"La complexité, c'est comme le cholestérol. Il faut surtout se débarasser du mauvais." (Proverbe gascon-malgache)
DDD est l’acronyme de Domain Driven Design. Ce n’est ni un framework, ni une méthodologie, mais plutôt une approche décrite dans l’ouvrage du même nom d’Eric Evans. Un de ses objectifs est de définir une vision et un langage partagés par toutes les personnes impliquées dans la construction d’une application, afin de mieux en appréhender la complexité. Nous ne souhaitons pas faire ici une présentation de DDD (voir plutôt ici pour une introduction). Nous voulons montrer comment DDD peut adresser certaines problématiques évoquées dans l’article “J’ai mal à mon application ! Ca se soigne ?” au travers d’un exemple d'application (“je veux vendre et acheter des légumes sur internet”), tout en s’inscrivant dans une démarche de développement Agile.
Dans notre exemple, on veut créer un site web qui permet aux agriculteurs de mettre en vente leur production, et aux consommateurs d’acheter ces produits. Il s'agit là de notre Bounded Context, c’est-à-dire les bornes de notre domaine. Imaginons une équipe projet Agile typique pour assurer le build et le run de cette application : Product Owner, experts métier, développeurs...
L’équipe doit produire des Users Stories qui représentent les besoins utilisateur à implémenter. C'est également l'occasion de définir le langage partagé (Ubiquitous Language) :
Ici, les termes et expressions “consommateur”, “agriculteur”, “spécification d'une mise en vente autorisée”... font partie du langage partagé de notre contexte. Ils pourront être utilisés indifféremment par l’ensemble des acteurs projets et désigneront toujours les mêmes concepts : ils constituent le “langage pivot” des échanges entre ces différents acteurs. C’est une des raisons pour lesquelles tous les acteurs impliqués dans la construction du produit doivent être présents lors des ateliers de cadrage des User Stories, chaque intervenant pouvant contribuer et s’imprégner du langage commun. Une piste pour partager ce dernier peut être de définir un lexique dans une page wiki.
Voyons maintenant comment implémenter ces User Stories...
Dans la plupart des applications, nous observons très souvent la même architecture : IHM + services procéduraux + objets du domaine anémiques + accès aux données (typiquement via un ORM). On retrouve alors souvent des services dont le code ressemble à ce qui suit :
public void acheterDesLegumesAUnAgriculteur(Integer consomateurId, Integer agriculteurId, Integer legumeId, Integer quantite){
Consommateur consommateur = consomateurWsClient.getConsommateur(consomateurId);
Agriculteur agriculteur = agriculteurDAO.getById(agriculteurId);
consommateur.getPanier().put(legumeId,quantite);
verifierAgriculteurALeLegume(agriculteur,legumeId,quantite);
BigDecimal prix = recupererPrix(agriculteur,legumeId,quantite);
bankService.transfererArgent(consommateur.getRib(),agriculteur.getRib(),prix);
agriculteur.putLegume(legumeId,agriculteur.getLegume(legumeId)-quantite);
agriculteurDAO.save(agriculteur);
String message = creerMessageAchat(agriculteur,legumeId,quantite);
mailService.sendMail(consommateur.getMail(),message);
}
On constate que le code de cette méthode s’apparente à un script, qui manipule des structures de données et invoque des “fonctions” exposées par des composants plus ou moins techniques.
Finalement, nous utilisons ici très peu les concepts inhérents au paradigme du langage, dont la notion même d’objet comme structure de données capable de répondre à des messages, d’interagir. C’est là tout le paradoxe du langage objet utilisé pour faire de la programmation procédurale ! En fait, la plupart des systèmes sont modélisés par leurs données, et non par leurs interactions.
Nous avons pourtant l’impression que la programmation orientée objet pourrait nous aider à traiter plus efficacement des problèmes complexes, en s'appuyant sur des patterns et principes tels que l’encapsulation ou la séparation de responsabilités. Ça tombe bien, car la POO est au coeur de DDD ! Et notamment au coeur du modèle du domaine.
Cette activité doit nous permettre de nous attaquer à la complexité essentielle, c'est-à-dire celle qui est consubstancielle du problème à résoudre. Quelle est notre problématique métier ? Quels sont les "objets" mis en jeu ? Quels sont les comportements, les règles qui régissent les interactions ? Le modèle du domaine doit être “ubiquitous”, c’est-à-dire partagé par l’ensemble des acteurs contribuant à la construction du produit. Les noms et les verbes utilisés font partie de l'ubiquitous language. L’architecture logicielle qui va porter notre application devra être au service de notre domaine.
En début d’itération, l’équipe définit et échange sur les User Stories à traiter et s’accorde un temps de réflexion pour partager sa vision du modèle du domaine. Utilisateurs et experts métiers apportent leur connaissance du problème à résoudre ; développeurs et architectes fournissent leur point de vue d'experts techniques. L’équipe doit garder en tête que le modèle retenu a une limite de validité (modèle valide sous contraintes), puisqu'il est conçu pour :
On peut utiliser un tableau blanc et dessiner une représentation du modèle. Pour faire cela, UML peut aider, mais un AGL n’est pas nécessaire. Il n’est pas non plus nécessaire d’avoir une représentation exhaustive du modèle. La représentation que l’on donne n’est qu’un moyen d’échange, de partage de la compréhension par l'ensemble des acteurs. Puisque le modèle est ubiquitous, si l'on souhaite conserver une représentation particulière, il faut se poser la question : quelle représentation de notre modèle ne pourra-t-on pas retrouver dans le code ?
La littérature abonde sur les éléments qui peuvent constituer un modèle du domaine à la sauce DDD. On peut notamment citer :
Ces patterns peuvent aider à mieux structurer le code, à séparer les responsabilités et expliciter les concepts. Idéalement, ils sont connus par l'ensemble de l'équipe, y compris les profils non techniques : les échanges seront d'autant plus facilités que les concepts seront partagés.
Le schéma ci-après illustre notre vision du coeur du modèle du domaine de l’application de vente de légumes. On ne s'intéresse ici qu'aux éléments saillants du modèle. Pour une meilleur lisibilité, nous avons formalisé notre modèle en UML. On retrouve ainsi les Aggregate Roots Agriculteur, Consommateur et Legume.
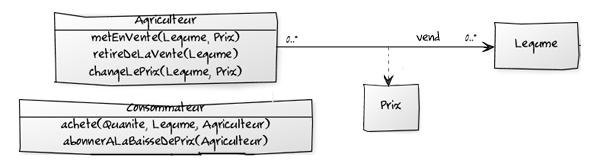
Un bon test de recette du modèle produit est : quelqu’un qui n’est pas impliqué dans la construction du produit arrive-t-il a comprendre ce que fait l’application ?
Il faut également faire attention à ne pas "surdesigner". Les principes KISS et YAGNI restent valables pour la modélisation du domaine. Il faut assumer que le modèle n'est qu'une représentation incomplète de la réalité. Il n'est pas nécessaire non plus de mettre dans son application tous les designs patterns du GoF .
Il faut également surveiller l'évolution dans le temps du modèle du domaine, et le refactorer lorsque c'est nécessaire. En effet, on peut arriver progressivement à un effet plat de spaghettis, c'est-à-dire que les dépendances entre objets du modèle sont très nombreuses. Dans ce cas, il faut peut-être définir de nouveaux agrégats, afin de gagner en cohésion et de masquer les entités aggrégées au reste du modèle. Si le modèle contient trop de classes pour que l'on puisse se représenter son fonctionnement, c'est qu'il adresse certainement trop de problématiques. Il faudra alors définir autant de Bounded Contexts qu'il y a de problématiques. C'est également un axe qui permet de scaler une équipe, en créant des sous-équipes dédies à chacun de ces nouveaux contextes.
L'architecture logicielle qui portera le domaine est celle proposé par Eric Evans:
Cette couche a pour responsabilité de :
Cette couche a pour responsabilité de coordonner les activités de l’application. Elle ne contient pas de logique métier et ne maintient aucun état des objets du domaine. Elle peut cependant maintenir un état de la session applicative. Elle porte la gestion des transactions et la sécurité. Sa responsabilité est également de récupérer les objets du domaine via le repository pour “injecter” la dynamique dans le domaine. Enfin, elle est également en charge de l'ajout ou la suppression d'objets dans le repository.
Pour illustrer un exemple de service applicatif de notre application, on a choisi le service d’achat de légumes :
public void acheterDesLegumesAUnAgriculteur(Integer consommateurId, Integer agriculteurId, Integer legumeId, Integer quantite){
Consommateur consommateur = consommateurRepository.getById(consommateurId);
Agriculteur agriculteur = agriculteurRepository.getById(agriculteurId);
Legume legume = legumeRepository.getById(legumeId);
consommateur.achete(quantite,legume,agriculteur);
}
Cette couche comporte toutes les classes correspondant aux éléments du modèle du domaine.
Pour illustrer le code d’un Aggregate Root, on a choisi la méthode de mise en vente d'un légume :
public class Agriculteur {
Integer id;
Map legumesALaVente ;
public void metEnVente(Legume legume, Prix prix){
if(!MiseEnVenteAutoriseeSpecification.isSatisfiedBy(this,legume,prix)){
this.legumesALaVente.put(legume, prix);
DomainEvents.notify(new AgriculteurAMisEnVenteLegumeEvenement(this.id,this.legume,this.prix));
}else{
throw new MiseEnVenteNonAutoriseeException(agriculteur,legume);
}
}
...
}
On remarque que :
Une fois le traitement métier de mise en vente réalisé, un évènement du domaine est produit pour notifier tous les composants intéressés. Le bus exploité dans notre exemple est un bus synchrone, le but étant simplement ici de réaliser une séparation de responsabilités. Ainsi, un composant métier pourra s'occuper de l’envoi d’un e-mail à tous les consommateurs pour les notifier de cette mise en vente : c'est une conséquence de l'évènement de mise en vente, et cette conséquence n'est pas sous la responsabilité de l'objet Agriculteur !
Cette gestion reposant sur des domain events permet donc de mieux séparer les responsabilités des différents objets. Néanmoins, l’augmentation du nombre d’évènements échangés peut rapidement amener à un modèle plus complexe à comprendre qu’un simple séquencement de traitements.
Cette couche sert les autres couches, notamment pour :
L'anti-corruption consiste à éviter la pollution du domaine par un modèle externe, tel que celui d’une autre application du SI. Cette notion correspond à ce que nous nommons, chez OCTO, le pattern "Royaume-Emissaire". Prenons l'exemple de l'Aggregate Root "Consommateur". Je peux récupérer un consommateur particulier en interrogeant le ConsommateurRepository. Mais pour répondre à ma demande, le repository aura peut-être besoin de récupérer un objet externe (en provenance d'une autre application) via un appel Web Service. Pour cela, il s'appuiera sur un composant dédié de la couche d'infrastructure. Ensemble, le repository et la couche d'infrastructure fournissent un mécanisme d'anticorruption vis-à-vis de notre modèle : l'objectif est de ne pas introduire de dépendance forte de notre modèle vers un modèle externe, dont nous ne maîtrisons pas les évolutions et qui n'est probablement pas adapté à nos besoins...
Bref, l'important à retenir, c'est que tout élément introduisant une complexité non essentielle (non liée à notre problématique métier) doit être "emprisonné" dans une couche d'infrastructure / anti-corruption.
Finalement, cette architecture en couches n'est pas si éloignée de ce que l’on rencontre dans bon nombre d’applications. La différence fondamentale est que le domaine est un ensemble d’objets “intelligents” et que le code du domaine est suffisamment expressif pour que l’on comprenne ce que fait l’application.
DDD n’est pas le silver bullet qui garantit l’application parfaite. Si la démarche apporte des réponses pragmatiques sur le partage et la compréhension du produit construit, certaines limites subsistent.
On retiendra les points suivants :
Points positifs de l’architecture
Points négatifs de l’architecture
Certains éléments de DDD aident sur des problématiques fondamentales de l’industrie logicielle :
Nous pensons que les pratiques suivantes peuvent réellement aider dans l'atteinte de ces objectifs :
Le modèle du domaine permet d’exprimer clairement les règles de gestion et le comportement de nos applications. Néanmoins, la limite du modèle du domaine, tel qu’il a été présenté dans cet article, est atteinte. Celui-ci convient parfaitement pour le traitement et la persistence de l’information, ainsi que le contrôle de sa cohérence. En revanche, il ne semble pas adapté à la lecture d'informations à partir du système, pour laquelle la flexibilité et la performance de l'accès aux données peuvent être cruciales.
Dans un article à suivre, nous vous proposons de découvrir le pattern CQRS, et d’en extraire quelques bonnes idées afin d'améliorer notre architecture.