Si tu as loupé la news, la semaine précédente a eu lieu le tant attendu, Data+AI Summit Europe, connu jusque là sous Spark+AI Summit. Comme l’année précédente, on a eu la chance d’y participer. Les organisateurs devraient publier les talks sous peu mais si tu ne peux plus attendre, voici un court résumé de ce qui s’y est passé du point de vue du data engineering.
TL;DR Si tu te poses des questions sur le titre, il est là pour résumer les 2 annonces majeures pour les data engineers. Premièrement, Apache Spark va devenir plus Pythonique grâce au projet appelé Zen. Deuxièmement, il va probablement tourner sur une architecture du type lakehouse. Si tu veux en connaître les détails, tu en trouveras un peu plus bas 👇
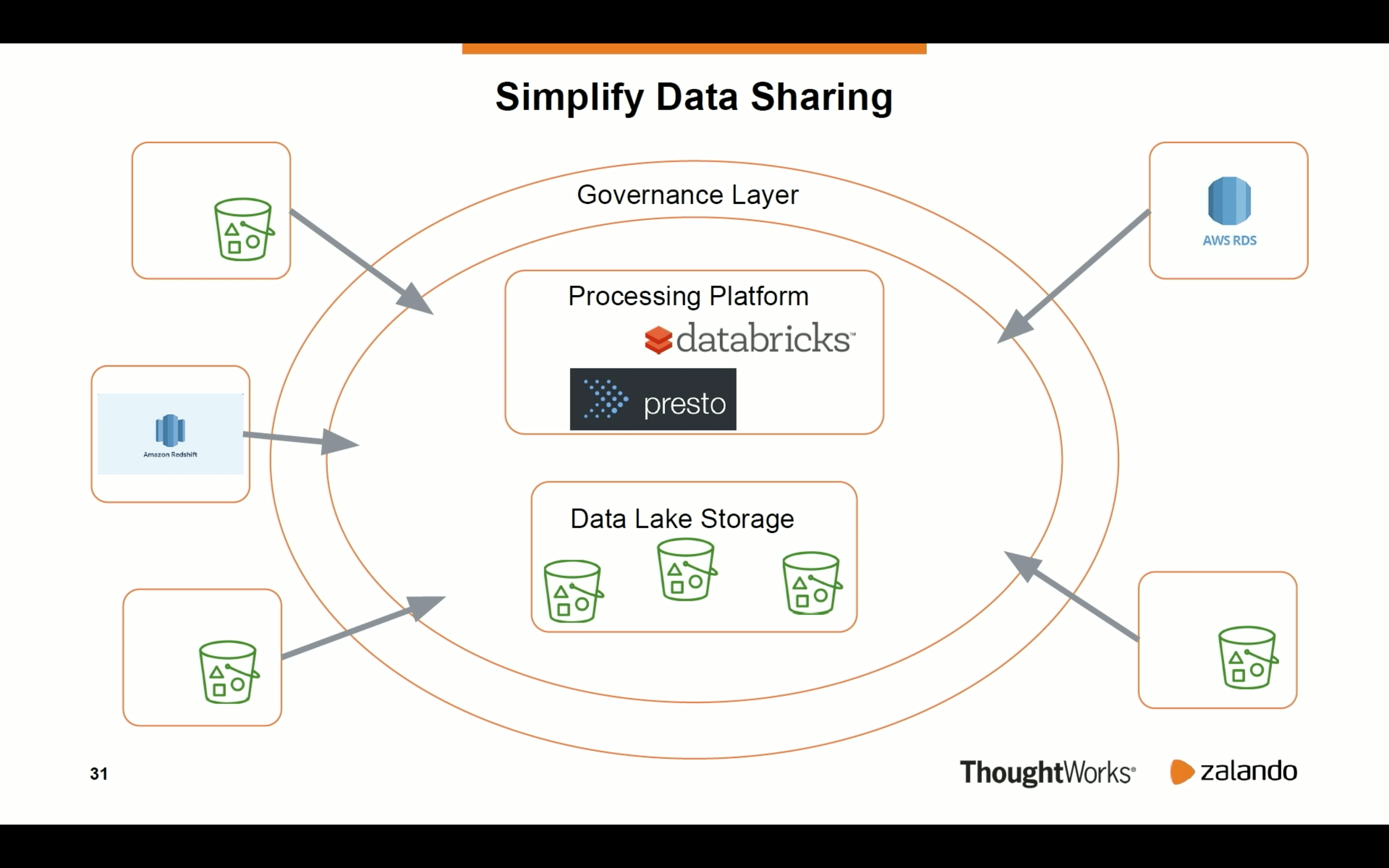
Lakehouse n’était pas la seule architecture présentée lors du Summit. Il y en avait une autre, aussi bien connue que lakehouse, le data mesh. L’approche a été présentée par Zalando dans “Data Mesh in Practice: How Europe’s Leading Online Platform for Fashion Goes Beyond the Data Lake”. Au tout début du talk, Max Schultze a listé tous les points de douleur liés à la gestion centralisée de la donnée, utilisée précédemment chez Zalando:
Ensuite, Dr. Arif Wider de ThoughtWorks a expliqué comment l’approche data mesh peut résoudre ces problèmes pour contenter chacun des acteurs présentés ci-dessous:

Le premier changement concerne l’évolution de la perception de la donnée. Elle n’est plus un “dataset” mais bien un produit géré par une équipe. Et l’équipe est là non seulement pour maintenir le produit mais aussi pour le faire connaître auprès d’autres équipes.
Le second point est lié au Domain-Driven Architecture appliqué à la donnée. L’équipe responsable de dataset a la meilleure connaissance pour répondre à des questions clients et fournir une bonne qualité de produit.
Et finalement, le concept de Data Infrastructure as a Platform. C’est la base technique de toute la plateforme et doit être agnostique. Cela veut dire que chaque équipe “domaine” devrait être indépendante et pouvoir l’utiliser sans aucun problème, aussi bien pour les pipelines batch/streaming, comme pour les scénarios de ML ou data analytics. “Sans aucun problème” est une expression clé ici car il garantit qu’un nouveau point de contention ne sera pas créé.
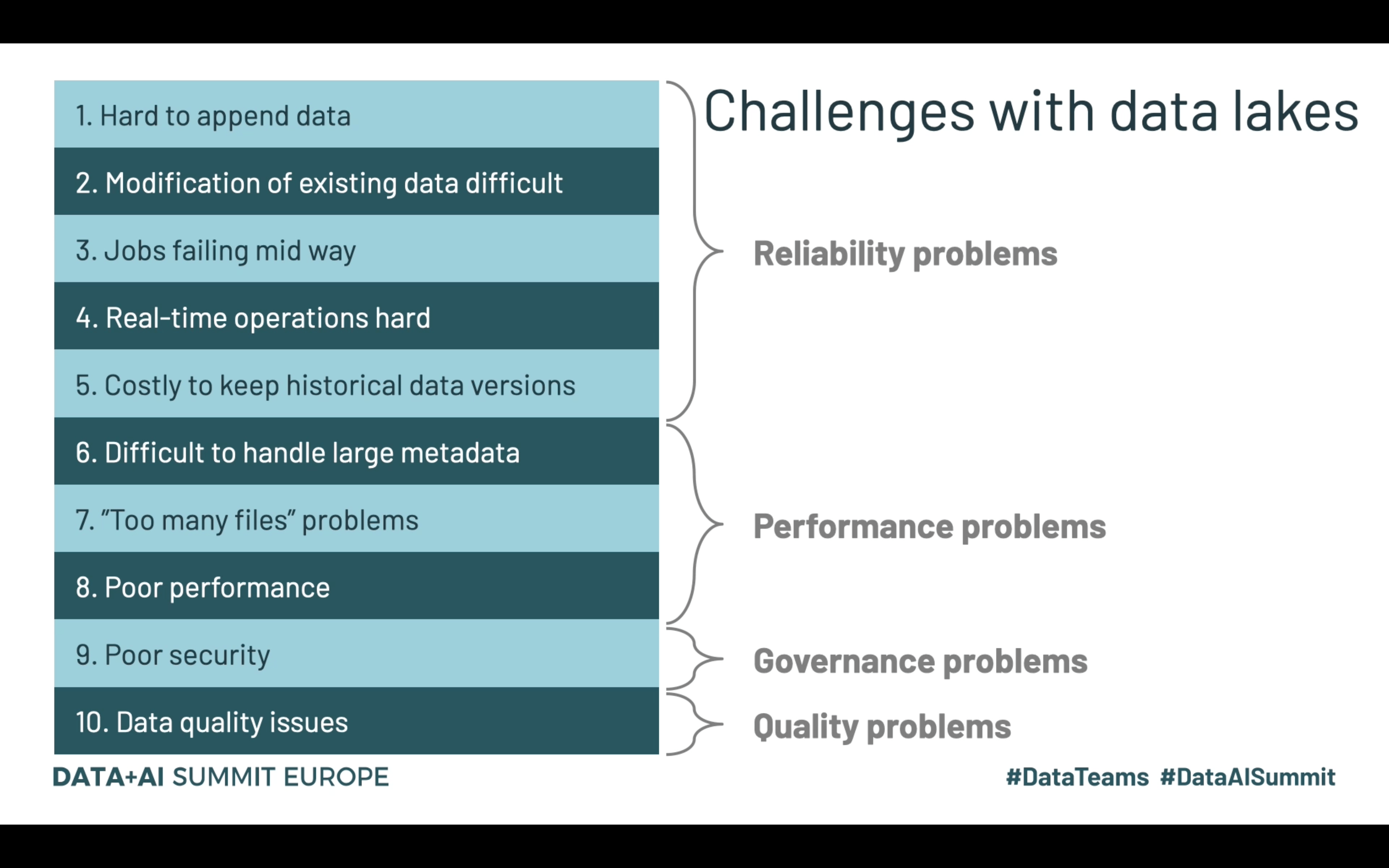
Passons maintenant au Lakehouse. Pour commencer, Databricks, la société qui évangélise beaucoup sur ce pattern, a identifié et partagé 10 problèmes liés au data lakes:
Pour résoudre ces problèmes, Databricks propose une solution, le Delta Lake ! Le souci de fiabilité peut être adressé avec les garanties ACID de traitement. La performance des requêtes peut être optimisée avec le mécanisme d’index. Pour la gouvernance, une approche classique de contrôle par table, colonne ou ligne avec ACL et RBAC. Et pour terminer, la qualité de données peut être garantie avec la fonctionnalité de schema management (ex. merge schema feature of Delta Lake) et avec l’aide d’un framework de data validation (ex. Great Expectations).
Lakehouse classifie aussi les données en 3 "âges", Bronze → Silver → Gold, où la partie la plus à gauche correspond aux données brutes et celle la plus à droite, aux données exposées aux clients. Le slide ci-dessous résume assez bien le concept:
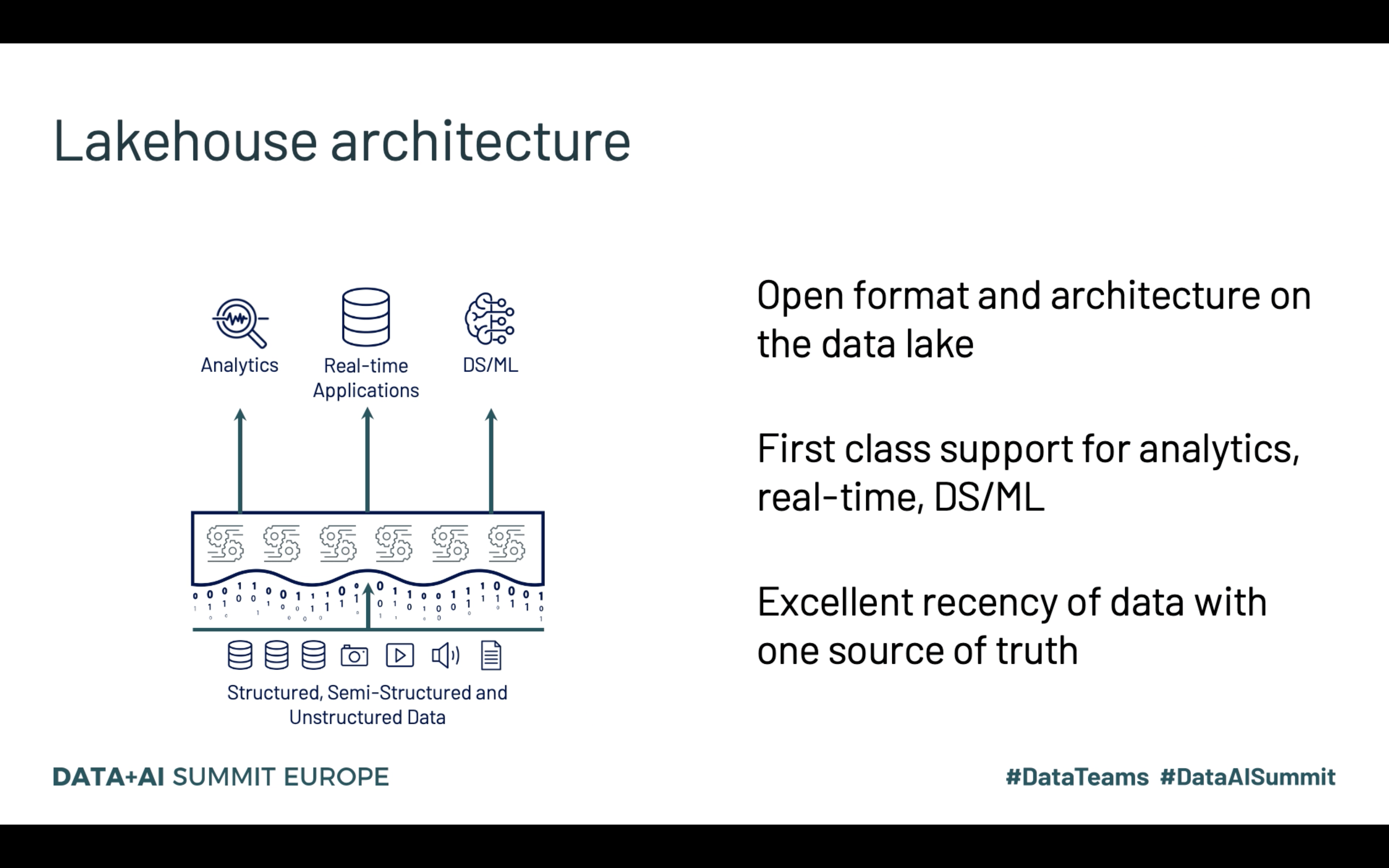
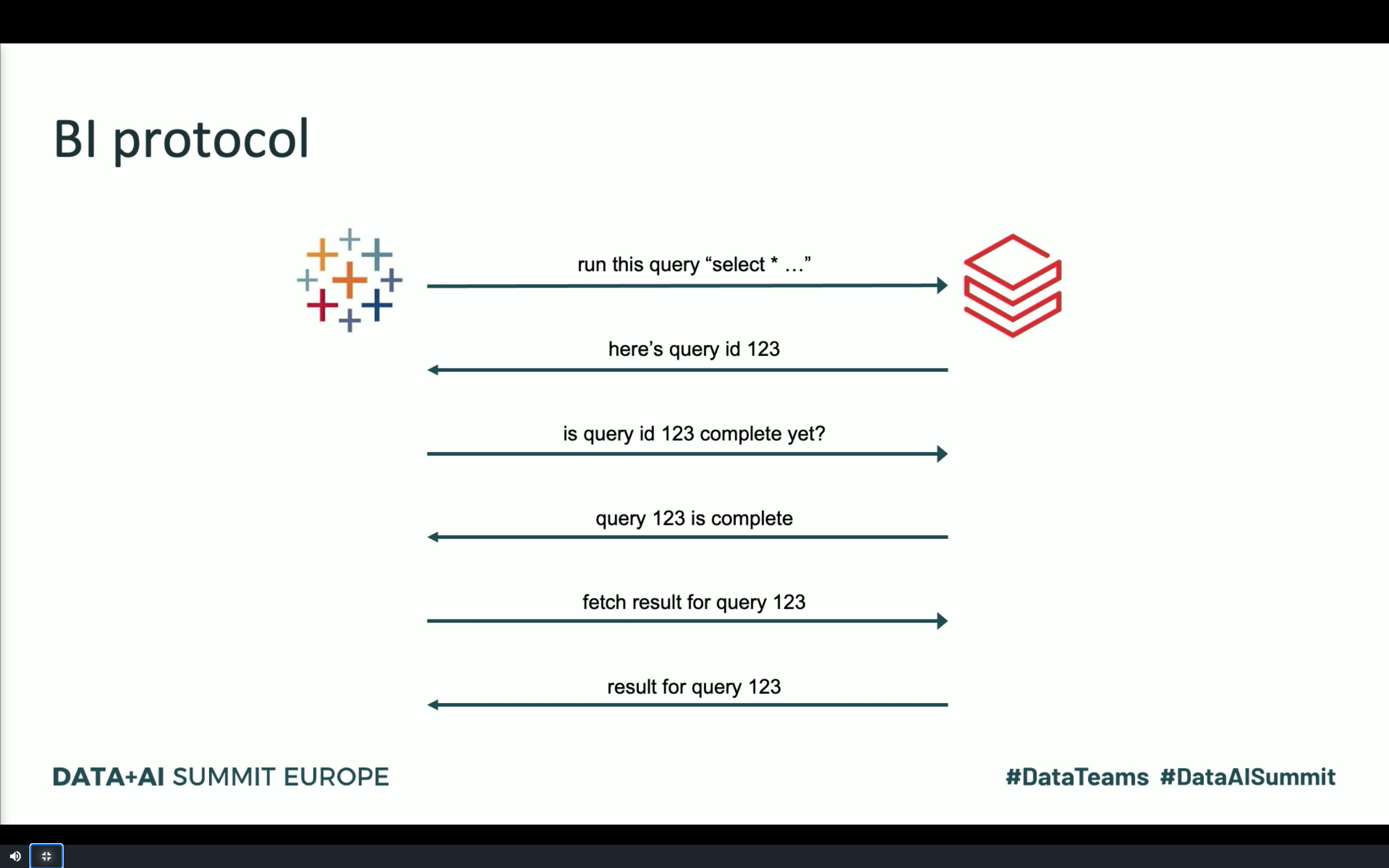
L’image est aussi une bonne occasion d’introduire un nouveau membre de la famille de service managé Databricks, SQL Analytics qui adresse la problématique de data visualization, jusque là possible uniquement via des notebooks. A l’occasion de sa présentation, Reynold Xin, un des fondateurs de Databricks et un des premiers contributeurs à Apache Spark, a expliqué quelques optimisations implémentées dans le protocole BI (voir l’image ci-dessous) et le moteur d’exécution:
Dès ses débuts Apache Spark était fortement associé à Scala. Cependant, le temps a changé bien des choses. Selon les analyses partagées par Databricks, le nombre des notebooks utilisant Scala a décru de 92% à 12% tandis que le nombre de notebooks Python a crû de 5% à 47% !
Malgré cela, PySpark a toujours un peu de retard par rapport au Scala Spark. Une des initiatives visant à réduire cet écart est le Projet Zen partagé lors de la keynote de mercredi par Reynold Xin. Le but ? Transformer PySpark en un projet plus Pythonique à travers des axes suivants:
Une présentation plus détaillée a été partagée par Hyukjin Kwon dans son talk intitulé “Project Zen: Improving Apache Spark for Python Users”.
Malgré le renommage de conférence de Spark+AI Summit au Data+AI Summit, elle a gardé son côté Spark-esque et les speakers ont partagé beaucoup de choses intéressantes liées à ce framework. Dans le premier talk de cette catégorie, “What is New with Apache Spark Performance Monitoring in Spark 3.0”, Luca Canali a présenté comment utiliser différents composants pour surveiller les applications Apache Spark. En dehors de Spark UI, on peut les surveiller avec le code à travers des fonctionnalités telles que Spark listeners, les métriques, en incluant celles des executors, et finalement les plugins. Si tu es en panne d’inspiration, tu peux jeter un coup d’oeil sur les repositories partagés par Luca, notamment https://github.com/cerndb/SparkPlugins, https://github.com/cerndb/spark-dashboard ou https://github.com/LucaCanali/sparkMeasure

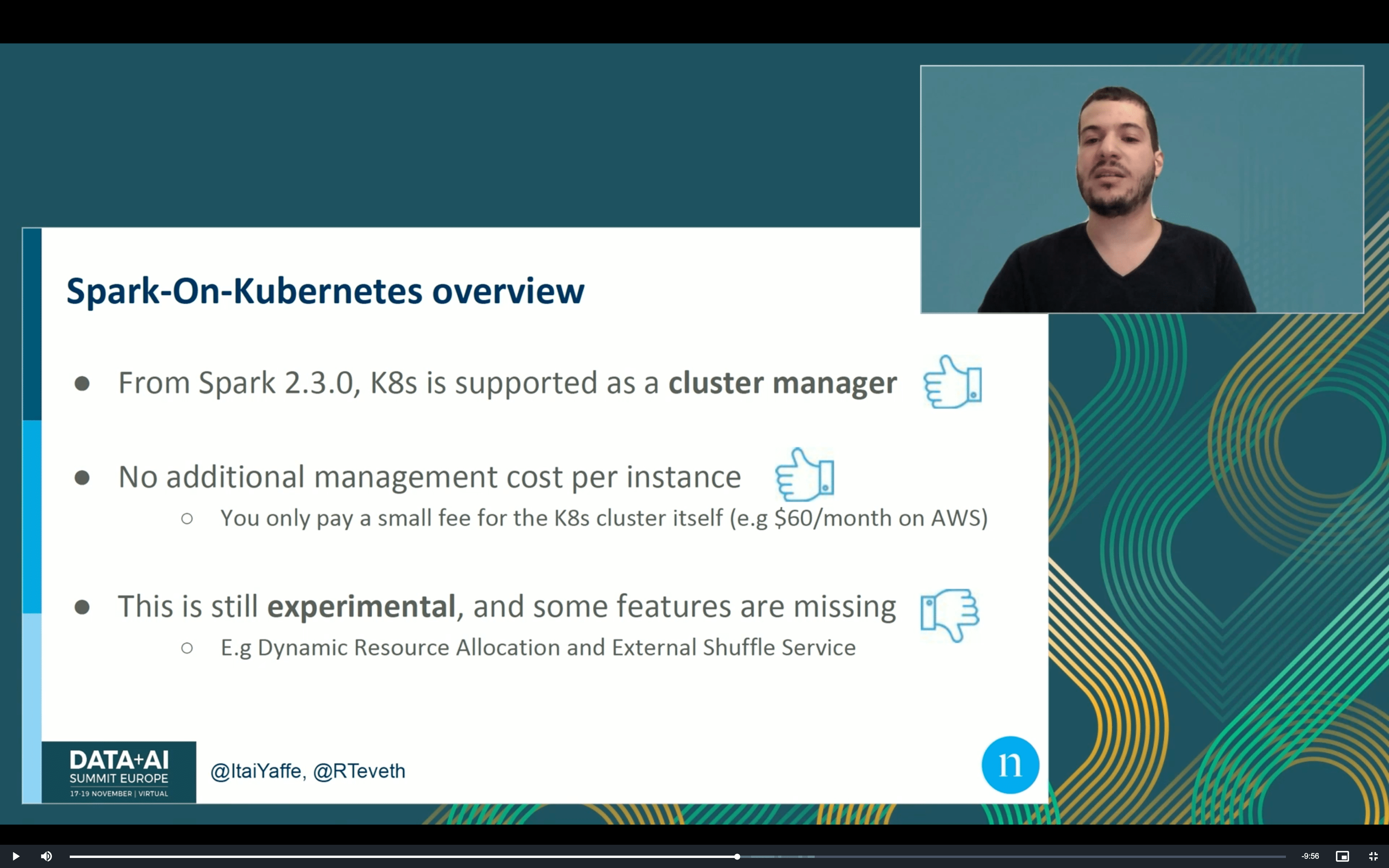
A part la partie de monitoring, on a aussi suivi la présentation d’Itai Yaffe et Roi Teveth. Dans leur talk intitulé “Migrating Airflow-based Apache Spark Jobs to Kubernetes - the Native Way”, ils ont partagé comment réduire la facture EMR de 30%, et en même temps fournir du challenge technique à l’équipe avec la migration des jobs Spark vers Kubernetes (EKS). Si tu cherches donc d’autres alternatives pour faire des économies en plus des Spot Instances ou Reserved Instance, n’hésite pas à regarder le talk et inclure l’EKS dans l’analyse!

Et pour terminer, on a assisté aux 2 talks de Facebook sur les JOINs in Apache Spark. Dans le premier, Suganthi Dewakar et Guanzhong Xu ont expliqué comment gérer le data skew dans les joins. A la fin de leur talk, “Skew Mitigation For Facebook PetabyteScale Joins”, ils ont partagé des solutions suivantes:

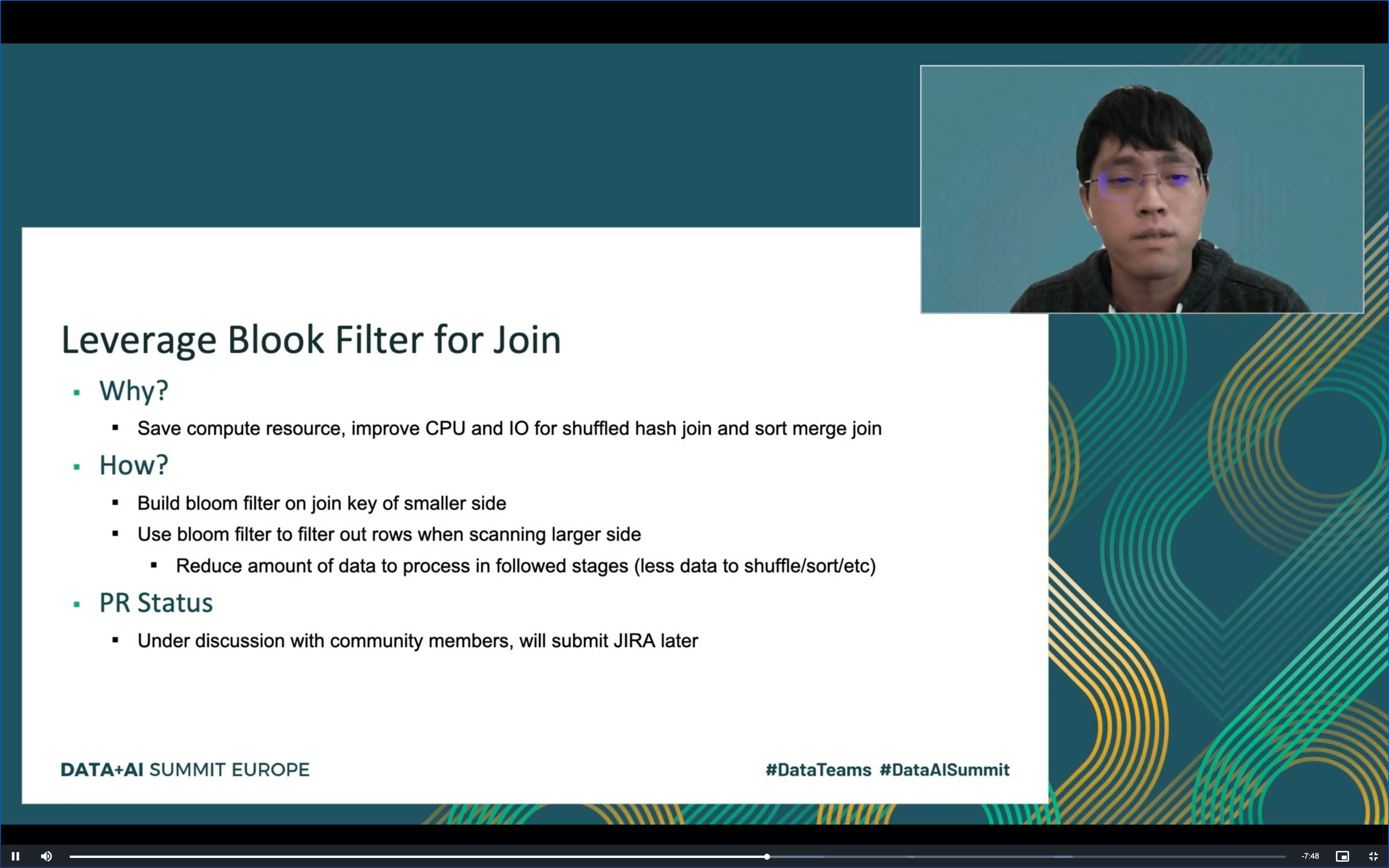
Dans le 2e talk, “Spark SQL Join Improvement at Facebook”, Cheng Su a présenté l’effort consacré à l’amélioration de l’opération de JOIN dans la version Open Source d’Apache Spark. Parmi les changements déjà prêts, une amélioration de la stratégie de shuffle join qui à partir de la version 3.1 du framework devrait utiliser le code généré à la volée, ce qui améliorerait les performances de 30% et minimiserait l’utilisation de CPU! Concernant les modifications “en cours”, l’utilisation de Bloom filter pour réduire la taille de données scannées dans le plus grand dataset impliqué dans le JOIN. Cette fonctionnalité est actuellement en cours de discussion avec les membres de la communauté.
Si tu attendais des détails techniques sur Delta Lake cette année, tu ne devrais pas être déçu! A part la présentation de Lakehouse, les ingénieurs de Databricks et membres de la communauté Open Source ont partagé quelques informations bien croquantes par rapport au Delta Lake.
Pour commencer, lors du Meetup tenu après les présentations de mercredi, Jacek Laskowski a partagé sa découverte à propos de l’exécution de l’opération de MERGE. Grâce à ce retour on peut apprendre que l’opération fait 2 passes sur les données source et pour l’optimiser, il faut explicitement cacher le Dataset. Cependant, cela peut évoluer suite à la discussion sur le mailing list de Delta Lake.
Les détails techniques sur l’opération de MERGE ont ensuite été précisés par Justin Breese, le solution architect de chez Databricks, dans le talk “Delta Lake: Optimizing Merge”. Pour la faire court, l’opération de MERGE se résumer à les 3 stages ci-dessous:

Dans son talk, Justin a aussi partagé quelques tips intéressants sur l’optimisation du MERGE, tels que:
Et le “Optimize merge…” n’était pas le seul talk donné par Justin. Il a aussi accompagné son collègue de chez Databricks, Nick Karpov, dans “Delta: Building Merge on Read”. L’idée du talk était de présenter 2 façons d’utiliser le MERGE. Le premier, appelé MERGE on write, est celui que tu as découvert plus haut, à l’écriture, où les données mergées sont écrites dans le job. Le 2e mode, appelé MERGE on read, propose une approche différente résumé sur le slide ci-dessous:
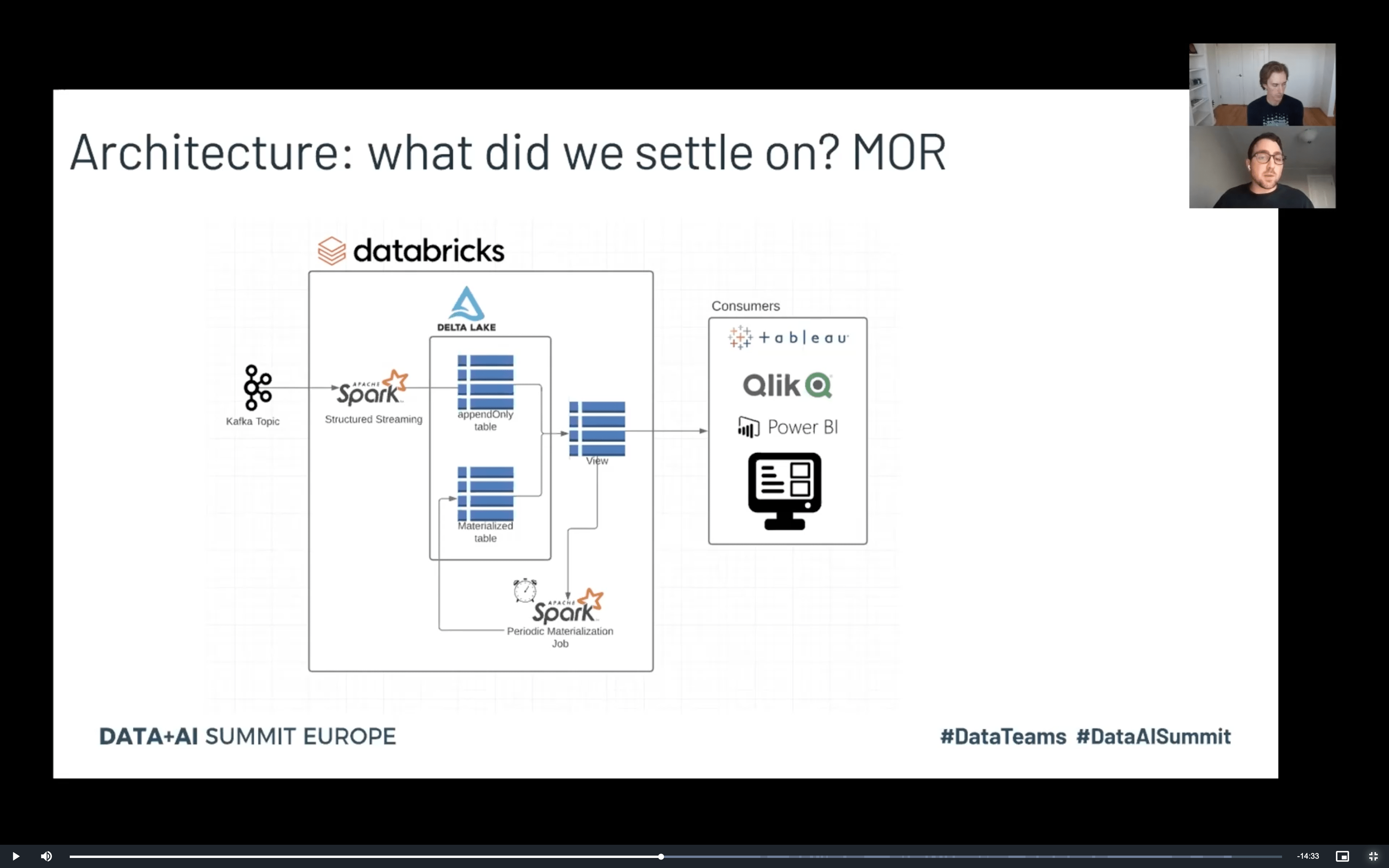
L’idée? Cela ressemble beaucoup à l’architecture Lambda. D’un côté les données fraîches sont ajoutées dans la table appendOnly. Elle est ensuite utilisée avec les données plus anciennes, stockées dans materialized view, et retournées à travers une vue commune (table view) représentant le join des 2 tables. Les données d’appendOnly sont progressivement déplacées dans materialized view. Pourquoi cette approche? Elle s’est avérée d’être beaucoup plus efficace pour un scénario où le dataset était complètement réécrit presque à chaque fois à cause des conditions présentées ci-dessous:

Cependant, MERGE n’est pas la seule opération disponible sur Delta Lake. Une autre a attiré notre attention. Il s’agit de l’option mergeSchema que Mate Gulyas et Shasidhar Eranti , les deux de Databricks, ont utilisé dans le talk “Designing and Implementing a Real-time Data Lake with Dynamically Changing Schema”. Si au quotidien tu travailles en streaming avec les données semi-structurées, n’hésite pas à voir comment ils ont utilisé cette option pour la gestion de schémas dans un environnement très dynamique. Les mots-clés: “mergeSchema” et “metadata store”.
Comme tu peux le constater, malgré son caractère virtuel, l’événement n’a rien perdu de sa magie! Et pour dire qu’on vient de présenter une petite partie liée uniquement au data engineering! Si tu veux en découvrir un peu plus, soit patient et vérifie de temps en temps si un nouveau playlist Data+AI Summit 2020 Europe n’est pas ajouté sur le channel YouTube de Databricks 🎬