In case you missed it, last week was held the first Data+AI Summit (formerly Spark+AI Summit) and we had a chance to participate. The talks will be published online but if you don’t want to wait, take a shortcut and learn our key insights!
TL;DR
Are you wondering why that title? It summarizes the major announcements from a data engineering perspective. Apache Spark will become more Pythonic thanks to the Project Zen initiative, and very probably, it will work on top of a lakehouse architecture. If you want to learn more about these and a few other topics, keep reading!
Lakehouse and data mesh were two main data architecture concepts shared in the Summit. Let’s start with the latter one that we discovered in Zalando’s “Data Mesh in Practice...” presentation. In the beginning, Max Schultze listed all the problems of centralized data management and surprisingly, none of them was related to a particular technology! The most important issues were:
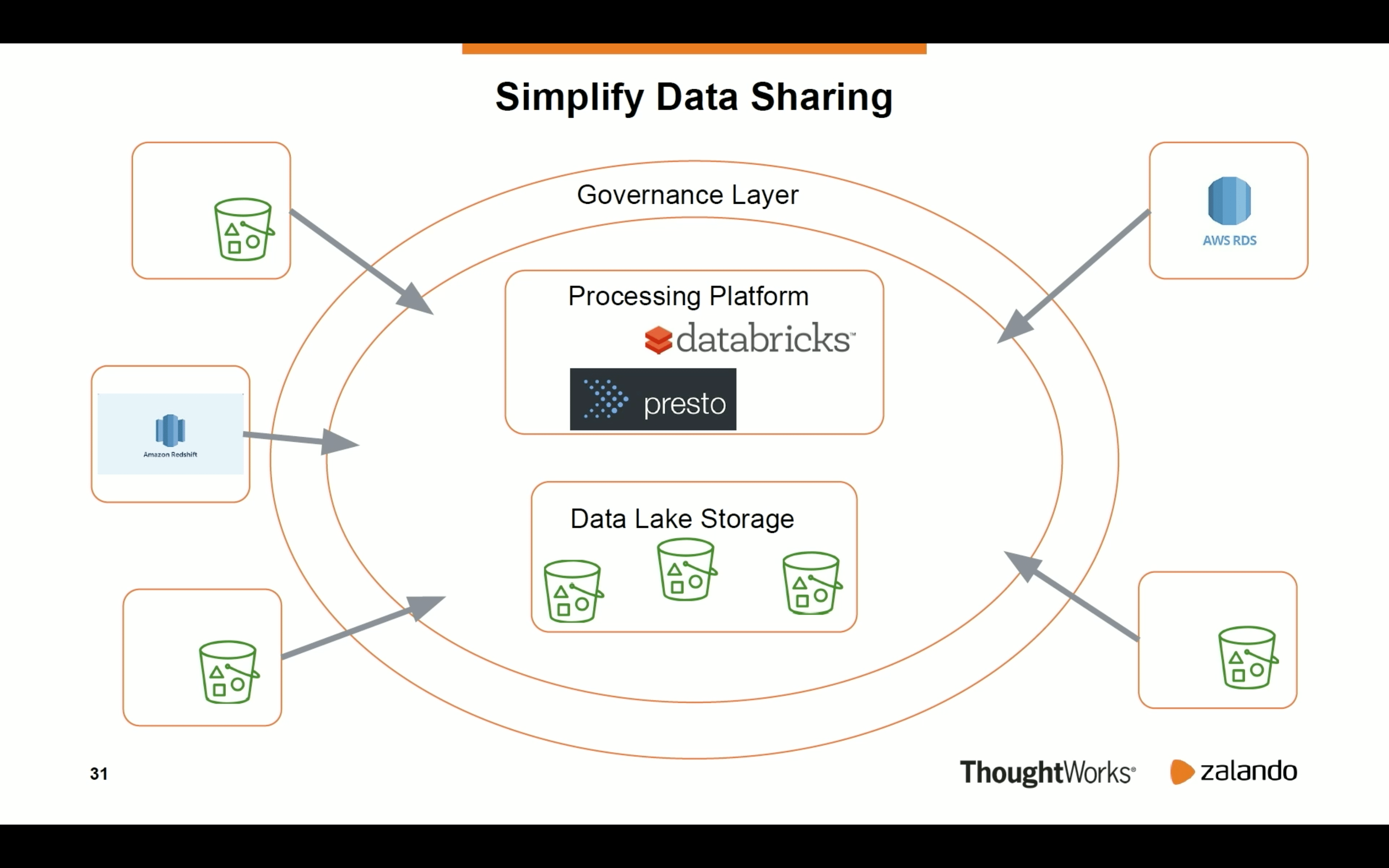
Later, Dr. Arif Wider from ThoughtWorks explained how the data mesh paradigm solves these problems and makes everybody from the below picture happy.

The first point solving the issue consists of changing the perception of the data. It’s not anymore a “dataset” but a product owned by a team. The team is there not only to maintain the technical pipeline but also to advertise and ensure its good usability.
The second solution is the Domain-Driven Architecture applied to the data. The team responsible for the dataset has the best expertise to answer customer’s questions and provide a product of good quality.
And finally, the Data Infrastructure as a Platform. The technical backbone for the data mesh has to be domain-agnostic, i.e., all teams should be able to use it seamlessly for batch/streaming data processing, ML models management or data analytics. “Seamlessly” is currently the keyword here because the goal is to avoid creating a new bottleneck in the organization.
Let’s move now to the lakehouse paradigm. Databricks, which is the company advocating the principle, identified 10 main problems of the data lake approach and summarized them pretty well in the following slide:
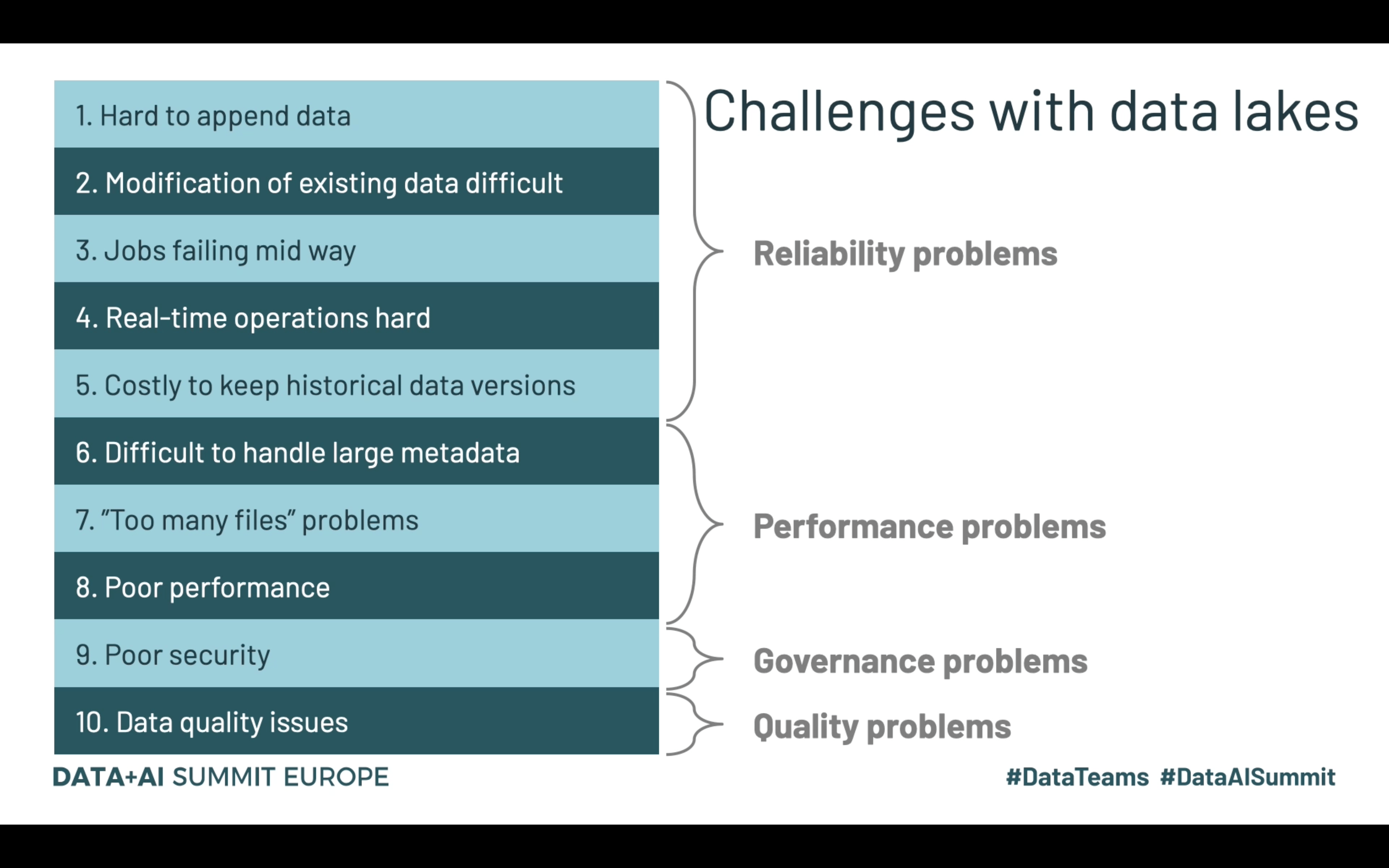
Ten issues and one solution present in a lot of the Summit talks, Delta Lake! Delta Lake solves the reliability problems with the ACID transactions support, optimizes the performance with the Z-Ordering and small files compaction, and integrates with existing ACLs and RBAC strategies at a table, row or column level for the governance. Finally, it solves data quality issues with the schema management (e.g. merge schema feature of Delta Lake) that can be extended with an additional data validation (e.g. Great Expectations).
In addition to that, this new paradigm uses the Bronze → Silver → Gold data classification, where the leftmost side stores the raw format of data and the rightmost exposes the dataset to the clients. The following picture summarizes the lakehouse concept pretty well:
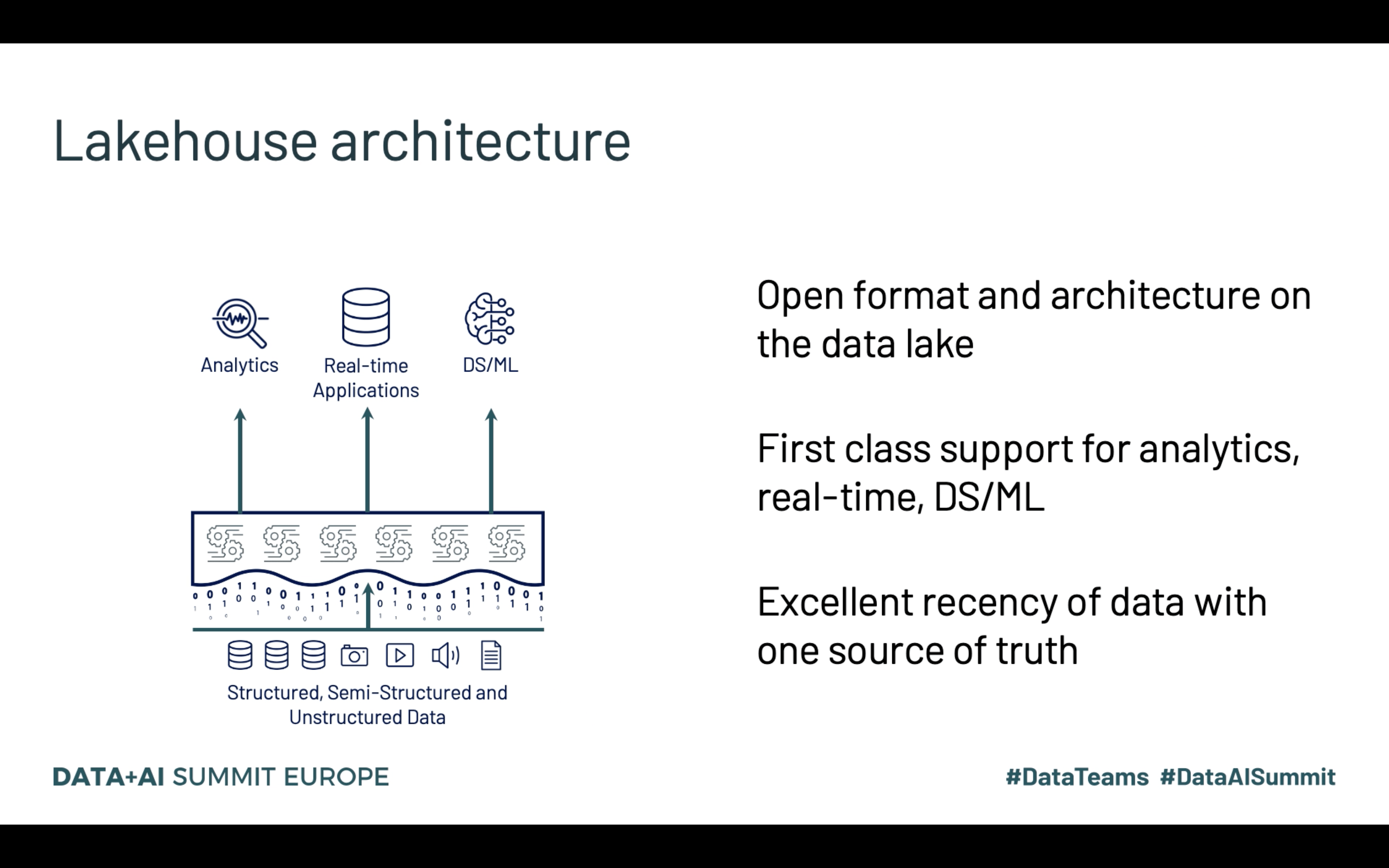
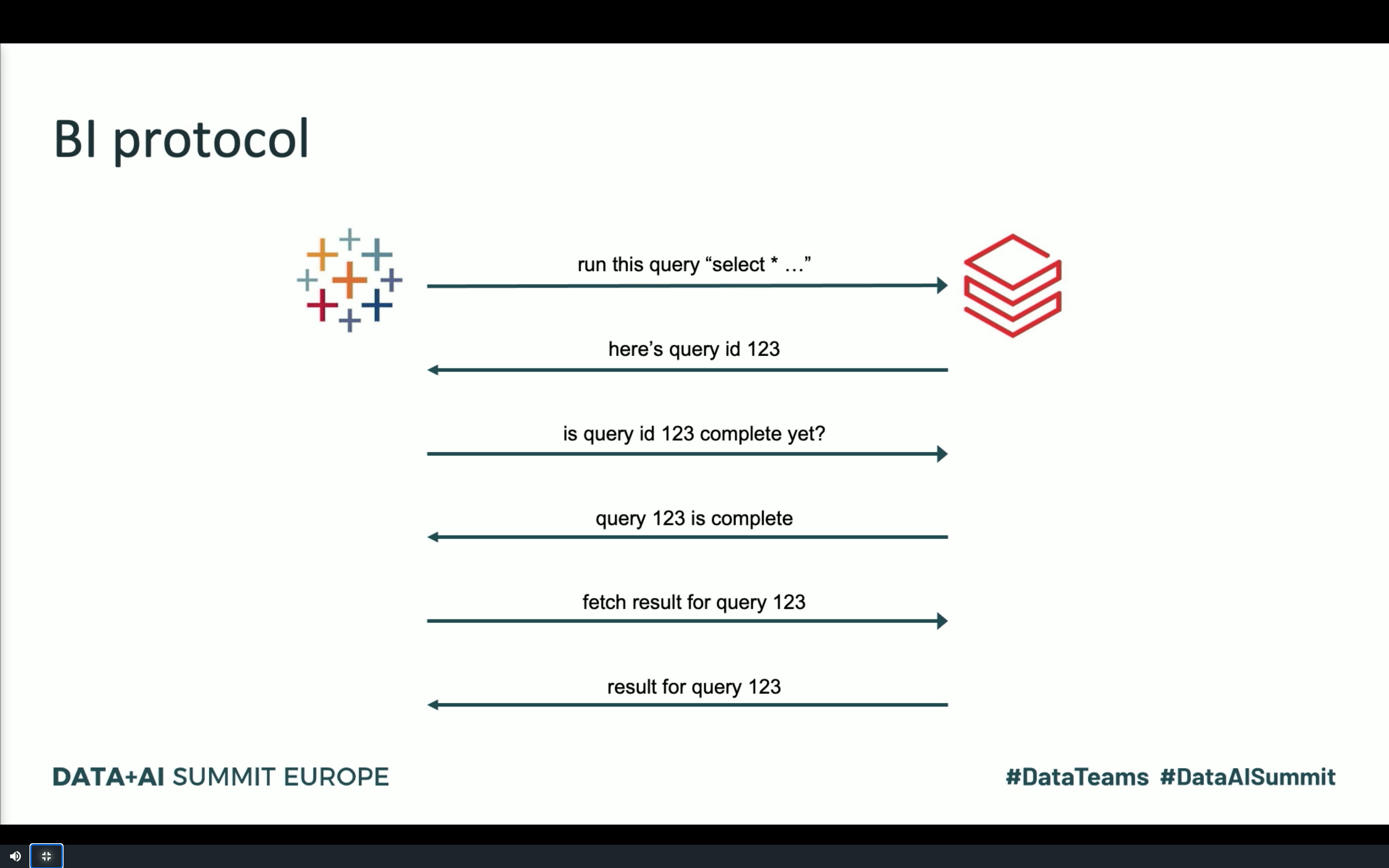
The picture above is also a great occasion to introduce the new component of Databricks service to handle data visualization scenarios, the SQL Analytics. And to make it possible Reynold Xin, one of Databricks co-founders and Apache Spark contributors, explained the implemented optimizations to the BI protocol used by the component, like:
From its very first days, the developers associated Apache Spark with Scala. But since then, a lot of years have passed, and the landscape has changed. In the last analysis shared by Databricks during the keynotes, Scala users’ proportion on top of Databricks platform decreased from 92% to 12%. The one for Python increased from 5% to 47%!
However, PySpark is not yet at the same maturity level as Scala Spark. And in the Wednesday keynotes Reynold Xin shared the Project Zen initiative, whose goal is to make PySpark more Pythonic. And this transformation passes through different axes:
The news was shared during the keynotes and extended in the “Project Zen: Improving Apache Spark for Python Users” by Hyukjin Kwon.
Despite the conference rebranding from Spark+AI Summit to Data+AI Summit, there were many insightful Apache Spark presentations! Everything started for us with “What is New with Apache Spark Performance Monitoring in Spark 3.0” where Luca Canali shared his tips for monitoring Apache Spark applications. Apart from the visual Spark UI, you can go a bit deeper and monitor your application with Spark listeners, metrics, including the executor ones or plugins. And if you look for some examples, you should find them in one of these repositories https://github.com/cerndb/SparkPlugins, https://github.com/cerndb/spark-dashboard or https://github.com/LucaCanali/sparkMeasure

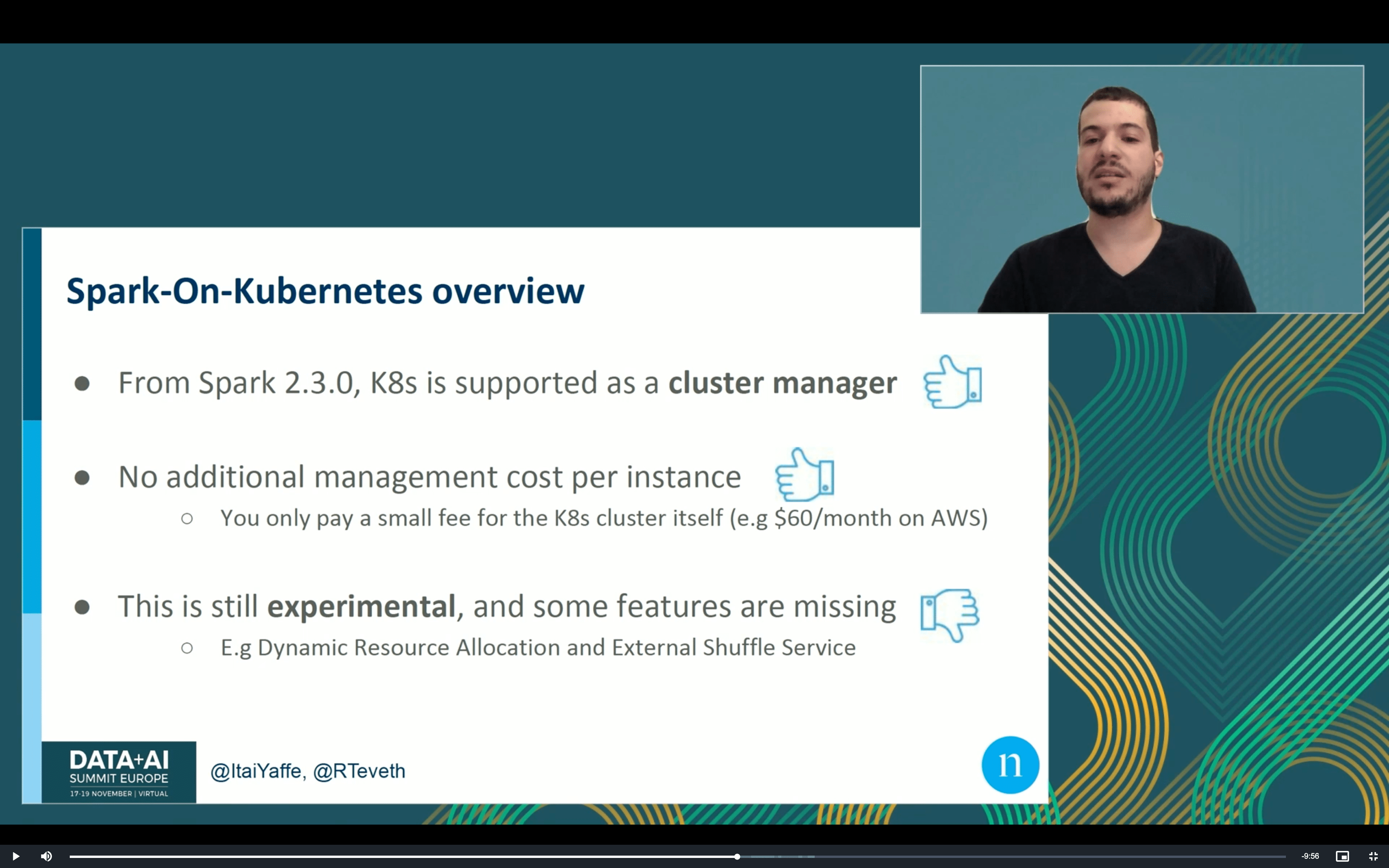
After the monitoring part, we took a look at the migration journey from EMR to Kubernetes (EKS) workflows on AWS, presented in “Migrating Airflow-based Apache Spark Jobs to Kubernetes - the Native Way” by Itai Yaffe and Roi Teveth. They succeeded in reducing the cost of running Apache Spark data processing jobs by 30%, only by migrating them from EMR to EKS! Of course, it didn’t come without cons, but if you are looking for pricing alternatives to Spot Instances or Reserved Instance, you can take the EKS into account.

In addition to them, we also appreciated the Facebook sharing on the data skew and joins optimizations in “Skew Mitigation For Facebook PetabyteScale Joins” by Suganthi Dewakar and Guanzhong Xu, and “Spark SQL Join Improvement at Facebook” by Cheng Su. In the first talk, you will discover the possible solutions to handle skewed joins, i.e. the joins where one key is way more popular than the others:

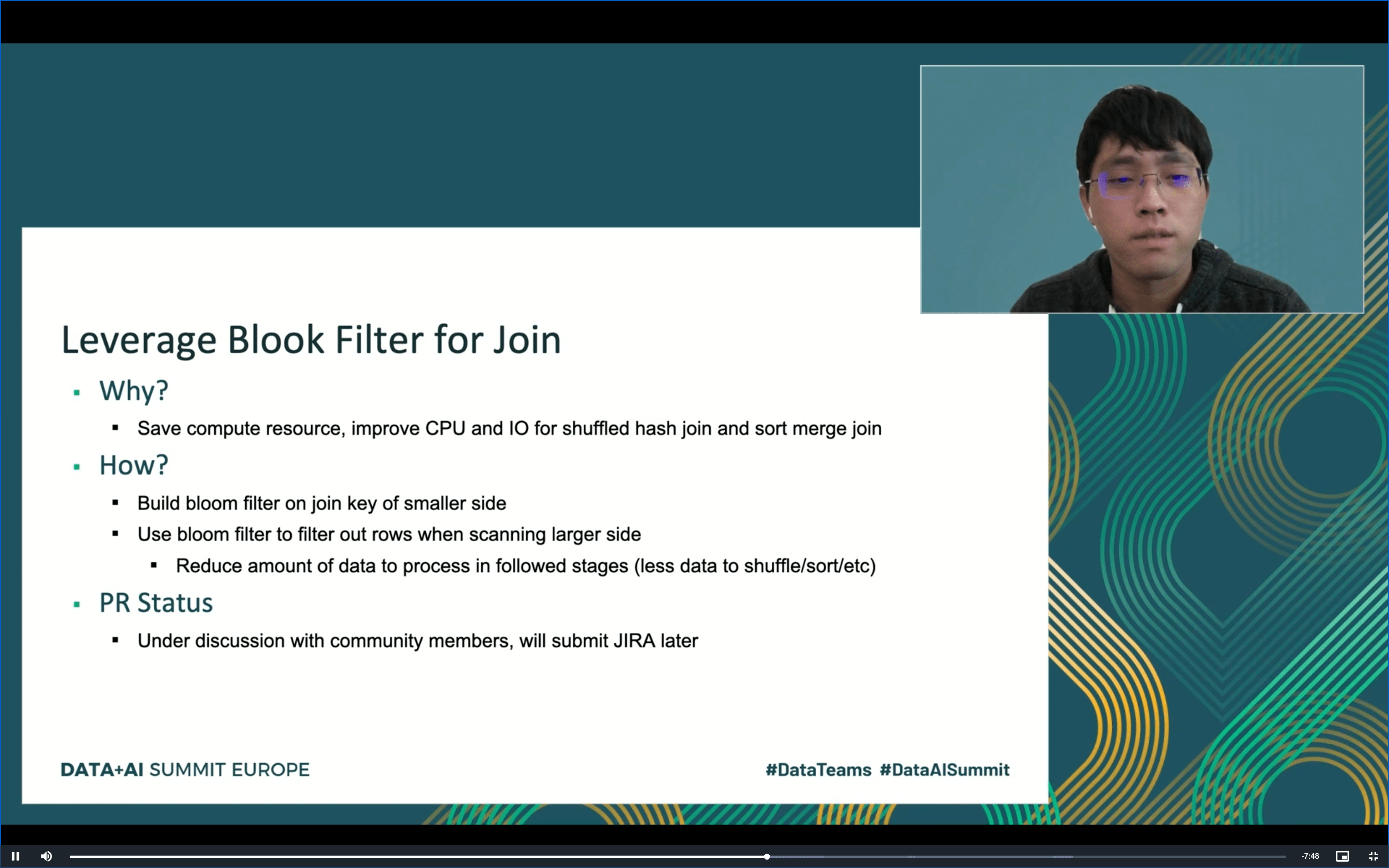
The second of the talks covered all changes made on Apache Spark 3 regarding the JOINs. Among the changes ready to be released, you will find the shuffle join based on the code generation that improves the performances by 30% and also uses less CPU! It’s planned to be integrated into Apache Spark 3.1. Another exciting proposal, not merged yet, is the use of Bloom filters to scan the larger side of the join and eliminate the not matching rows before performing the join physically. The technical details are still under discussion, but the feature itself looks promising.
If you looked for some technical details about Delta Lake this year, you won’t be deceived! Apart from Lakehouse architecture's presentation based on this new storage format, Databricks engineers and Open Source community members shared a few tasty tips about Delta Lake.
First, during Wednesday’s Meetup, Jacek Laskowski spotted a problem he encountered with the MERGE operation. From his feedback, we can discover that under-the-hood, the MERGE does 2 passes on the source data and that the Dataset has to be explicitly cached before invoking it! This behavior may change soon due to the mailing list exchange.
This technical detail was later developed by Justin Breese, the solution architect from Databricks, in his talk “Delta Lake: Optimizing Merge”. In a nutshell, the MERGE operation executes in these 3 steps:

Justin also shared a few interesting tips on how to optimize the MERGE:
And the “Optimize merge..." was not the single talk given by Justin. He was also a co-speaker of “Delta: Building Merge on Read” where together with Nick Karpov, they shared 2 different approaches for performing the MERGE operation. The first is called MERGE on write and consists of exposing the MERGED dataset to the downstream consumers. But it also has an alternative approach called MERGE on read, presented in the picture below:
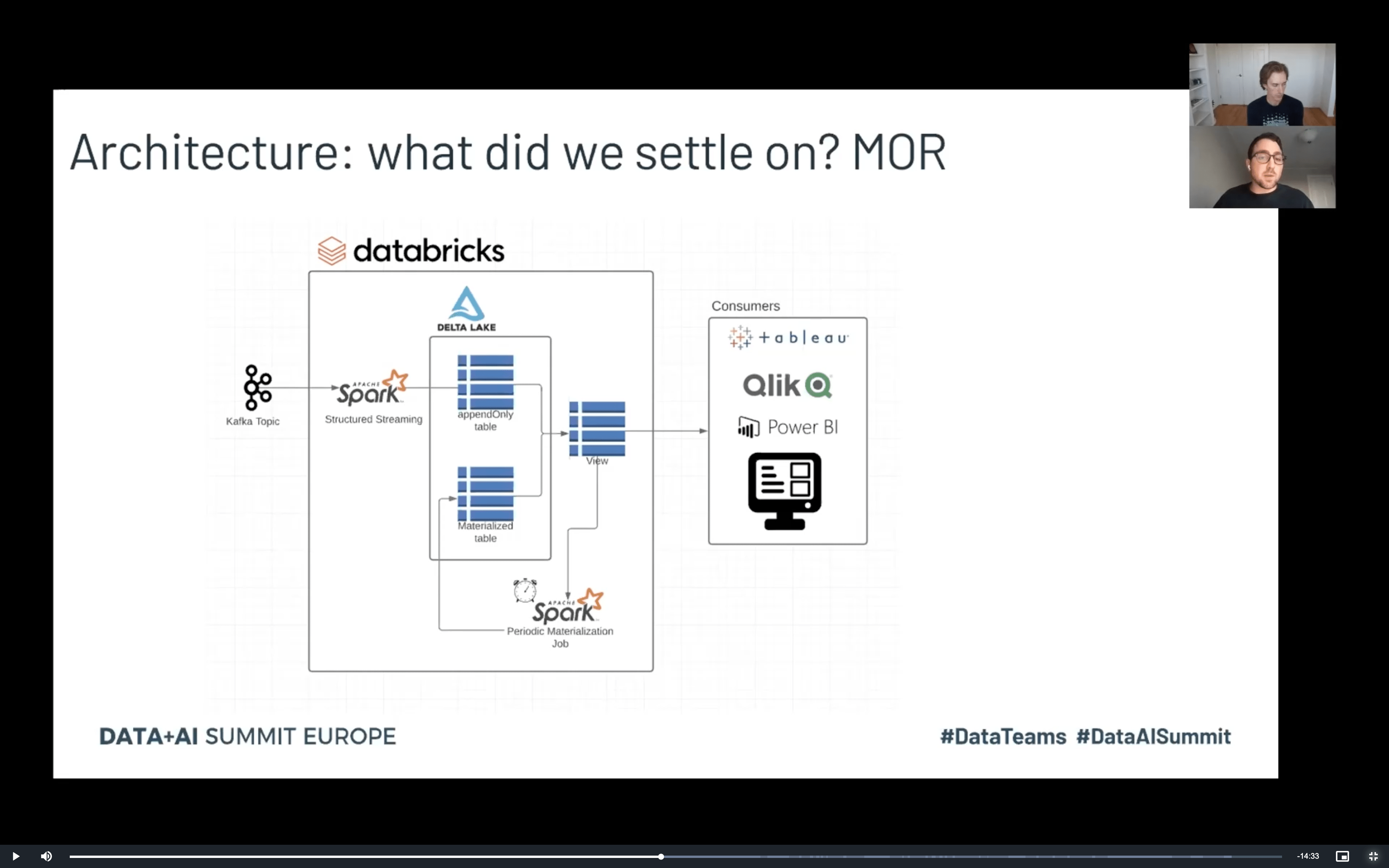
The idea is very similar to the Lambda architecture. The application adds the incoming data to the appendOnly table. But it’s not the exposition table. It’s only one of 2 tables composing the exposed dataset from the view table. And this view table is the result of the join operation between the most recent rows (appendOnly) and the ones already processed in the Materialized view table.
In addition to that, an Apache Spark job rebuilds this Materialized view table in the background by adding there the new rows from appendOnly table. As a result, the appendOnly table will only store the recently changed rows and the amount of joined data will be relatively small. Thanks to that, Apache Spark can use the broadcast join strategy to build the view table more efficiently. When to use this approach? The speakers presented some hints in this slide:

But the MERGE is not the single amazing Delta Lake feature. Another one is the mergeSchema option presented by Mate Gulyas and Shasidhar Eranti from Databricks in the “Designing and Implementing a Real-time Data Lake with Dynamically Changing Schema”. If you’re working with streaming semi-structured format and would like to know how to manage the schemas in this context, this talk should shed some light on it! The keywords are “mergeSchema” et “metadata store”.
As you can see, despite the fact of being held virtually this year, the event itself didn’t lose anything from its magic! And we covered here only the small part related to data engineering. If you want to discover more of the talks on your own, be patient and check whether a new Data+AI Summit 2020 Europe playlist didn't appear in Databricks YouTube channel 🎬