Depuis le début de l’année 2020, le monde vit au rythme du coronavirus. Plusieurs pays ont été obligés de ralentir, voire arrêter pour certains secteurs, leurs activités. Après de nombreuses semaines de confinement, si les entreprises s’apprêtent petit à petit à reprendre leurs activités, elles doivent cependant garantir la sécurité de leurs employés en faisant respecter les règles de distanciation physique et les gestes barrières imposés par les autorités.
Plusieurs initiatives sont aujourd’hui en cours autour du Smart Building de l’après-confinement. Ces initiatives ont pour but de repenser le lieu de travail et de l’adapter à la situation inédite dans laquelle nous vivons aujourd’hui.
Nous aborderons dans cet article un cas d’usage parmi les différentes initiatives qui ont été proposées. Ce cas d’usage consiste à détecter sur un flux vidéo d’un lieu donné les personnes présentes et de mesurer la distance les séparant les unes des autres, le but étant de remonter des alertes. Une alerte est remontée si la distance mesurée est inférieure à un mètre.
D’un point de vue pratique, le modèle de détection que nous aurons créé pourrait être utilisé - par exemple - dans des entrepôts avec des caméras à disposition. L’objectif serait alors de réaménager le lieu de travail en s’appuyant sur la répartition spatiale des alertes qui auront été remontées. Nous avons donc construit une application web qui fournit des informations sur le flux vidéo, telles que le nombre de personnes, le nombre de personnes à moins de 1 mètre les unes des autres ou encore les alertes.
Pour ce cas d’usage, nous nous appuyons sur la démarche suivante :
Figure 1: Démarche générale de notre cas d’usage
Au delà de l’aspect pratique de notre cas d’usage, nous étaierons tout au long de l’article les différents aspects techniques et théoriques de notre démarche.
Pour pouvoir calculer les distances réelles entre les personnes dans un flux vidéo, il faut avoir une vue Top-Down de celui-ci. Dans la littérature, on parle également de vue plongeante ou vue aérienne ou encore en anglais Bird’s Eye View.
La plupart des caméras n’ont pas de vue plongeante et sont légèrement inclinées. La vidéo peut être prise à partir d’une vue en perspective arbitraire.
Cette étape est appelée calibration. Son objectif est de trouver la relation entre les coordonnées spatiales d’un point de l’espace en vue plongeante avec le point qui lui est associé dans le flux vidéo. Concrètement, l’étape de calibration consiste à calculer l’homographie, qui transforme la vue en perspective en une vue plongeante.
Prenons l’exemple suivant pour mieux comprendre :
Figure 2 : Les deux images à gauche représente la vue en perspective, les deux images à droite la vue plongeante après avoir appliqué la transformation aux images sources. Lien du premier exemple, Lien du deuxième exemple
Le but de la calibration est, par exemple, de récupérer les informations de la caméra telles que la distance focale, la taille des pixels, l’emplacement du montage…
La transformation géométrique entre l’image source et l’image destination est décrite par une matrice homographique H de taille 3x3. Une homographie 2D est une transformation linéaire entre deux plans projectifs.
C’est à dire qu’un ensemble de point sur un plan P1 (dans son système de coordonnée) peut être projeté sur un deuxième plan P2 en des points donnés par la relation :
est le produit de matrices affines (de translation, de rotation et de scaling).
la matrice de projection. Pour plus de détails, se référer à l’article Bird’s Eye View.
Pour obtenir cette matrice homographique, nous avons besoin d’au moins deux ensembles de points, chaque ensemble représentant un objet dans la vue en perspective de l’image et ce même objet dans la vue plongeante de cette image.
Dans le deuxième exemple de la figure 2, l’image source est une vue de face en perspective d’un hall de gare. Sur cette image, le carrelage au sol du hall a la forme d’un parallélogramme. Nous savons que sur notre vue plongeante, il est en réalité représenté par un rectangle. Les deux ensembles choisis pour trouver la transformation sont donc le parallélogramme pour l’image source et le rectangle pour l’image destination.
En pratique, le choix de ces ensembles de points est arbitraire mais ils doivent représenter des polygones convexes (n-gons avec n≥4) pour pouvoir calculer la bonne matrice homographique. Dans notre cas, cette opération est faite manuellement. Toutefois, il existe des méthodes comme la transformée de Hough qui le fait automatiquement. Plus la zone couverte par le polygone est grande, plus l’étalonnage est précis.
Nous considérons les points sources suivants :
Pour avoir un système de coordonnées homogènes, nous représentons nos points sources ainsi :
Les points destinations dépendent des points sources. Si nous considérons que les points sources représentent un rectangle dans la vue plongeante, cet ensemble sera défini comme suit :
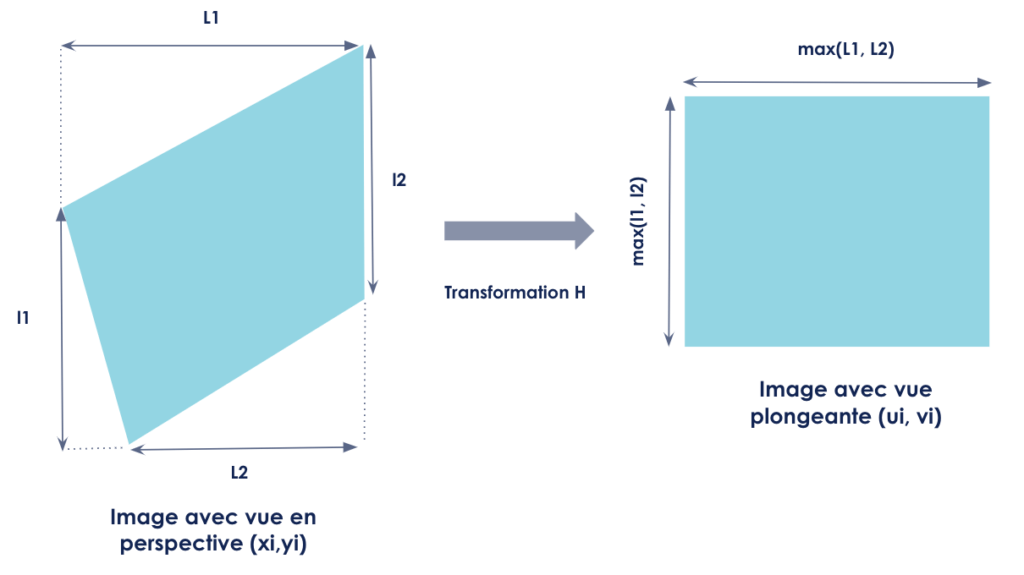
Figure 3 : Passage des points sources avec vue en perspective (à gauche) aux points destinations avec vue plongeante (à droite).
Nous transformons nos points destinations en coordonnées homogènes et nous obtenons de la même manière que pour les points sources :
Il nous faut donc résoudre l’équation suivante pour trouver notre matrice homographique H, qui transforme nos points sources en nos points destinations connus
Il s’agit donc de résoudre un système linéaire. Si vous souhaitez rentrer dans le détail des calculs vous pouvez vous référer à la présentation de Jean-Philippe Tardif, ou encore le papier de Chien-Chuan Lin.
Après la résolution du système linéaire, nous obtenons notre matrice homographique qui va permettre de transformer la vue en perspective de notre image en une vue plongeante.
Seulement, avant d’appliquer la matrice de transformation à notre image, il faut avoir recours à une petite astuce_._ En effet, si nous appliquons la matrice telle quelle à l’image source, il est possible qu’après transformation, une partie de l’image source n’apparaisse pas dans l’image destination. En effet, la transformation pourrait produire des coordonnées en dehors du cadre de l’image, voire négatives.
Pour éviter ce problème, il faut d’un côté choisir une taille optimale pour l’image destination et d’un autre appliquer une translation aux coordonnées de nos pixels, de sorte que toute l’information de l’image source soit présente sur l’image destination.
Une propriété de l’homographie nous a permis de rendre cela possible : l’homographie est invariante par multiplication. Si A et B sont deux homographies alors A*B représente toujours une homographie qui applique B dans un premier temps puis A à nos coordonnées.
Par conséquent, pour éviter que les coordonnées transformées sortent du cadre, il nous suffit de les multiplier par une matrice homographique de translation pure.
Pour rappel, une matrice homographique 2D a pour forme :
avec R qui représente la rotation, T la translation et P la déformation en perspective. Par conséquent, une homographie qui comprend uniquement une translation ressemble à ceci :
Il nous reste donc à trouver ce x_trans et y_trans qui nous permettront de faire la bonne translation.
Le calcul correspondant consiste en 3 étapes dès lors que nous avons notre matrice homographique H calculée:
Les coins de l’image source sont transformés en appliquant la matrice homographique H. Nous récupérons ensuite les valeurs maximales et minimales des coordonnées x et y des coins transformés, que nous nommerons xmin, xmax, ymin et ymax.
Nous calculons la matrice de translation T nécessaire pour mapper le point (xmin, ymin) à (0,0). Cette matrice T est donc égale à :
Il ne nous reste plus qu’à appliquer cette transformation optimisée à l’ensemble de notre image source pour obtenir une image bien calibrée (cf. Figure 2).
D’autres méthodes plus récentes existent comme celle décrite dans ce livre est fait pour vous.
L’image calibrée résultante sera ensuite utilisée pour calculer les distances réelles séparant les personnes détectées sur notre flux vidéo. Avant de calculer les distances entres les personnes, il nous faut donc au préalable les détecter. Pour cela, nous avons procédé à l’étape de modélisation décrite dans la partie qui suit.
L’étape de modélisation consiste à créer le modèle permettant de détecter les personnes sur les flux vidéos. Concrètement, quand on parle de détection, on parle de prédiction de bounding box au niveau des flux vidéos. Une bounding box est le plus petit rectangle contenant l’objet à détecter au niveau de l’image ou la frame d’une vidéo.
Aujourd’hui, il existe plusieurs modèles de détection de personnes et d’objets en vision par ordinateur (Computer Vision). Pour notre cas d’usage, nous avions utilisé des modèles qui ont déjà été entraînés et qu’on peut trouver en open source. L’objectif était d’abord d’utiliser un modèle “simple” et de regarder son comportement avant l’utilisation d’un modèle un peu plus sophistiqué.
Le premier modèle que nous avons choisi d’utiliser est une combinaison entre la méthode HOG pour Histogram of Oriented Gradients et un SVM linéaire pour Support Vector Machine. Le HOG est une méthode qui suppose que la forme locale d’un objet et son apparence peuvent être décrites par la distribution des gradients et l’orientation des contours. Elle consiste donc à diviser l’image en plusieurs zones uniformément réparties et calculer les histogrammes locaux de l’orientation des gradients.
Figure 4 : Exemple d’un histogramme de gradients orientés
Ces différents histogrammes calculés représentent les features (variables) de notre matrice d’apprentissage sur lesquelles un SVM linéaire est entraîné, chaque image représentant une observation de cette matrice. Le jeu de données utilisé pour la phase d’apprentissage est un dataset d’images de piétons disponible ici.
Nous avions remarqué que le modèle ne détectait pas toutes les personnes sur toutes les frames d’un flux vidéo et avions donc choisi d’utiliser un deuxième modèle. En effet, pour ce type de problème de vision par ordinateur, les méthodes basées sur l’apprentissage profond ont démontré une meilleure performance par rapport aux méthodes classiques telles que le HOG + SVM.
Pour répondre à notre problématique, nous avons opté finalement pour un modèle de réseaux de neurones. Il s’agit du modèle Mask R-CNN qui se base essentiellement sur les réseaux de neurones convolutifs qu’on appelle en anglais CNN pour Convolutional Neural Network. Le Mask R-CNN en est effectivement une version sophistiquée et améliorée.
Nous n’allons pas aborder la notion de CNN dans cet article puisqu’elle a déjà été présentée dans un article précédent. Toutefois, nous rappelons à travers le schéma suivant les différentes couches constituant un CNN :
Figure 5 : Schéma d’un CNN capable de classifier si l’objet détecté sur l’image est une personne ou non
Dans un CNN traditionnel, les couches de convolution ont pour but d’extraire, grâce aux filtres de convolution, les caractéristiques de l’image. Une première couche de convolution pourrait par exemple extraire les zones de l’image où il y a des contours.
Contrairement à un problème de classification classique, un problème de détection nécessite de connaître la localisation des objets au niveau de l’image. Pour détecter des personnes sur un flux vidéo avec des CNNs, une approche consiste à utiliser une fenêtre glissante sur toute l’image et sur laquelle nous réalisons une tâche de classification qui indique s’il s’agit ou non d’une personne. Néanmoins, plus le réseau de neurones est grand, plus la localisation d’une personne sur l’image devient compliquée, puisque le temps d’entraînement augmente considérablement.
Une autre approche consiste à regrouper des pixels similaires, grâce à un algorithme de segmentation, pour former une région. Cette “région” est ensuite donnée en entrée au classifieur, ici un CNN, pour identifier l’objet au niveau de cette région.
Le modèle R-CNN (Regions with CNN Features) s’inscrit dans ce nouveau paradigme qu’on appelle Recognition using regions.
Figure 6 : Schéma d’un R-CNN
Il consiste en 3 phases :
La première phase a pour objectif d’identifier les régions pouvant contenir des objets. Cette identification repose sur l’algorithme Selective Search. Il s’agit d’un algorithme de segmentation qui se base sur le regroupement hiérarchique. On peut utiliser la texture et la couleur des pixels comme mesure de similarité.
La deuxième phase, permet à partir d’un CNN de récupérer les différentes features de l’image pour chaque région identifiée.
La troisième phase consiste à utiliser un SVM dont le rôle est de classifier les différents objets.
Le R-CNN donne de bons résultats en termes d’accuracy pour un problème de détection d’objet. Seulement, ce dernier est très lent en termes de vitesse de calcul, puisqu’il faut entraîner un CNN pour l’extraction des features et plusieurs SVMs pour la classification d’objets dans les images.
En effet, avec l’architecture du R-CNN, le CNN analyse chaque région d’intérêt proposée par l’algorithme Selective Search et nous n’avions pas la possibilité de faire des calculs en parallèle.
C’est pour faire face à ces différents problèmes que le Fast R-CNN a été créé. Celui-ci est 9 fois plus rapide qu’un R-CNN, comme nous pouvons le lire dans l’article de Ross Girshick. Néanmoins, ces deux algorithmes dépendent en grande partie de l’algorithme Selective Search qui permet d’identifier les régions d’intérêt dans l’image.
Une nouvelle approche a permis de le remplacer par un nouveau réseau appelé Region Proposal Network qui remplit exactement la même tâche que celui-ci mais qui est totalement intégré dans le réseau. Le Region Proposal Network est placé juste après la dernière couche de convolution et est donc appliqué à la dernière matrice de features calculée.
Il est important de retenir que grâce à ce nouveau réseau, le Fast R-CNN peut réaliser des tâches de détection d’objet en temps réel et est donc plus rapide d’où l’appellation Faster R-CNN. Nous laissons au lecteur le soin de se renseigner sur l’architecture du modèle décrite en détails dans l’article Faster R-CNN.
Comme nous l’avions indiqué précédemment, c’est le Mask R-CNN que nous avons utilisé pour notre cas d’usage. Ce réseau a la même architecture de base que le Faster R-CNN. La légère différence est qu’en plus de prédire les bounding box et leurs classes correspondantes, deux autres couches de convolution ont été ajoutées au réseau et vont permettre de prédire aussi les masques des objets détectés.
Un masque d’un objet est le rassemblement de pixels représentant cet objet, comme le montre la figure suivante :
Figure 7 : Bounding box, Classes (Labels) et masques des différentes personnes détectées
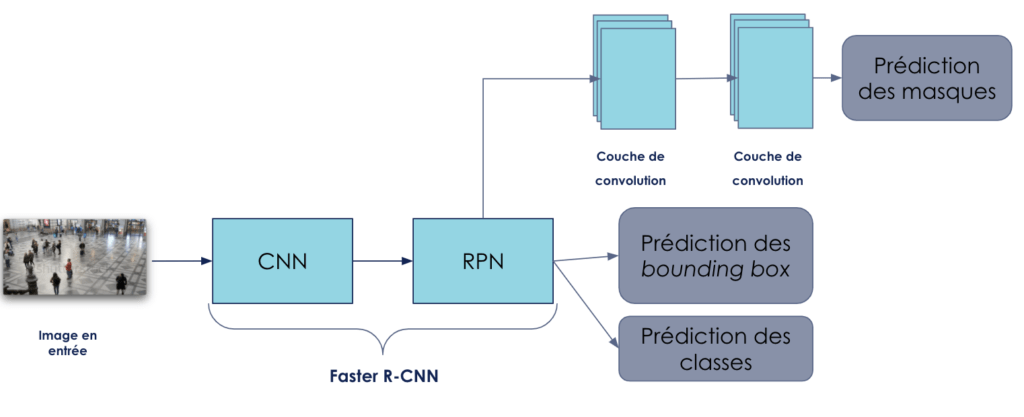
Figure 8 : Architecture simplifiée d’un Mask R-CNN
En effet, en plus de détecter les objets, le Mask R-CNN va permettre également de les segmenter. La segmentation, c’est l’opération par laquelle on rassemble les pixels représentant un objet donné. Concrètement, la segmentation d’un objet est la prédiction de son masque au niveau de l’image.
Concernant notre cas d’usage, le Mask R-CNN que nous avions choisi a été entraîné sur le jeu de données COCO et est capable de segmenter plusieurs centaines d’objet. Dans notre cas précis, nous nous intéressons uniquement à la détection de l’objet dont la classe est “person”.
Une fois que les personnes présentes dans le flux vidéo ont toutes été détectées grâce à notre modèle Mask-R-CNN, nous récupérons le centre des bounding-box (rectangles qui encadrent les personnes détectées dans l’image) auquel nous appliquons la transformation homographique calculée dans la première partie. En effet, le modèle Mask-R-CNN a été appliqué sur l’image source, non transformée. Cette transformation nous permettra donc de récupérer les distances réelles séparant les personnes.
Nous parcourons ainsi les frames de la vidéo une à une et nous calculons, pour chaque personne détectée sur la frame, les distances qui la séparent des autres personnes détectées. Nous parcourons ensuite toutes les distances calculées, si une des distances est inférieure à un seuil choisi, ici 1 mètre, alors nous récupérons son centre qui est enregistré dans la liste d’alertes qui sera remontée une fois la vidéo entièrement parcourue.
Une fois toutes les frames de la vidéo parcourues, nous pouvons récupérer cette liste d’alertes qui contient les centres des distances des personnes trop proches, soit des points de l’image. Nous pouvons donc à partir de ces points construire une heatmap pour chaque frame qui fera ressortir les zones de l’image qui auront reçu des alertes. Ces heatmaps sont superposées aux frames ce qui nous donne l’aperçu suivant :
Figure 9 : Résultat de la superposition de la heatmap qui compte de nombre d’alertes sur la frame. Lien
En plus des alertes, nous avons pu récupérer des informations supplémentaires, à chaque seconde de la vidéo, comme le nombre de personnes, le nombre de personnes proches, le taux de personnes proches et le nombre d’alertes. Ces informations ont été stockées dans un dataframe que l’utilisateur peut consulter depuis l’application web.

Figure 10 : Aperçu de l’application web qui fournit les données du flux vidéo
L’idée de l’application est de regarder les graphes des informations remontées c’est à dire le nombre de personnes ou le taux de personnes proches par exemple et observer la distribution spatiale et temporelle des différentes alertes. Cela permettrait d’identifier les périodes de la journée où on observe le plus d’alertes mais aussi les zones spatiales où il y a le moins de distanciation. Ainsi, cette analyse conduirait à réaménager les locaux de l’entreprise et adapter les heures de travail des différents collaborateurs.
En conclusion, nous avons opté pour la méthode classique concernant la calibration qui est le calcul de la matrice homographique à partir de points de références sur l’image source et l’image destination. Cette méthode a l’avantage d’être rapide et interprétable. Néanmoins, la qualité et la précision de nos résultats dépendent énormément du choix de ces points qui se fait manuellement.
Une approche différente pourrait consister en l’utilisation de plusieurs ensembles de points de références (trois ensembles de quatre points par exemple) et de procéder de manière itérative par optimisation d’une fonction d'évaluation pour obtenir une matrice homographique plus robuste, ou encore utiliser des CNN comme mentionné plus haut.
Quant à la détection des bounding box, le modèle des Mask-RCNN s’est montré être assez performant. Effectivement, près de 65% en moyenne des personnes sont détectées sur le flux vidéo utilisée. Il faut, cependant, préciser qu’il atteint cette performance à condition que la taille de l’image analysée ne soit pas trop petite. En effet, dès que la taille de la frame du flux vidéo est assez petite, le modèle a du mal à détecter les différentes personnes.
Une idée d’amélioration du modèle serait, éventuellement, de lui ajouter un algorithme de tracking des différentes personnes détectées par le Mask-RCNN, permettant ainsi de remonter davantage d’informations comme le laps de temps où deux mêmes personnes restent proches.
Nous espérons que ce travail pourra être utile et aider les entreprises à faire face à ces nouvelles contraintes imposées par les conditions actuelles.
Rich feature hierarchies for accurate object detection and semantic segmentation, https://arxiv.org/pdf/1311.2524v5.pdf
Fast R-CNN, https://arxiv.org/pdf/1504.08083.pdf
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, https://arxiv.org/pdf/1506.01497.pdf
Mask R-CNN with OpenCV, https://www.pyimagesearch.com/2018/11/19/mask-r-cnn-with-opencv/
Pedestrian detection OpenCV, https://www.pyimagesearch.com/2015/11/09/pedestrian-detection-opencv/