Les enjeux autour de la donnée sont en train de changer par rapport à ce que l’on connait depuis les SGBDR : volume de plus en plus important, nombre d’utilisateur croissant, accès concurrents et transactionnels intensifs à la fois en lecture et en écriture, haute disponibilité à des niveaux coûts acceptables, coût de licence. Dans un tel contexte, les bases de données traditionnelles peuvent montrer leurs limites.
Parmi les différentes réponses à ces enjeux que l’ont a vu émerger ces dernières années, deux d’entre elles se sont révélées particulièrement efficaces :
Les data grids ont challengé les SGBDR en réunissant les deux précédentes réponses : du partitionnement et du stockage mémoire (suivant les configurations choisies). Les acteurs sont multiples : Oracle, Gigaspaces mais également GemStone (VMWare)
GemFire est la solution de cache distribué éditée par GemStone Systems, récemment acquis par VMWare. Encore appelé « VMware vFabric GemFire », GemFire est un composant de l’écosystème vFabric de VMware.
Cette solution propose, en plus de son framework, des mécanismes avancés de partitionnement (« sharding »), de persistance et de réplication. Ecrit en Java, GemFire peut fonctionner sur une JVM 32 ou 64 bits, c’est à dire sur n’importe quel OS compatible. Les clients peuvent être écrits à la fois en C++, C# ou Java grâce aux API fournies.
GemFire est un cache orienté-objet qui offre les services d’une base de donnée traditionnelle : OQL (une extension orientée objet du langage SQL), transactions (implémente l’interface JTA), cohérence des données (selon le paramétrage choisi), persistance sur disque (via les mécanismes de write behind ou write through), ou encore tolérance aux pannes.
En plus de ces fonctionnalités classiques, on retrouve également des mécanismes plus spécifiques comme le « continuous querying » permettant d’être notifié lorsque le résultat d’une requête a changé, ou le « function execution », permettant de distribuer un traitement au sein du clustrer GemFire. Ce sujet sera l’objet de la deuxième partie de cet article
Un système distribué GemFire se compose de membres, des processus Java connectés les uns aux autres au travers d’un réseau. Chaque membre embarque un cache, fonctionnant soit en mode stockage (« data host ») soit en mode proxy (« data accessor »). Dans le premier cas, des données peuvent être écrite localement puis propagées ; dans l’autre cas, le cache agira comme une simple passerelle vers les données distantes contenues dans la grille de données.
On distingue ainsi deux types de membre :
Ces membres se découvrent entre eux de deux façons :
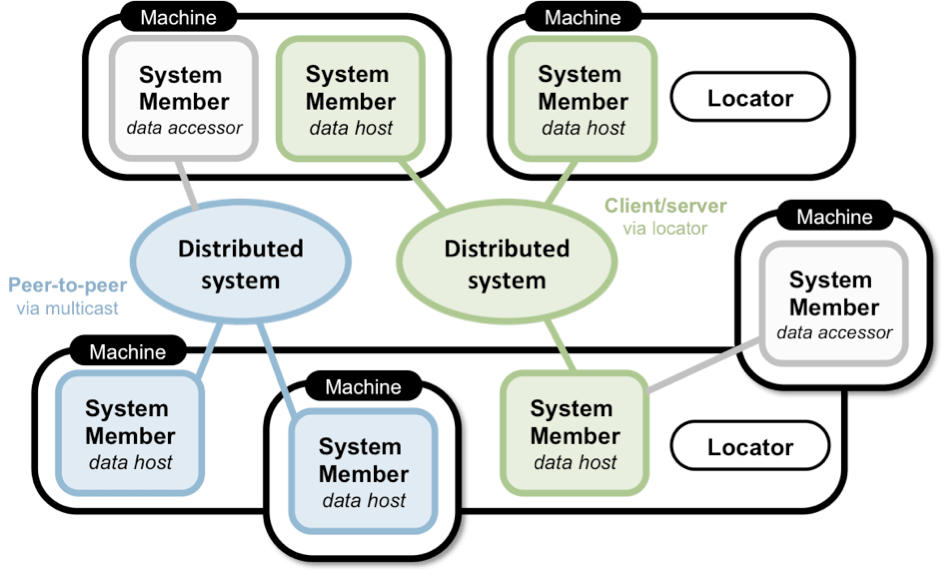
Dans le schéma précédent, on observe que le système distribué peut adopter plusieurs topologies :
Pour synchroniser les différents nœuds, GemFire propose une API de propagation par delta permettant de réduire les échanges sur le réseau, surtout dans le cas de régions fortement répliquées.
Dans GemFire, le concept principal est celui de région. Une région, encore appelé « data set », est un groupe logique dans lequel sont stockées les données.
Chaque région possède sa propre configuration (modèle de données, type de partitionnement, présence de réplication, nature de la persistance, gestion des événements). Cette configuration devra être déclarée à l’identique dans chacun des membres utilisant la région. Elle se fait via un descripteur XML ou programmatiquement, au travers de l’API GemFire.
Toute région implémente la bien-connue interface java.util.Map : la manipuler ne devrait pas poser de problème ! Les données y sont donc stockées sous forme de clef/valeur. Clefs et valeurs prennent toutes deux la forme d’un objet Java, toutefois, la clef sera le plus souvent une simple chaine de caractères.
On dénombre 4 types de régions :
GemFire offre 3 modes de distribution (ou « scope ») des données permettant d’assurer différents niveaux de cohérence :
Le requêtage des données d’une région se fait via OQL. Ce langage répond à des besoins standard en autorisant l’utilisation de clauses SQL bien-connues telles que SELECT, FROM ou WHERE. Il est également possible de réaliser des jointures entre régions et des indexes.
Toutefois, les requêtes OQL sont soumises à certaines limitations qui dépendent principalement du type de région sur lequel on les exécute. Ces limitations concernent entre autre la cohérence des résultats dans le cas de régions répliquées ou distribuées. En effet, pour ces deux types de région, les requêtes sont effectuées sur les données contenues dans le cache local, qui peut, dans certains cas (race conditions, selon la stratégie de propagation), ne pas être cohérentes à un instant donné.
Lorsque l’on aborde la question du traitement au sein d’une architecture distribuée, on entend souvent parler de MapReduce. Le concept est simple : au lieu de rapatrier les données sur un nœud pour traitement, c’est la fonction réalisant ce traitement qui est envoyé sur chacun des nœuds, c’est à dire au plus proche de la donnée. Ceci offre l’avantage de paralléliser l’exécution de la fonction sur différents nœuds tout en diminuant les échanges au niveau du réseau.
Le « function execution service » fourni par GemFire, bien qu’assez éloigné de MapReduce, s’inspire de ce mécanisme. En voici les détails.
Toute fonction distribuée doit être préalablement déclarée et déployée sur chaque membre d’une région partitionnée lors de son déploiement (descripteur + classpath). Cela implique que ces fonctions aient été préalablement codées en Java, compilées puis éventuellement packagées.
Lorsqu’un client déclenche l’exécution d’une fonction distribuée (action non bloquante pour le client), le serveur (data host) auquel il est connecté va notifier tous les autres serveurs du cluster, contenant localement une partie des données à traiter, d’engager l’exécution de ladite fonction.
Dans le cas ou la fonction retourne des résultats, les différents serveurs vont les soumettre à un collecteur de résultat contenu dans le serveur directement connecté au client. Ce collecteur accumule les résultats jusqu’à ce que chaque serveur ait notifié l’envoie du dernier résultat.
Le client peut alors les récupérer :
La documentation ne spécifie aucun mécanisme de callback permettant de notifier de manière asynchrone la disponibilité d’un résultat complet.
Ces différentes étapes se résument dans le schéma suivant :
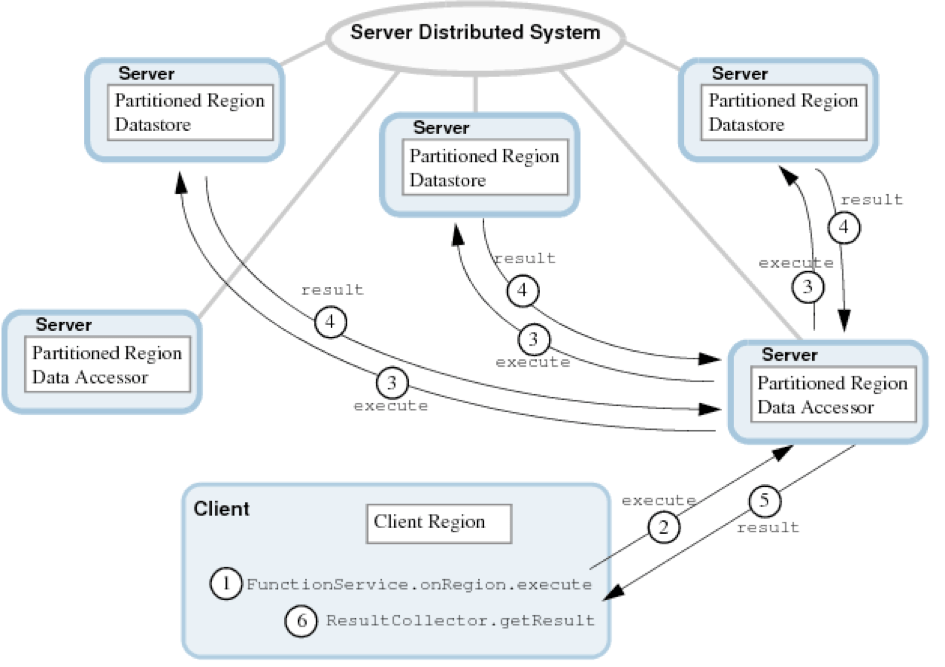
Remarque : le client peut restreindre l’exécution à un, une partie ou tous les membres d’une région. Il peut également spécifier directement les clefs qui seront soumise au traitement. Ces possibilités sont très utiles, par exemple lorsqu’a été défini une politique de partitionnement spécifique.
Afin d’expérimenter le traitement distribué, nous nous sommes placé dans le contexte d’un service web. Cet exemple entre dans la continuité d’un POC réalisé en interne chez Octo. Nous avons souhaité calculer à la demande des informations statistiques sur la vitesse de véhicules au travers de données brutes remontées par ces derniers.
L’architecture visée se compose des éléments GemFire suivants :
L’exécution de notre fonction distribuée va nécessiter 4 classes :
Détaillons tour à tour chacune de ces 4 classes.
Cette classe contient le traitement a effectuer par chacun des data hosts auxquels elle sera soumise. Toute fonction distribuée doit implémenter les interfaces Function et Declarable, cette dernière interface permettant d’être déclarée au sein d’un descripteur XML (voir la partie déploiement). Ci-après, le code commenté de la classe SpeedAverageFunction.
import com.gemstone.gemfire.cache.Declarable;
import com.gemstone.gemfire.cache.Region;
import com.gemstone.gemfire.cache.execute.Function;
import com.gemstone.gemfire.cache.execute.FunctionContext;
import com.gemstone.gemfire.cache.execute.RegionFunctionContext;
import com.gemstone.gemfire.cache.execute.ResultSender;
import com.gemstone.gemfire.cache.partition.PartitionRegionHelper;
import com.gemstone.gemfire.cache.query.SelectResults;
import com.gemstone.gemfire.cache.query.TypeMismatchException;
import com.octo.rtf.ws.model.VehicleMessage;
public class SpeedAverageFunction implements Declarable, Function {
@Override
public void init(Properties props) {
// Distributed function name extracted from XML descriptor
functionName = props.getProperty("name");
}
@Override
public void execute(FunctionContext fc) {
RegionFunctionContext context = (RegionFunctionContext) fc;
// Get local region data
Region localRegion = PartitionRegionHelper.getLocalDataForContext(context);
// Get the result collector
ResultSender resultSender = context.getResultSender();
// Retrieve arguments
String[] args = (String[]) context.getArguments();
try {
// Execute the query
SelectResults queryResults = localRegion.query(formQuery(args));
// Extract the results
Map results = queryRouteAverage(queryResults);
for (String key : results.keySet()) {
Integer[] data = results.get(key);
// Send each result to the collector
resultSender.sendResult(new Object[] {key, data[0], data[1]});
}
resultSender.lastResult(null);
} catch (
}
@Override
public boolean hasResult() {
// Does the function return results ?
return true;
}
@Override
public boolean isHA() {
// Is the high availability option set ?
return false;
}
@Override
public boolean optimizeForWrite() {
// Does the function write results on region ?
return false;
}
}
Cette classe implémente l’interface ResultCollector<T extends Serializable,S extends Serializable>. T correspond à l’objet en entrée, c’est à dire retourné par les data hosts lorsqu’ils récupèrent des données (dans le cas de notre SpeedAverageCollector, un tableau d’objet), et S correspond à l’objet en sortie, c’est à dire retourné au client (ici, un objet SpeedAverageResult).
Ci-après, le code commenté de la classe SpeedAverageCollector.
import com.gemstone.gemfire.cache.execute.FunctionException;
import com.gemstone.gemfire.cache.execute.ResultCollector;
import com.gemstone.gemfire.distributed.DistributedMember;
public class SpeedAverageCollector implements ResultCollector {
SpeedAverageResult sar = new SpeedAverageResult();
public SpeedAverageCollector() {}
@Override
public void addResult(DistributedMember memberID,
Object[] resultOfSingleExecution) {
// Executed when a member return a result
if (resultOfSingleExecution == null) return;
String type = (String) resultOfSingleExecution[0];
int value = (Integer) resultOfSingleExecution[1];
int weight = (Integer) resultOfSingleExecution[2];
sar.addResult(type, value, weight);
}
@Override
public void clearResults() {
// When the function is reexucted
sar = new SpeedAverageResult();
}
@Override
public void endResults() {
// When a member sends its last result
}
@Override
public SpeedAverageResult getResult() throws FunctionException {
// Return the result (blocks until the last result is sent)
return sar;
}
@Override
public SpeedAverageResult getResult(long timeout, TimeUnit unit)
throws FunctionException, InterruptedException {
// Returns the result (blocks until timeout)
return getResult();
}
}
Cette classe va contenir l’ensemble des résultats et leurs accesseurs. Elle doit implémenter l’interface Serializable afin de pouvoir transférée aux data hosts via le réseau. Ci-après, le code commenté de la classe SpeedAverageResult.
public class SpeedAverageResult implements Serializable {
private Map results;
public SpeedAverageResult() {
results = new HashMap();
}
public void addResult(String type, int value, int weight) {
if (!results.containsKey(type)) {
results.put(type, new Integer[] {value, weight});
} else {
Integer[] data = results.get(type);
data[0] += value;
data[1] += weight;
}
}
public Double getAverage() {
int sum = 0, num = 0;
for (String type : results.keySet()) {
Integer[] data = results.get(type);
sum += data[0];
num += data[1];
}
if (num == 0) return new Double(0);
else return (double) (sum / num);
}
public Map getAverageByHighway() {
Map result = new HashMap();
for (String type : results.keySet()) {
result.put(type, getAverageForHighway(type));
}
return result;
}
public Double getAverageForHighway(String type) {
Integer[] data = results.get(type);
return (double) (data[0] / data[1]);
}
}
Cette classe va permettre de se connecter en tant que client au système distribué GemFire. Elle va récupérer et fournir une instance de la région qui permettra de stocker les messages de nos véhicules connectés. La méthode getSpeedAverageFromVin() permettra de déclencher l’exécution de la fonction distribuée sur notre région. Ci-après, le code de la classe GemFireManager
import com.gemstone.gemfire.cache.Region;
import com.gemstone.gemfire.cache.client.ClientCache;
import com.gemstone.gemfire.cache.client.ClientCacheFactory;
import com.gemstone.gemfire.cache.client.ClientRegionShortcut;
import com.gemstone.gemfire.cache.execute.Execution;
import com.gemstone.gemfire.cache.execute.FunctionService;
import com.octo.rtf.ws.model.VehicleMessage;
public class GemFireManager {
private static final String LOCATOR_IP = "192.168.56.101";
private static final int LOCATOR_PORT = 55221;
private static final String REGION_NAME = "VehicleMessageRegion";
private static final String FUNCTION_SPEEDAVERAGE = "SpeedAverage";
private static ClientCache cache;
private static Region region;
public GemFireManager() {
// Create a local client cache
cache = new ClientCacheFactory()
.addPoolLocator(LOCATOR_IP, LOCATOR_PORT)
.set("log-level", "error").create();
// Get the region
region = cache.createClientRegionFactory(ClientRegionShortcut.PROXY)
.create(REGION_NAME);
}
public SpeedAverageResult getSpeedAverageFromVin(String vin) {
Execution execution = FunctionService
.onRegion(region)
.withCollector(new SpeedAverageCollector())
.withArgs(new String[] {vin});
SpeedAverageCollector collector = (SpeedAverageCollector) execution
.execute(FUNCTION_SPEEDAVERAGE, true, false, false);
return collector.getResult();
}
}
La région que nous allons créer ici devra stocker l’ensemble des messages remontés par les véhicules. Ces messages contiennent des données brutes, parmi lesquels un timestamp, la vitesse instantanée et le type de route emprunté.
Pour définir cette région, utilisons un descripteur XML :
<?xml version=<em>"1.0"</em> encoding=<em>"UTF-8"</em>?>
<!DOCTYPE cache PUBLIC
"-//GemStone Systems, Inc.//GemFire Declarative Caching 6.5//EN"
"http://www.gemstone.com/dtd/cache6_5.dtd">
<cache>
<region name=<em>"VehicleMessageRegion"</em> refid=<em>"PARTITION"</em>>
<region-attributes>
<value-constraint>com.octo.rtf.ws.model.VehicleMessage</value-constraint>
</region-attributes>
</region>
<function-service>
<function>
<class-name>com.octo.rtf.ws.gemfire.SpeedAverageFunction</class-name>
<parameter name="name"><string>SpeedAverage</string></parameter>
</function>
</function-service>
</cache>
Le descripteur est plutôt explicite : nous définissons ici un cache contenant une région partitionnée nommée VehicleMessageRegion, dont la valeur sera un objet VehicleMessage. La clef sera une simple chaine de caractère (non spécifiée donc nature par défaut). Enfin nous spécifions une fonction exécutable au travers de son identifiant « SpeedAverage ».
Locator et CacheServer sont des processus Java indépendants. Afin d’être lancés, déclarons quelques variables d’environnement permettant de régler définitivement le problème des dépendances.
# VARIABLES GEMFIRE
GF_JAVA=$JAVA_HOME/bin/java; export GF_JAVA
PATH=$PATH:$JAVA_HOME/bin:$GEMFIRE/bin; export PATH
GEMFIRE=/srv/GemFire6514
CLASSPATH=$GEMFIRE/lib/gemfire.jar:$GEMFIRE/lib/antlr.jar:$GEMFIRE/lib/gfSecurityImpl.jar:$CLASSPATH; export CLASSPATH
Afin de déployer notre système distribué GemFire, choisissons la méthode du locator (par opposition à la méthode multicast). Le locator est un processus à l’écoute d’un port, réalisant la coordination entre les différents membres du système distribué GemFire. Le Locator peut être respectivement lancé et arrêté au travers des commandes suivantes.
gemfire locator-stop -port=55221 -address=192.168.56.101
gemfire locator-start -port=55221 -address=192.168.56.101
Pour fonctionner, un cacheserver a besoin d’un répertoire de travail dans lequel il persistera les données (si l’option est spécifiée) ainsi que les différents logs.
Démarrons deux cacheservers dans deux répertoires distincts.
mkdir ./server1 ./server2
cacheserver start locators=192.168.56.101[55221] mcast-port=0 cache-xml-file=.. /server.xml -server-bind-address=192.168.56.101 -server-port=0 -dir=./server1
cacheserver start locators=192.168.56.101[55221] mcast-port=0 cache-xml-file=../server.xml -server-bind-address=192.168.56.101 -server-port=0 -dir=./server2
Pour stopper ces deux cacheserver, il suffit d’utiliser les commandes suivantes
cacheserver stop -dir=./server1
cacheserver stop -dir=./server2
Le système est maintenant prêt à opérer. Pour voir un exemple du résultat, n’hésitez pas à consulter le screencast disponible dans la deuxième partie de l’article concernant le push web.
Nous avons pu constater au travers de cet article que :
Les fonctions distribuées ne forment cependant qu’une partie de ce que propose GemFire. Le framework offre également d’autres outils, comme la propagation par deltas pour réduire la charge sur le réseau ou le mécanisme de « Continuous Querying » qui permet d’être notifié sur changement du résultat d’une requête ou de l’état d’une région…
{kind=link}
{kind=link}
{kind=link}