For three years now, NoSQL as a piece of technologies for Big Data has spread over the world and is challenging the centralized world of RDBMS. The space of distributed storages is yet not new and banks, online gaming platforms are using for several years technologies called "data grid" to address latencies and throughput issues. And to be completely franc, "Big Data" is not far from being the "new SOA”: a radical paradigm shift lost in the middle of commercial buzz words but that's another story...
What are the common points? The main differences?
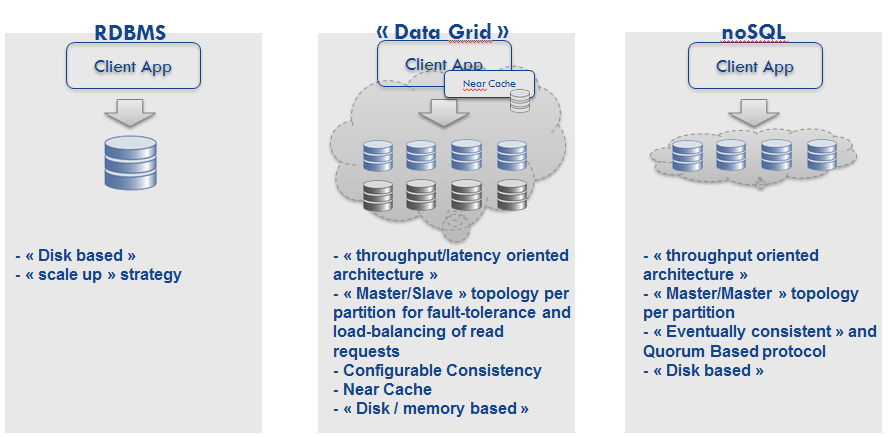
In the rest of the article, the term nosql will be used to talk about "transaction oriented" solutions like Cassandra, Riak, Voldemort, DynamoDB. On the other side, “Data Grid” will group solutions like Gigaspaces, Gemfire/SQLFire, Oracle Coherence.
No surprise...this is a distributed vision of the "database" and of the storage which enable to support more throughputs, more volume under, generally, cost constraints. The main idea resides in the fact that instead of using high-end server to store and query data, you use several "low-end" servers to store more data, increase the throughput and being able to scale-out, address elasticity issues. Indeed, this article reminds us the unit cost of a transaction is approx.. 4 times cheaper on a cluster of low-end server than on a high end server, (the main drawback of distributed storage will be the bandwidth consumption that stays expensive).
So in both cases, the distributed vision of the storage implies:
I was reading again this article of Vogels. As he stated (talking about GPU and CPU):
"… the most fundamental abstraction trade-off has always been latency versus throughput. These trade-offs have even impacted the way the lowest level building blocks in our computer architectures have been designed. Modern CPUs strongly favor lower latency of operations with clock cycles in the nanoseconds "
Even if it is quite difficult, should I say dangerous, to compare things, we can see the same trade-offs between NoSQL and data grid solutions. Data Grids come from a world where each milli-seconds (and now nano-seconds) count. These "data grids" have thus rapidly quit the disk and use the memory as main storage (even if it is configurable and we will discuss about that later).
On the other side, NoSQL solutions have been developed mainly for web-scale industries where the latency is not less important but let say around the second (because the end user is a human). In that case, you do not need to answer quicker and quicker, but you need to serve more and more requests.
If you look at the history of these solutions you will, at 10 000 foot high view, see that NoSQL solutions are mainly clones of the Dynamo model that have been developed at Amazon to store session and virtual caddies.
The choices that were made fitted the Amazon.com needs : response time predictability, infrastructure elasticity and scaling out, multi-datacenter resiliency, design for failure...
"Data Grids" come from more heterogeneous (and thus richer) environments. You need to use them to relieve the RDBMS, to keep data in your local JVM, to scale...You need to integrate them with the historical part of your Information System, so you need SQL-like integration, you need java, .Net, ruby client APIs...
In short, data grids are clearly more configurable and so more adaptable than the NoSQL solutions. Without being exhaustive, we can think to:
The funny thing is that both systems have the same constraints especially when it comes to ACID.
In fact, both solutions enables you to play with consistency and/or availability either using quorum based protocol or synchronous / asynchronous replication mechanisms. There is yet a subtility that can help data grids manage consistency (or at least conflict resolution): "data grid" use a master/slave topology per partition whereas nosql solutions use a master/master topology per partition.
Moreover, the "data grids" can offer you Atomicity and Transactions management BUT under certain constraints: typically, you will have to override the partitioning mechanism and ensure data colocation, you will not be able to rebalance the cluster while transactions are pending...These features come at a cost on the operability of the solution. This may not be blocking depending on the use cases but NoSQL solutions like Dynamo have made their choices: operability, elasticity with impacts on the dev side.
On that side, the match is not that simple. Data Grids offer much more complicated deployment options. You can use them in a classical client / server architecture: the data is stored on dedicated JVM whereas the business processes have their own dedicated JVM. In that case, the data grid is seen as a pure storage layer. That case is finally quite close of the NoSQL solutions.
What data grids offer (and not NoSQL solutions) is a peer-to-peer deployment where business processes and data are deployed in the same JVM. What changes is that the unit of deployment is the sum of the business process and you data. From the distributed storage point of view, there are no real advantages if you use your data grid as storage: data will be partitioned across the cluster, based on the key. This is yet quite different if your business cases necessitate writing and reading a lot of local data that is specific to your business case and must not be shared with the other business processes. In that case, you will benefit from this kind of deployment (gains in latency and bandwidth consumption).
The main drawback of data grids is that they need to know the java object (typically in the classpath) and in the best case, you can choose between default java serialization (Serializable or Externalizable) or the specific serialization. That can complicate upgrading the model, adding indexes...without downtime... On the opposite (and it solves the previous issues), NoSQL solutions work with a byte array: object versioning, serialization and unserialization must so be "manually" managed (even if these solutions often use protocols like Thrift, Avro…).
I am sure I forgot some points but in short that both systems are under the same constraints. The clear points is that "data grids", due to their own story are certainly more adaptable. That does not mean you must not look at NoSQL solutions because they can fit your requirements and these solutions work (see the works of Netflix with Cassandra) More generally, sometimes I am asking myself: why will we move to distributed storage (if we move to)? May be the following elements: