Le mouvement « DevOps » nous invite à repenser la frontière classique de nos organisations qui séparent d’un côté les études, i.e. ceux qui écrivent le code des applications (les « Dev ») et de l’autre côté la production, i.e. ceux qui déploient et exploitent ces applications (les « Ops »).
Ces réflexions sont certainement aussi anciennes que les DSIs mais elles trouvent un peu de fraîcheur grâce notamment à deux groupes. D’un côté les agilistes qui ont levé la « contrainte » côté développement, et sont maintenant capables de « livrer » beaucoup plus souvent du logiciel valorisé par le client… de l’autre, des experts ou des managers de la « prod » des grands du web (Amazon, Facebook, LinkedIn…) partageant leurs retours d’expérience et la façon qu’ils ont d’aborder la frontière « dev » et « ops ».
Au-delà de la beauté intellectuelle de l’exercice, DevOps travaille surtout (oserais-je dire uniquement) sur la réduction du TTM (Time To Market). Il y a certes d’autres effets positifs ou de nécessaires améliorations autour de la culture, de la communication, de l’accélération des déploiements ou des approvisionnements mais l’enjeu d’ordre un, au final, reste bien ce fameux « Time To Market » (pas très étonnant dans l’industrie du web).
Au-delà des fractures organisationnelles, les préoccupations des études et de la production sont bien distinctes et respectivement louables :
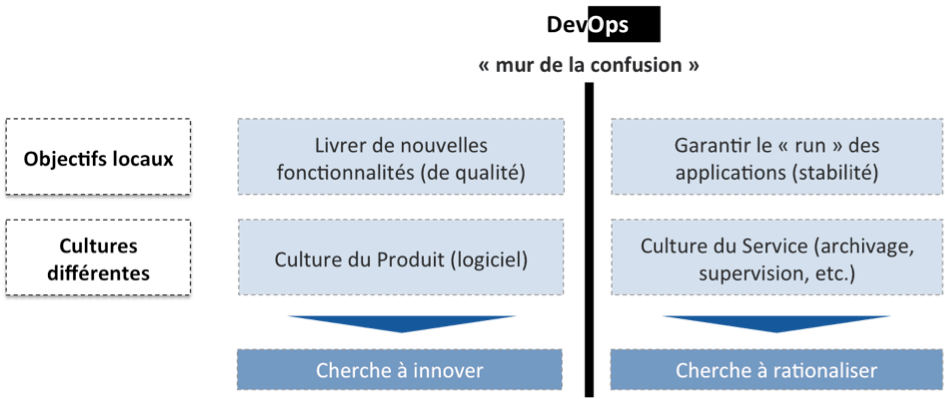
Les études recherchent plus de réactivité (sous la pression du métier et du marché notamment) : il faut aller vite, ajouter de nouvelles fonctionnalités, réadapter les directions, refactorer, upgrader les frameworks, déployer rapidement sur de nouveaux environnements pour tester… C’est la nature même du code (« Soft ») : malléable, adaptable.
A l’inverse, la production a besoin de stabilité et de standardisation.
Stabilité car il est souvent difficile d’anticiper quels impacts auront telles modifications de code, d’architecture ou d’infrastructure : un disque local qui devient un disque réseau mais impacte les temps de réponses, ou bien un changement de code qui impacte fortement la consommation CPU et par là même le « capacity planning ».
Standardisation enfin car la production veut s’assurer que certaines règles (configuration des machines, versions logicielles, sécurité réseau, configuration des fichiers de logs, …) sont uniformément respectées pour assurer la qualité de service de l’infrastructure.
Reste que ces deux groupes, « dev » et « ops » ont pourtant bien un objectif commun : faire fonctionner le système vu du client final.
L’agile est apparu en France il y a maintenant plus de 6 ans avec comme principal objectif de lever la contrainte autour du processus de développement.
Cette méthodologie introduisait les notions de cycles courts, de feedback terrain et client, la notion de Product Owner, une personne du métier responsable de la roadmap, des priorisations…
L’agile a également mis à mal l’organisation traditionnelle (dans les DSI Françaises tout du moins) en introduisant des équipes pluri-disciplinaires (du métier aux développeurs) et challengeant du même coup les découpages organisationnels.
Aujourd’hui, ces contraintes ont été levées, les développements suivent le plus fréquemment des itérations de 1 à 2 semaines. Les métiers voient le logiciel évoluer durant la phase de construction.
Il est dorénavant temps d’impliquer les personnes de la production sur les phases suivantes :
Un des points de friction les plus visibles dans le manque de collaboration entre dev et ops se trouve au niveau des phases de déploiement. C’est d’ailleurs l’activité qui se montre être la plus consommatrice en ressources : la moitié du temps de la production est ainsi consommée par le déploiement ou des problèmes liés au déploiement.
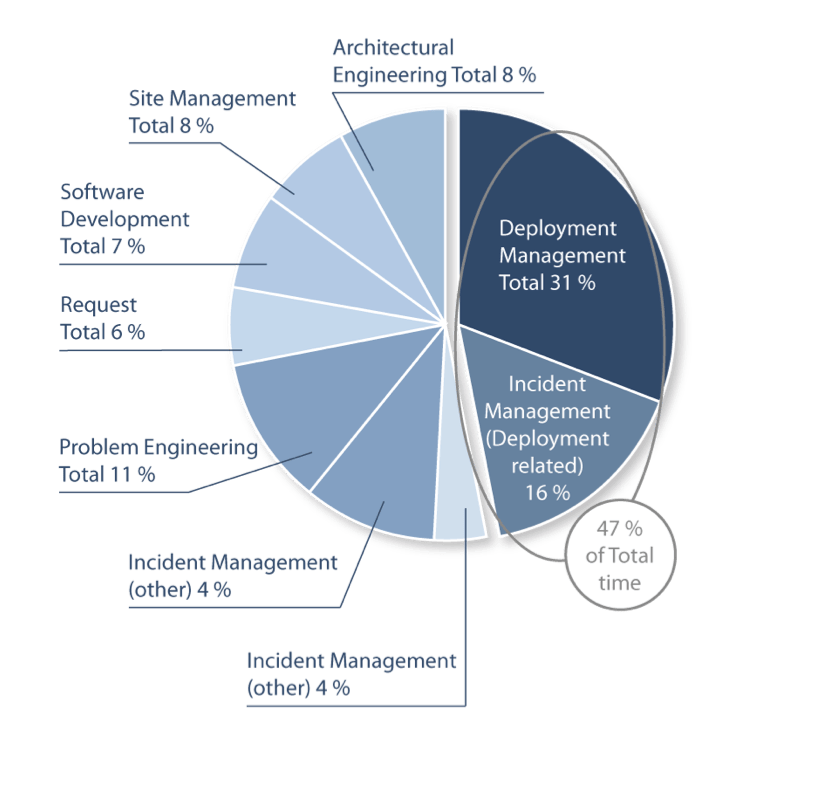
Figure 2. Source : Etude de Deepak Patil (Microsoft Global Foundation Services) de 2006, via une présentation de James Hamilton (Amazon Web Services)
http://mvdirona.com/jrh/TalksAndPapers/JamesHamilton_POA20090226.pdf
Et même s’il est difficile de donner des règles générales, il y a fort à parier qu’une partie de ce coût (le segment à 31%) peut diminuer via l’automatisation de ce processus de déploiement.
Beaucoup d’outils fiables existent aujourd’hui pour automatiser les phases d’approvisionnement et de mise à disposition des environnements, allant de l’instanciation de VM au déploiement applicatif, en passant par la configuration système.
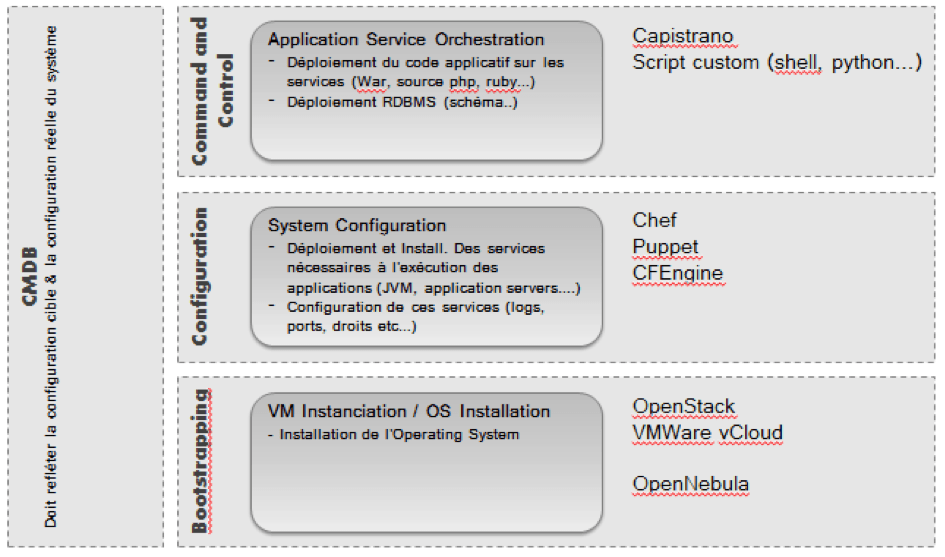
Figure 3. Classement des principaux outils
Ces outils visent à permettre le codage (dans des langages qui leur sont propres) des infrastructures : installation et démarrage d’un service http, du serveur tomcat, création des répertoires pour les fichiers de logs…
Les objectifs et les gains sont multiples :
C’est également au travers de l’automatisation qui pourra s’amorcer un changement de culture dans la collaboration entre dev et ops. L’automatisation permet d’offrir plus de self-service aux équipes de « devs » – a minima sur les environnements ante-prod : un accès en lecture sur des machines ou uniquement aux logs, la possibilité de monter eux-mêmes les environnements d’intégration avec les données de la production à J-1….autant de gains de souplesse pour les « dev », autant de choses que les « ops » n’ont plus à faire.
Classiquement et dans nos organisations, la frontière entre les populations « dev » et « ops » se concrétise par la phase de déploiement où les études « livrent » ou parfois se « débarrassent » de leur code et où ce dernier va suivre un long chemin au travers des couloirs de la MEP (Mise En Production).
Cette citation de Poppendieck (« From Concept To Cash ») résume à merveille l’enjeu qui est soulevé :
« How long would it take your organization to deploy a change that involves just one single line of code? »
Les réponses sont bien entendues moins évidentes et c’est finalement là que se cristallise la divergence d’objectifs. Les études voudraient la main sur une partie de l’infrastructure, pouvoir déployer rapidement, à la demande sur tous les environnements. A l’inverse, la production a le souci des environnements, de la rationalisation des coûts, de l’utilisation des ressources (bande passante, CPU…).
L’autre ironie est que moins on déploie, plus les TTR (Time To Repair) augmentent et donc diminuent la qualité de service rendu au client final.
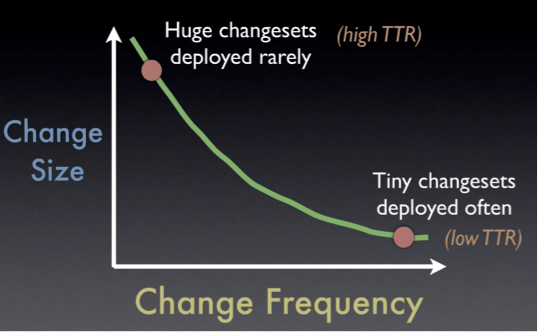
Figure 4. Source : http://www.slideshare.net/jallspaw/ops-metametrics-the-currency-you-pay-for-change-4608108
Autrement dit, plus les modifications apportées entre deux mises en production sont grandes (ie. le volume de code modifiée est important), plus la capacité à corriger rapidement un problème survenu suite au déploiement (donc la phase d’instabilité tant redoutée par les « Ops ») diminue (et donc le TTR augmente).
Là encore travailler sur ce gâchis permet de diminuer la part liée au « Incident Management » de la figure 2.
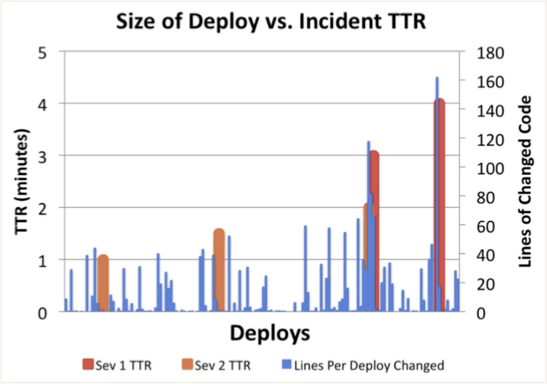
Figure 5. Source : http://www.slideshare.net/jallspaw/ops-metametrics-the-currency-you-pay-for-change-4608108
Pour finir, la figure 5, issue d’une étude de Flickr, montre la corrélation entre les TTR (et donc la sévérité des incidents) en fonction du volume de code déployé (et donc de la quantité de changement introduit).
Néanmoins, mettre en production en continu n’est pas aisé et requiert :
Ces deux pratiques que sont « Infrastructure as Code » et « Continuous Delivery » peuvent être mises en œuvre dans l’organisation telle qu’elle existe traditionnellement (« Infrastructure as Code » chez les ops, « Continuous Delivery » chez les dev). Cependant, une fois que les études et la production auront atteint leur optimum local et un bon niveau de maturité, ces dernières se retrouveront toujours contraintes par cette frontière organisationnelle.
C’est là que le troisième pilier prend tout son sens ; une culture de la collaboration, voire de la coopération, permettant d’autonomiser les équipes et ne plus les rendre interdépendantes/bloquantes d’un point de vue opérationnel. Par exemple pour les « dev », un accès aux logs en lecture sur des machines, la possibilité de monter eux-mêmes les environnements d’intégration avec les données de la production à J-1, l’ouverture aux métriques et aux outils de supervision (voire l’affichage de ces métriques dans les open space)… Autant de gain de souplesse pour les « dev », autant de responsabilisation et de partage de « ce qu’il se passe en prod », autant de tâches à peu de valeur ajoutée que les « ops » n’ont plus à faire.
Les principaux éléments de culture autour de devops peuvent se résumer ainsi :
Reste que dans ce modèle les zones de responsabilités (principalement le développement, la supervision applicative, le support et l’exploitation des data centers) existantes sont quelque peu remises en cause.
Les organisations classiques privilégient l’équipe projet. Dans ce modèle, les processus de déploiement, de supervision applicative et de gestion des datacenters sont répartis sur plusieurs organisations.
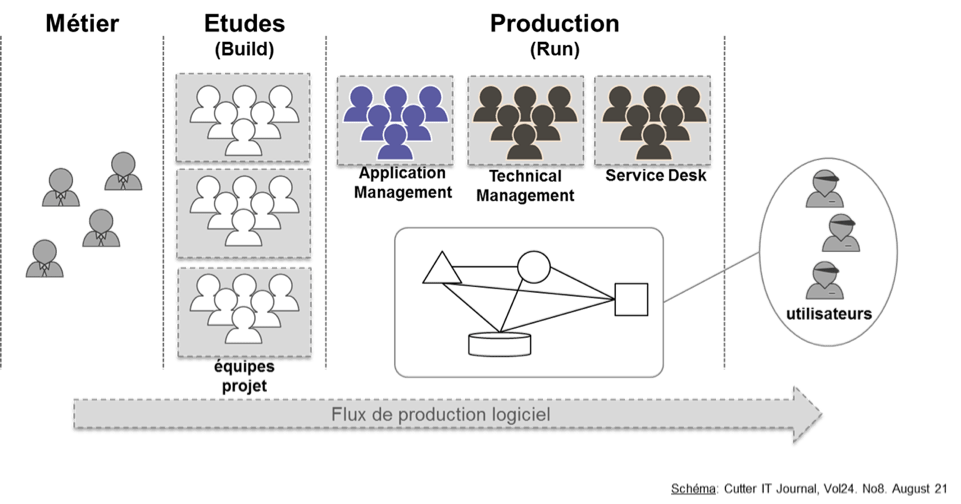
Figure 6 : L’équipe projet
A l’inverse, certains acteurs (notamment Amazon) ont poussé ce modèle organisationnel très loin en proposant des équipes multi-disciplinaires qui sont responsables du bon fonctionnement du service (vu du client).
« You build it, you run it ». Autrement dit, chaque équipe est responsable du métier, du « dev » et des « ops » c’est-à-dire de l’exploitation (déploiement, supervision) de l’application en production.
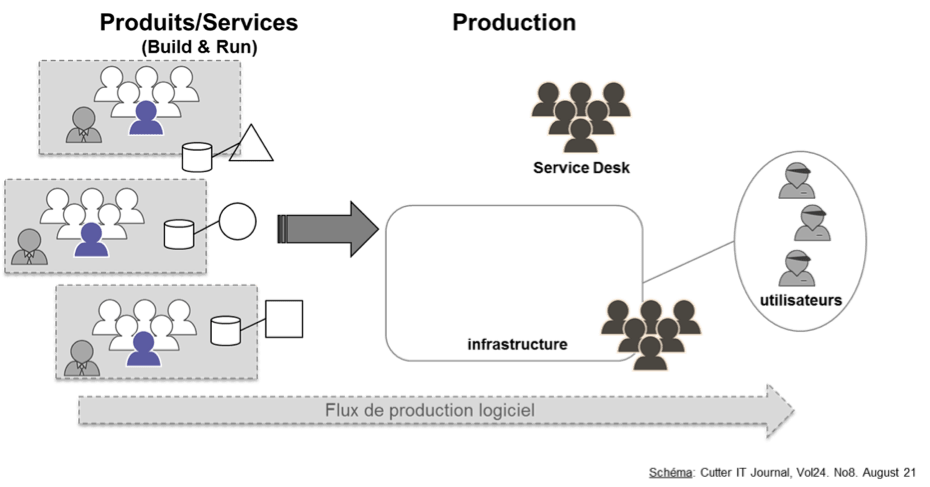
Figure 7 : L’équipe produit : « You build it, you run it »
C’est par ailleurs dans ce type d’organisation que les notions de « self-service » prennent un sens différent et fondamental. Une équipe responsable de l’application et de son fonctionnement, une équipe responsable des datacenters. Une frontière placée plus « en aval » que ce que l’on fait traditionnellement qui permet le passage à l’échelle et assure l’équilibre entre agilité et rationalisation des coûts (notamment lié aux infrastructures datacenters). Le Cloud AWS est très certainement né de là…C’est une autre histoire mais imaginez une organisation en équipe produit et des équipes de production qui proposent une offre de service (au sens ITIL) comme AWS ou Google App Engine…
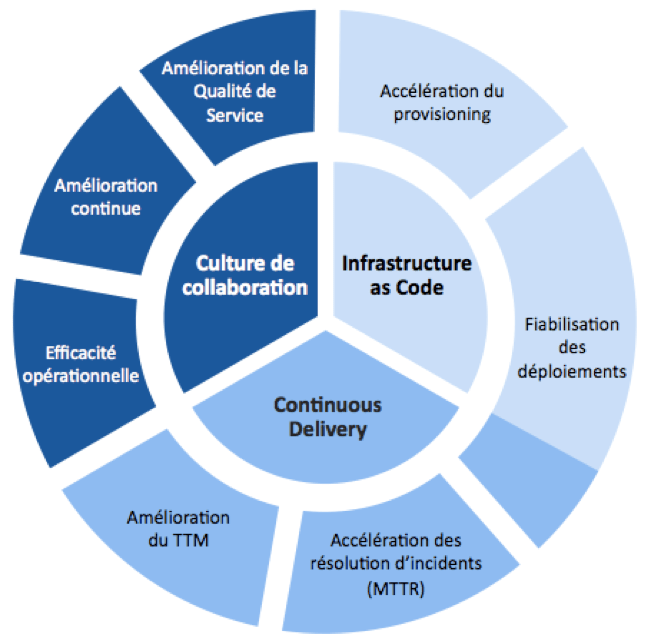
DevOps n’est donc rien d’autre qu’un ensemble de pratiques qui visent à trouver des leviers d’amélioration autour :
En définitive ces 4 axes permettent d’atteindre les objectifs de DevOps : améliorer la collaboration, la confiance et l’alignement d’objectifs entre les études et la production et travailler en priorité sur les douleurs à adresser, synthétisées sur la figure ci-dessous.
Retrouver toutes les pratiques des Géants du Web sur le site dédié (www.geantsduweb.com) : pdf de l'ouvrage à télécharger, vidéo et compte-rendu de la présentation "Décrypter les secrets des Géants du Web"
Références