La semaine dernière avait lieu à Londres Strata conf : deux jours réunissant les spécialistes sur le sujet des Big Data. L'évènement avait lieu pour la première fois en Europe. Ces deux jours ont montré à la fois l'intérêt business de Big Data et l'existence d'outils désormais packagés. En substance Big Data c'est d'abord l'opportunité de croiser les données opérationnelles avec l'immense flot de données du web, des devices mobiles ou autres pour apporter plus de valeur à l'entreprise. Mais c'est aussi de multiples offres d'outil autour de l'offre Open Source Hadoop pour traiter ces données.

Pas moins de trois keynotes nous ont replongés dans l'histoire pour prendre du recul par rapport à ce phénomène Big Data. Tout d'abord, Internet est une révolution comparable à l'invention de l'écriture ou de l'imprimerie. Jusqu'à présent l'informatique se contentait de reproduire des processus existants. Avec internet de nouveaux liens sont apparus entre les personnes. Et demain les capteurs - que je traduirai par extrapolation par l'internet des objets - vont connecter ces nouveaux liens au réel et produire là encore de nouvelles données associées. Big Data matérialise le besoin de traiter ces nouvelles interactions et informations associées. Mark Madsen dans sa keynote parcourait les âges depuis l'invention de nombres il y a 5 000 ans jusqu'à Big Data en passant par l'invention de l'écriture et de l'imprimerie. A chaque fois la quantité et la complexité de l'information ont augmenté. A chaque fois l'homme a inventé de nouvelles métadonnées pour classer cette information : en-tête, chapitres et table des matières, glossaire et dictionnaire. Aujourd'hui ce sont les informations produites par internet que nous sommes en train d'apprendre à gérer. George Dyson et John Gaham-Cumming sont quant à eux revenus sur les premiers âges de l'informatique - évocation de Turing et Babbage pour montrer que nos problèmes Big Data ne sont pas si différents. Ainsi au-delà du problème de quantité - très relatif - c'est souvent le fait de traiter pour la première fois un type d'information qui est compliqué. 
Dans sa keynote Mikael Bisgaard-Bohr citait Andreas Weigandt d'Amazon, "Les mathématiciens sont soudainement sexy". 
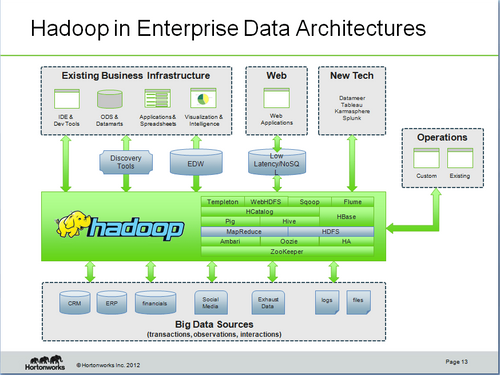
Au-delà des questionnements sur son positionnement dans le SI, la technologie Hadoop progresse vers un plateau de maturité. Les nouveautés d'Hadoop 2.0 ont été conçues pour gagner en scalabilité et atteindre rapidement des clusters de 10 000 noeuds. L'architecture repensée en ce sens se rapproche de celle d'un OS avec la couche YARN responsable de l'allocation des ressources et la couche MR2 (pour MapReduce2) qui elle gère cette API et interagit avec HDFS. MR2 est un peu comme un espace utilisateur vis à vis de YARN qui a le rôle du noyau. Cela permet le développement d'autres solutions non orientées sur MapReduce directement sur la couche YARN. Les développeurs de solution autour des graphs comme HAMA apprécieront. Steve Loughran de Horton Works nous a présenté différentes techniques pour gérer la disponibilité sur de grands clusters Hadoop. Aujourd'hui la version d'Hadoop fournit des mécanismes de reprise à froid (notamment le basculement manuel du namenode) suffisants pour de petits clusters. Les mécanismes de reprise à chaud qu'il faut aujourd'hui compenser par des outils externes sont globalement prévus dans la version HDFS 2.0. Enfin Armund Tveit a fait dans sa session une synthèse des différents papiers de recherche sur les algorithmes autour de MapReduce. Les différentes utilisations de MapReduce peuvent être classifiées de la façon suivante : réduction du volume de données, transformation, ou génération de données. Une littérature se constitue donc autour des meilleures pratiques dans ce domaine. En somme, la technologie Hadoop se stabilise, différentes offres commerciales autour d'Hadoop viennent pérenniser la technologie. Si un travail d'ingénierie reste indispensable, l'offre autour d'Hadoop aujourd'hui est mature et prête à rentrer dans le monde de l'entreprise.
Kathryn Hurley (Google), Simon Rogers (The Guardian) dans leur session insistaient sur le fait que les nombres ont besoin de contexte pour être compréhensibles. Kim Rees insistait pour sa part sur les différents biais qui peuvent exister entre les données, la façon de les présenter et la façon de les lire. Pour donner de la valeur aux données la question de leur représentation est donc essentielle. Plusieurs sessions ont mis en avant des exemples de visualisation des données. Clairement, les diagrammes en barre ne suffisent plus. Beaucoup d'autres représentations émergent mais les lecteurs sont pour l'instant réticents car ils ont l'impression - plutôt à tort au vu d'études comparatives - de ne pas bien interpréter ces schémas ci-dessous. Les lecteurs curieux auront plus d'information dans la vidéo de la session en lien sur l'image. 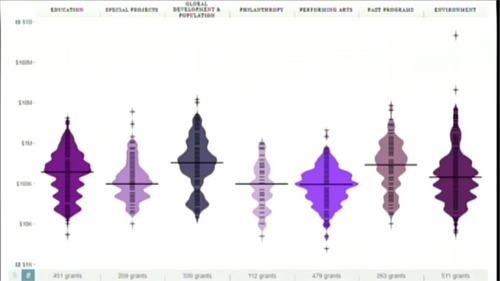
Plusieurs exemples de représentations graphiques autour des flux de population de la ville de Londres ont été présentés dans la session de James Cheshire. Je retiendrai l'utilisation de fonds de carte très sobre et d'animations (points lumineux, traînées de lumière). L'apparition des rues ou des lignes de métro fait alors ressortir les points d'attention. Même si les exemples de cette session ne sont pas disponibles beaucoup d'outils ont été cités. Je retiendrai DataWrapper , Google Maps API. Ces techniques sont utilisées ponctuellement mais vont devoir se généraliser pour permettre à l'être humain d'appréhender plus rapidement ces nouvelles données. Les technologies existent, les capacités sont à l'étude, l'usage de ces nouvelles représentations reste encore à démocratiser.
Prises isolément ces différentes données n'ont pas forcément beaucoup de valeur. Simon Rogers du Guardian montrait la valeur ajoutée à croiser les résultats des jeux olympiques avec les données économiques des pays. James Cheshire citait la comparaison de l'utilisation des bus ou des vélos par rapport à la pollution. L'initiative de l'état britannique de rendre disponible sans frais toutes les archives des lois du Royaume-Uni offre selon moi de nouvelles perspectives. Au delà des choix intéressants sur l'URL et le format des données de ces archives, je retiendrai que le modèle économique est basé sur deux principes. D'une part ces données sont consommées par des intermédiaires qui produisent des produits à valeur ajoutée. L'objectif est ici de créer de la croissance pour l'économie britannique. D'autre part ces intermédiaires par leur retour vont contribuer à améliorer la qualité des données. Lian Maxwell, responsable de la réforme de l'IT ne cachait pas sa volonté de faire de Big Data un moteur de croissance pour l'économie britannique. Au delà du mécanisme Open Data il mettait en avant la volonté de redécouper les contrats gouvernementaux afin de transformer de gros contrats monolithiques et propriétaires en un ensemble de petits contrats interagissant autour de standards ouverts. Big Data fait peur à l'image des ordinateurs dans les années 80. Mais il faut reconnaître que Big Data a une face sombre. Dans une keynote Alasdair Allan nous montrait que même en bloquant ses données de géolocalisation il était possible statistiquement de nous situer dans un lieu avec une probabilité de 70% selon la localisation de nos amis. Ben Goldacre insistait quant à lui sur les effets de biais à travers les exemples des évaluations de médicaments. Lorsque les études présentant des résultats décevants ne sont pas publiées cela crée un effet de biais. Alors que faire? Alasdair Allan enjoignait les institutions à être vigilantes, à s'assurer que l'absence d'information à une heure donnée ne devienne pas synonyme de soupçon de culpabilité. Nous devons apprendre à maîtriser les données qu'on produit et qu'on nous fournit. Et je terminerai par cette session de Jason McFall "Establishing Cause and Effect from Data". Les effets de biais sont fréquents, on tend très souvent à prendre pour fausse une donnée qui ne correspond pas au modèle attendu. Pour pallier à cela les données doivent être produites selon une démarche scientifique. Ainsi, dans un test A/B permettant de comparer deux produits, deux principes sont fondamentaux : réaliser les tests simultanément et avec des échantillons strictement aléatoires. 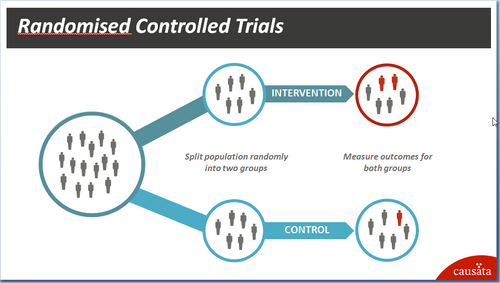
Je retiendrai de ces deux jours que la technologie n'est pas additive mais transformative. Les outils comme Hadoop et NoSQL, issus des Géants du Web comme Google et Amazon, sont comme la presse à imprimerie. Ils ont permis de démultiplier les données de transactions, de les rendre accessibles et surtout de créer de nouvelles interactions entre les personnes et les entreprises. Le concept Big Data est issu de cette nouvelle masse d'informations dont on sent bien qu'elle recèle un potentiel mais qu'on ne maîtrise pas encore totalement. En prenant du recul l'histoire de l'information et de l'informatique montre que les nouvelles techniques ont à chaque fois permis de gérer plus d'informations. Je repars de ces deux jours avec en mémoire des outils de DataVisualisation, une vision sur les algorithmes MapReduce et l'intégration d'Hadoop dans l'architecture d'un SI. La suite reste à construire par tous les participants.