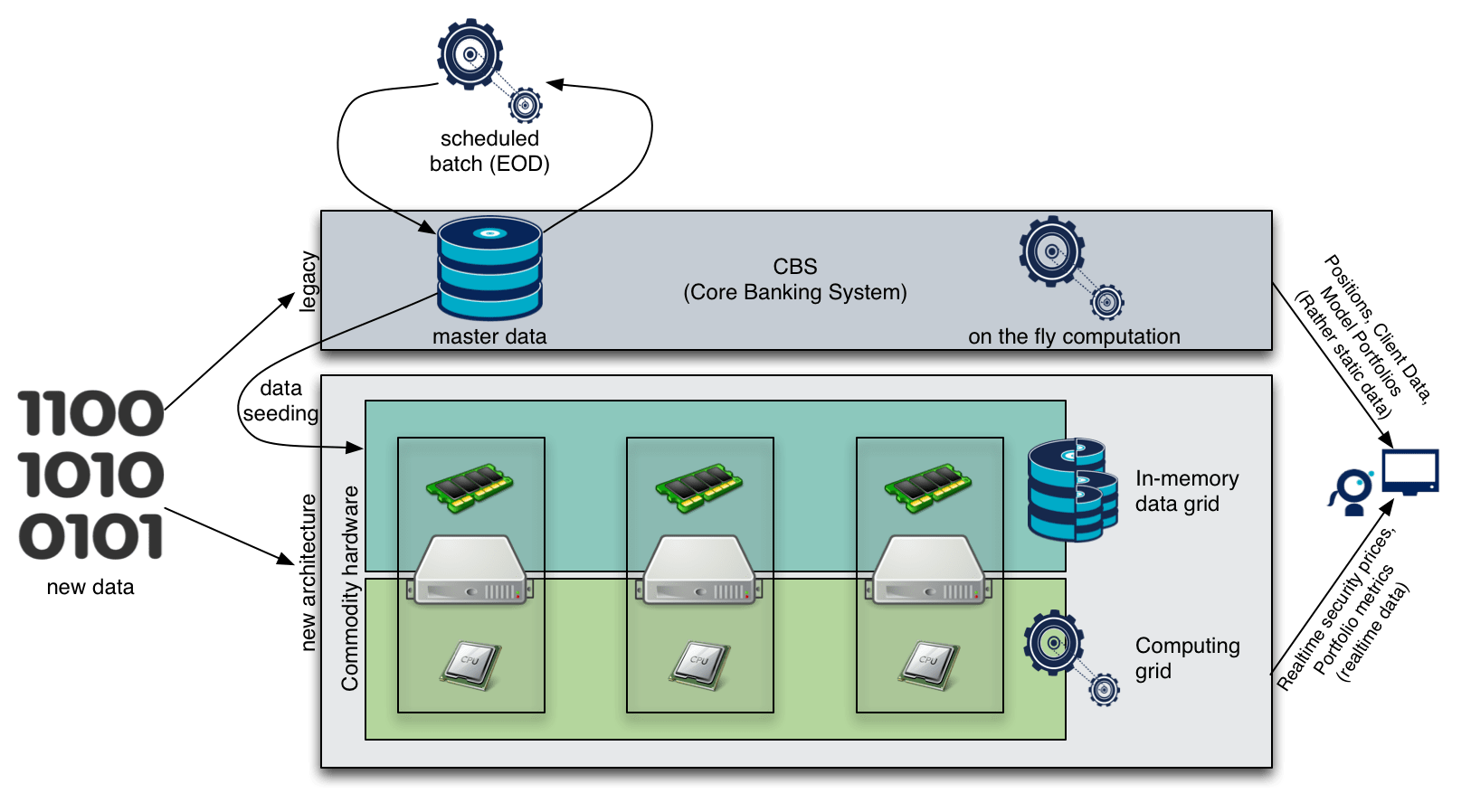
Proposed Architecture
This type of infrastructure combined with the following software architecture design will have several benefits:
Each of the benefit of our architecture as presented above is key in addressing the needs of our use case, and their combination is what makes the end system achieve the desired efficiency.
Here is what such an architecture would look like in the described volatility use case
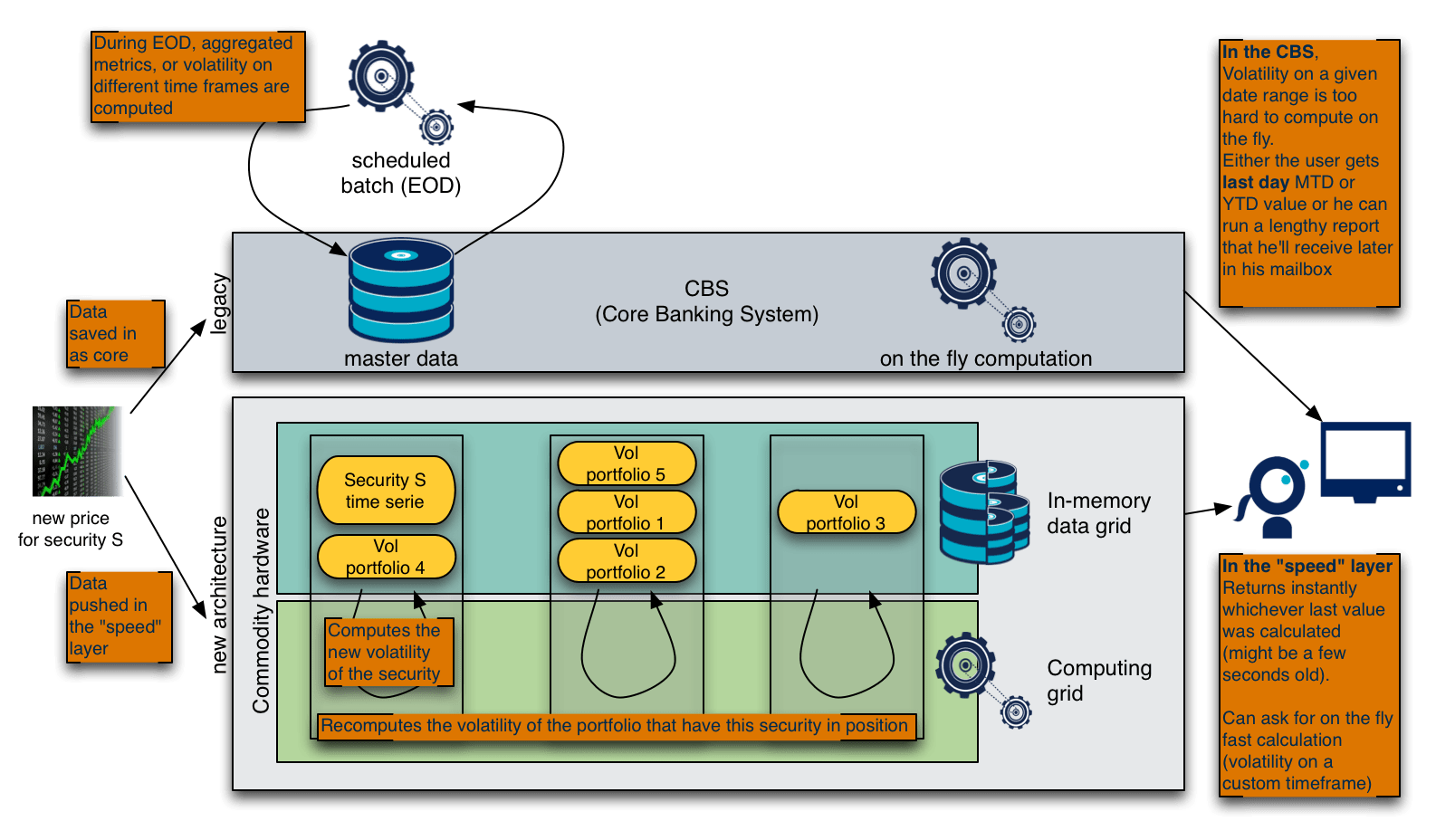
Reference data processing
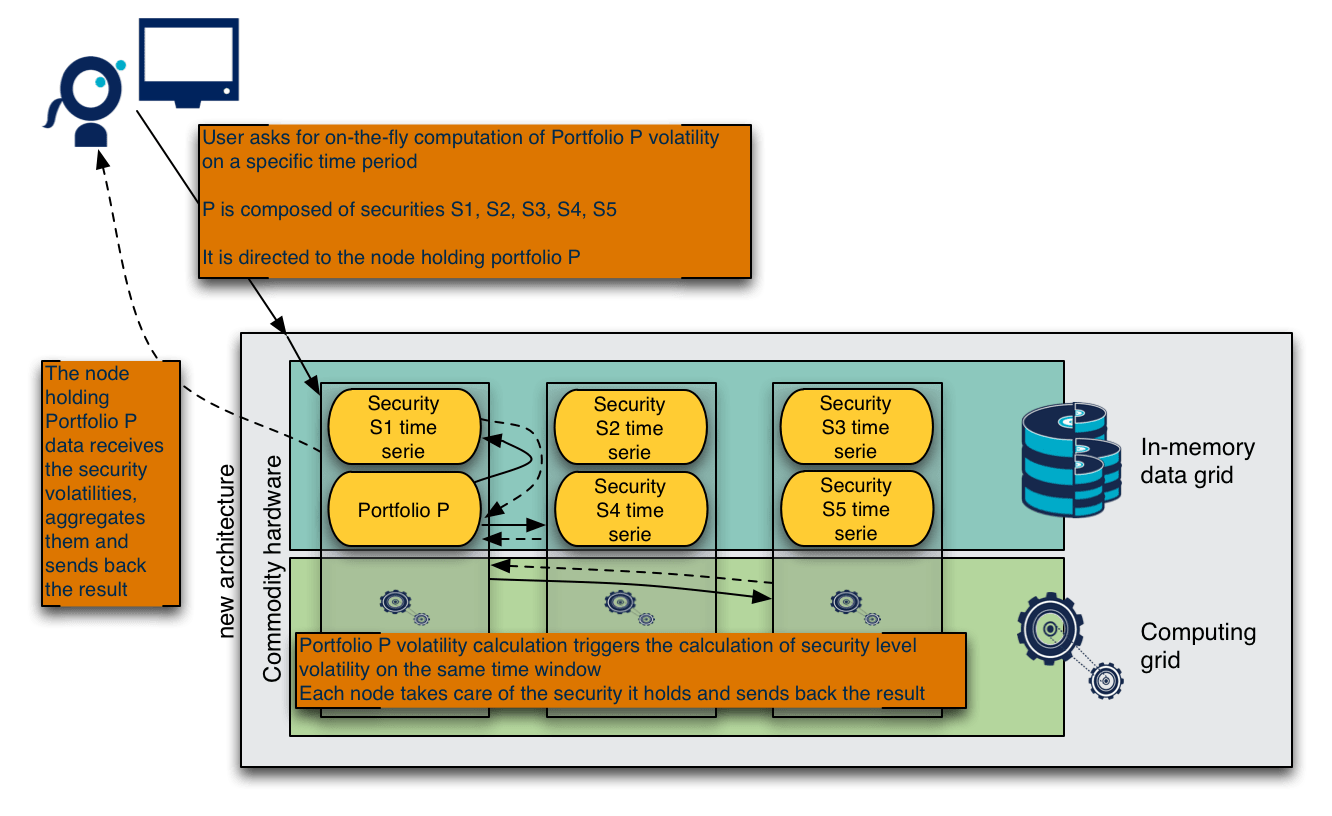
Near-real-time processing of live data
With these considerations of data grid, computing grid and reactive architecture in mind, we chose to try the Infinispan product (aka JBoss Data Grid). It was a trending product and had been chosen by JBoss as their main data caching product. Additionally, some of the latest grid computing features looked promising and we wanted to test it in a real life use case. We therefore implemented a prototype containing: a data-structure, a "market simulator" to fake a reuters pricing feed, and we implemented the calculation of the portfolio performance and the security variance (describing this prototype is not our point here and will be the subject of a future article). Those were interesting proof of concept since while still easy enough to implement, they required a fair amount of computation and could be easily scaled to a large number of portfolios to test our setup.
We have learned several thing:
If you have more questions about this, be sure to leave a comment, and continue following our blog, there should be a technical article on Infinispan coming in a few weeks.
New paradigms that have emerged in the recent years have allowed for a new class of applications/frameworks. Those have for the main part not found their way yet in the Retail and Private Banking sector but they should. We have seen that by using commodity hardware, those solutions are cheap. Through new architecture, they are made resilient and extremely performant. Finally, they are easy to put in place as they are not intrusive. The solution mentioned above is simply reading from the core banking data, never writing. And it exposes data in services that any front end (like an existing PMS) can consume and overlay on top of the core data coming from the Core Banking System (CBS). This simplicity makes this kind of system easy to setup in existing environments, alongside the CBS, that is by the way not meant to be replaced as it holds the master data and is the ultimately trusted source (especially if some of the realtime metrics are only approximated).
I'll conclude by opening a new door. Nowadays, additional focus is put on risk management and in particular on credit management. An architecture as described above can be fully leveraged to realize what-if scenarii, simply by faking the inputs (market events) in the system. While banks are today building complex what-if systems completely separate from their core banking one, the kind of platform we described before enables a smooth integration of the online platform and the what-if simulation, which of course means a lot less development and maintenance work.