Les systèmes d'information sont au cœur de toute organisation, et assurent des fonctions critiques pour leur bon fonctionnement. Cependant, lorsque ces systèmes évoluent sans prendre en compte les aspects métiers, sans simplification de l'architecture et sans modernisation, ils peuvent devenir obsolètes, trop complexes et incapables de répondre aux besoins futurs. Face à cette problématique, les décideurs sont amenés à lancer des projets de ré-urbanisation de leur SI afin d’en reprendre le contrôle.

C'est dans ce type de contexte que Maxence Modelin, Delivery Manager, et Thomas Brien, Architecte, ont présenté à l’occasion de la Duck Conf 2023 une conférence intitulé “Retour d’expérience sur la ré-urbanisation d'un SI à travers une architecture évolutive. Personnellement, ayant eu l'opportunité d'assister à leur conférence et de travailler avec eux au quotidien, j'étais tout indiqué pour rédiger ce compte-rendu.
Au cours de leur présentation, ils ont détaillé le contexte de cette refonte, la démarche associée, l'importance de considérer le SI comme un produit, les principes directeurs qui les ont guidés tout au long du projet, ainsi que les contraintes à surmonter et les paradoxes à gérer. Dans cet article, nous allons explorer ces différents aspects pour comprendre comment leur expérience peut aider d'autres entreprises à relever les défis de la modernisation de leurs systèmes d'informations.
La ré-urbanisation de SI est toujours complexe, aucun SI ne se ressemble vraiment et il est donc important de comprendre le contexte en préambule. C’est cette première partie qu’ils ont choisis de nous présenter.

Et ce contexte se compose de deux SI principalement connectés par un flux. Le premier est un SI vieux de 30 ans, constitué d'un mainframe et d'un ensemble d'applications en Java pour faire évoluer le fonctionnel. Le second est une application Java de 10 ans et un ensemble d'applications greffées autour.
Dans les deux cas, les évolutions se sont faites par agrégation et duplication de données. Les deux systèmes sont très hétérogènes dans leur conception. En termes de volume, on est sur une trentaine d'applications pour environ 5 millions de lignes de code qui traitent 60 millions de dossiers pour 5 000 utilisateurs réguliers à 60 millions d'utilisateurs occasionnels.
Les enjeux de cette ré-urbanisation sont multiples :
sortir du mainframe, car il coûte cher à maintenir, à faire évoluer et n’est pas une technologie très tournée vers le futur
sortir de l'application Java monolithique, car elle est endettée et difficile à faire évoluer en vue des nouveaux besoins fonctionnels qui arrivent rapidement
aider à la gestion et l’urbanisation du SI, car il est aujourd’hui très hétérogène, avec des pratiques très différentes en termes de développement, d'automatisation, de déploiement et de run.
Pour répondre à ces enjeux, il a été décidé de remplacer les systèmes actuels via un nouveau SI. Ce projet, étalé sur 4 ans, s'est ensuite déroulé de manière relativement classique : cadrage sur plusieurs mois pour comprendre l'existant et construire la cible, une première phase pour déminer les sujets les plus risqués, puis une phase de réalisation avec une dizaine d'équipes organisées en SAFe.
La vision du SI pour Thomas et Maxence, c’est un ensemble d’applications et d’outils, utilisés au quotidien à la fois par des utilisateurs métiers et par des utilisateurs techniques, qui eux vont accéder à des services offerts pour gérer l’infra, déployer de nouvelles applis, mettre en prod quotidiennement et s’assurer du run.
Dit autrement, pour eux, un SI peut être vu comme un ensemble de produits à destination de différentes populations d’utilisateurs. C’est naturellement qu’ils en sont arrivés à avoir une stratégie produit pour le SI.
Là où le sujet se complique c’est que dans leur cas (et très certainement dans beaucoup de cas), la priorisation des besoins métiers se fait au détriment des capacités du SI comme la maintenabilité à long terme. Afin de garder un équilibre pérenne, ils ont mis en place des pratiques pour que le SI ne devienne pas la “dernière roue du carrosse” via les points clés suivants.
Selon eux, la première étape pour assurer une gestion efficace du SI est d’avoir un product manager dédié capable de prendre en compte l'ensemble du SI sans clivage entre les métiers. Ce dernier travaille en étroite collaboration avec les product managers des produits métiers pour animer la roadmap et la vision.
Le product manager SI doit être en mesure d'arbitrer les éléments techniques et stratégiques pour le SI afin d'inclure les évolutions au fil de l'eau et de les intercaler avec les événements à venir. Cette approche permet de prioriser les sujets liés au SI, tout en garantissant la pérennité de la vision.
Pour assurer la propagation et la conservation de la vision, ils recommandent de s’appuyer sur un ensemble de personnes sur le terrain. Parmi ces personnes, on trouve notamment :
- les architectes transverses qui instaurent les pratiques et les standards généraux du programme de ré-urbanisation
- les techleads transverses qui participent à la réalisation de chantiers transverses
- les techleads d'équipe qui veillent à propager la vision au sein des équipes
En plus de ces personnes, ils recommandent l'utilisation d'un ensemble d'outils et de pratiques notamment les communautés de pratiques, la documentation évolutive, les Active Decision Records (ADR), le pair programming et les cadrages en amont des réalisation d’un nouveau produit ou d’une fonctionnalité importante du SI.
Le temps alloué pour l’amélioration du SI est restreint, l’optimiser autant que possible pour faciliter la généralisation de pratique et d’outils est donc un point clé. Thomas et Maxence recommandent de travailler dans un cadre restreint en termes de choix technologiques.
Ils recommandent également le partage des pratiques entre les équipes afin d'harmoniser et de profiter des avancées que les autres ont faites. Thomas donne l'exemple du sujet de l'observabilité, où une équipe a pu partager des snippets de code Java/Spring mis en place sur une application afin de ressortir des metrics, que toutes les autres équipes ont pu facilement réutiliser.
En adoptant une approche produit, en nommant un product manager dédié au SI, en désignant un ensemble de personnes pour oeuvrer à la propagation et à la conservation de la vision du SI, en travaillant dans un cadre restreint et en partageant les bonnes pratiques entre les équipes, on s’assure que la pérennisation et l’optimisation du SI est facilitée.

Le précédent programme de modernisation des 2 SI avait duré plusieurs années avant de se terminer par un échec. En cause, l'incapacité de reprendre les données et d’avoir les mêmes résultats au niveau des traitements que le système actuel. L’un des objectifs clés de ce nouveau programme de modernisation était donc d’éviter autant que possible de tomber dans les mêmes erreurs. Pour cela, le mot d’ordre était de pouvoir partir en prod au plus tôt.
Les conférenciers nous ont présenté dans cette troisième partie, pour chaque typologie de produit, leur approche pour y arriver.
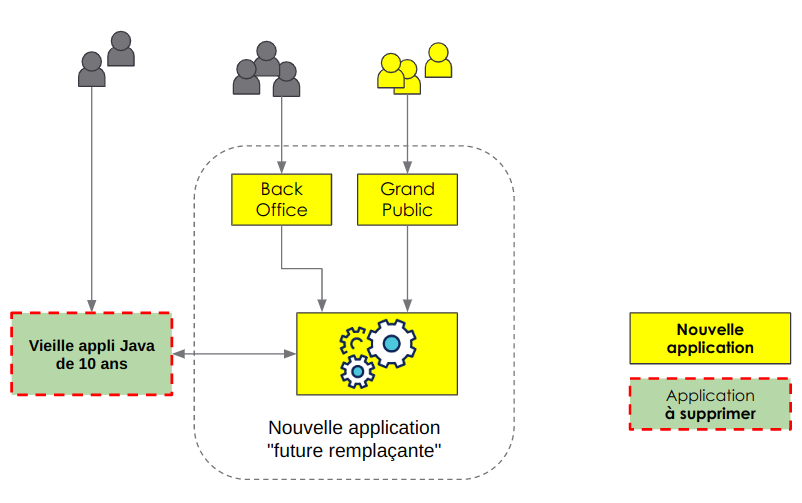
La contrainte principale de la plateforme de booking est de pouvoir mettre en place des nouveaux besoins fonctionnels rapidement. Afin de répondre à cette contrainte, la stratégie choisie a été de mettre en place une nouvelle application qui allait implémenter les fonctionnalités pour une nouvelle population d’utilisateurs en fournissant un effort minimum pour la synchronisation de données avec l’existant.
Dès la mise en production, ils ont fait en sorte que cette application naissante intègre petit à petit les fonctionnalités de l’ancien système. Une fois que ce système est devenu autonome, l’ancienne application est décomissionné tout en ayant pu bénéficier des retours de la production sur plusieurs années pour les nouvelles briques.
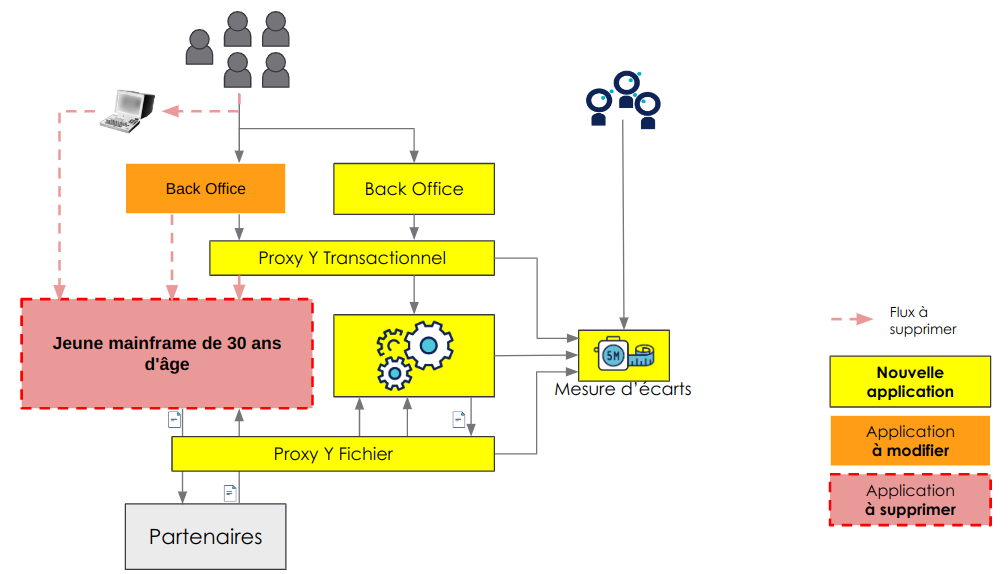
La plateforme de suivi de dossier client, quant à elle, a pour impératif de garantir un scope fonctionnel et une production de résultats ISO avec le mainframe. Pour y parvenir, la stratégie adoptée a été celle du double run. Il s'agit "d'empaqueter" le cœur du SI, à la fois le mainframe et le nouveau système, afin de pouvoir router les flux sur deux systèmes en parallèle et comparer leurs écarts. Nos intervenants appellent double-run la période durant laquelle les 2 systèmes (l’ancien et le nouveau) tournent en parallèle (le temps de finir de construire le nouveau système et de le valider sur la totalité du périmètre fonctionnel).
La première étape de ce processus a été la réalisation d'un POC sur la reprise de données et les règles métiers essentielles.
Lorsqu'ils évoquent le POC, les intervenants mettent en avant qu'ils ont cherché à :
redécouvrir la base de données du mainframe difficile d'accès et à valider qu'ils sont capables de reprendre et fiabiliser les données ;
valider qu'ils arrivent à avoir le même résultat lors de l'application des règles métier (dans le nouveau système) ;
se confronter aux conditions de production, avec le niveau d'exigence attendu en termes de qualité, d'automatisation et d'exploitabilité ;
disposer de contrats d'interface pour la cible.
La notion de POC est utilisée ici car ils ont cherché à valider le cœur du SI sous tous les angles, qu’ils soient métiers sur les règles de gestions ou techniques sur la capacité à automatiser et déployer via les outils déjà en place, afin de s'assurer de la viabilité du reste du programme. Le résultat attendu est une partie du SI qu'on peut mettre en production. On est donc loin de la notion de validation d'un concept via un code jetable.
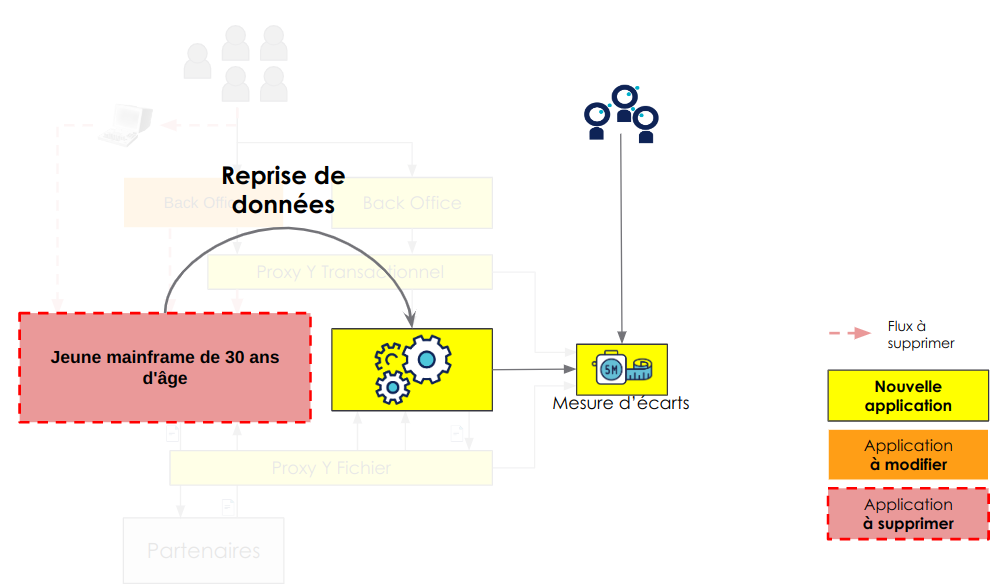
POC de repise de de donnée et des règles métiers
Une fois arrivés à ce stade, ils ont pu se rassurer sur la capacité du nouveau système à reproduire des résultats identiques aux anciens systèmes à partir d'un même état initial. Mais le but du double run est d'aller plus loin, en faisant tourner les deux systèmes dans le temps et en vérifiant continuellement leur synchronisation lorsqu'ils ingèrent les mêmes flux.
Là encore, deux approches ont été adoptées, l'une pour les utilisateurs et l'autre pour les partenaires.
Pour les utilisateurs, ils ont mis en place une façade qui capture les flux provenant des clients utilisateurs afin de les rediriger vers le nouveau système en les traduisant, tout en maintenant le flux vers l'ancien système.
Cependant, il peut y avoir des cas où cela est plus compliqué, et Thomas nous donne l’exemple des écrans du mainframe : ces écrans présentent l’inconvénient d’avoir un flux difficile à intercepter. Par ailleurs les réimplémenter c’est aussi devoir réimplémenter les règles métiers associer, former et migrer les utilisateurs sur le nouveau système. Étant donnés les efforts représentés, cette solution n’est pas la solution à privilégier si la complexité métier implémentée dans les écrans est trop importante.
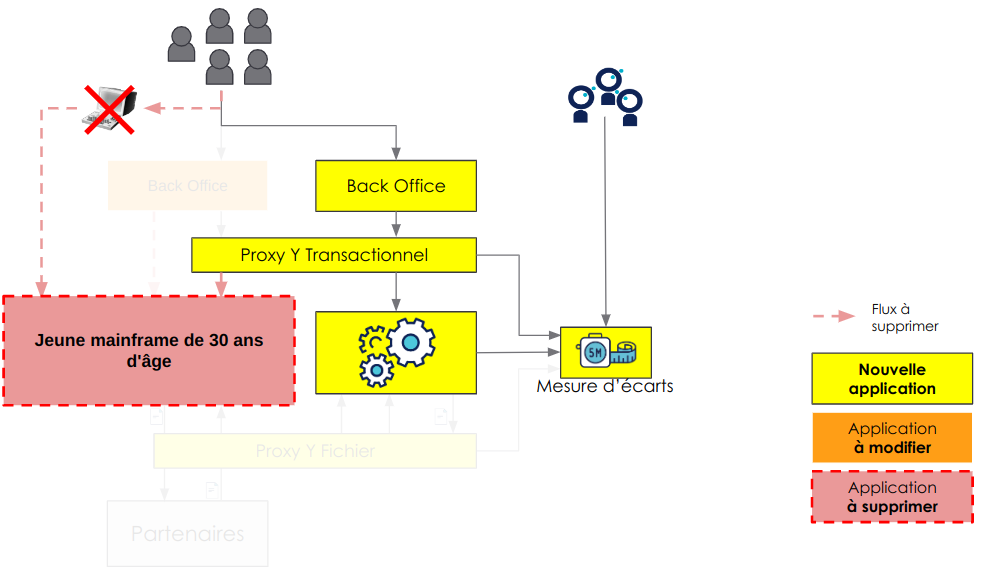
Mise en place du double run pour les utilisateurs
Dans le cadre des partenaires, la communication se fait sous forme de fichier d’un point de vue entrant et sortant.
Comme pour les utilisateurs, une brique d’intermédiation route le trafic entre le mainframe et son remplaçant et la comparaison du résultat se fait sur les fichiers sortants. L’action de décommissionnement du mainframe se fait via la bascule de transmission des fichiers de sortie par le nouveau système en garantissant une interface inchangée avec les partenaires.
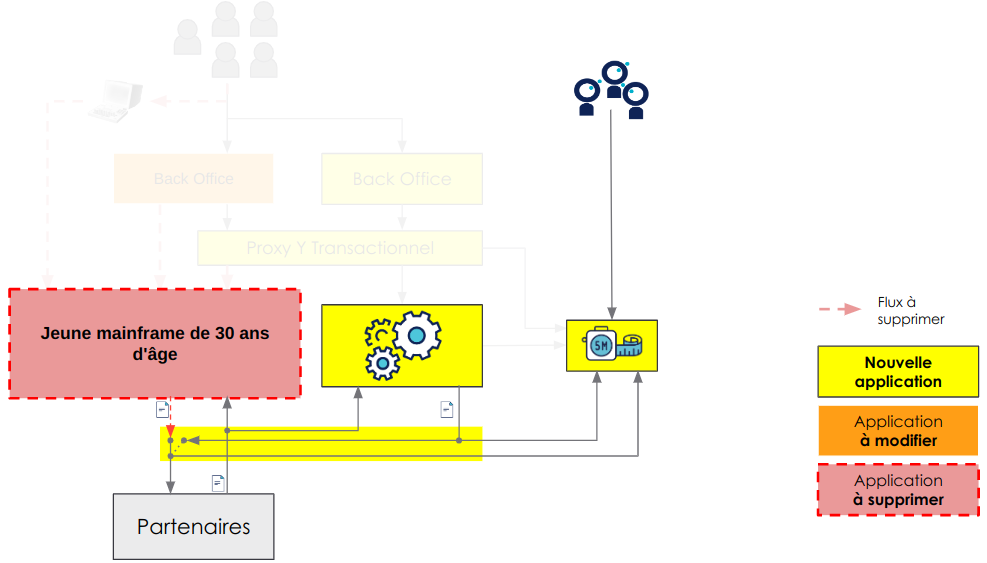
Mise en place du double run pour les partenaires
Enfin, en point structurants, il est à noter que les évolutions métier sur le mainframe ont été gelé afin d’éviter de courir après la synchronisation des deux systèmes et que des développements spécifiques ont été effectués afin de comparer les deux systèmes.
Ces contraintes ont été acceptées car le principal enjeu ici était une refonte ISO fonctionnelle qui reproduit exactement les mêmes résultats que le précédent système.
Avoir des principes directeurs pour nous guider le temps du programme est crucial. Mais face à la réalité du terrain, on peut se retrouver face à des situations qui vont à l’encontre de ces principes.
“Faire des compromis et savoir vivre avec les paradoxes, c’est la réalité de notre métier“
Thomas Brien et Maxence Modeline, Duck Conf 2023
C’est durant la dernière partie de leur conférence qu’ils ont choisi de nous partager des situations en conflit avec leurs principes et leurs convictions et comment ils ont réussi à les surmonter, les accepter ou faire évoluer leurs stratégies.
On parle d’avoir une approche Agile et Lean, en allant chercher à faire uniquement ce qui est nécessaire pour une mise en place, de manière itérative et aller chercher rapidement du feedback pour s’assurer de la viabilité. Sauf que là, on est sur un programme sur 4 ans, contenant lui-même de multiples projets
Maxence nous met donc en avant le travail d’équilibriste à faire entre faire ce qu’il faut immédiatement et faire du stock sur une durée beaucoup plus longue car on a la vision de ce qu’il faut faire, toute la difficulté de cette démarche étant de ne pas gaspiller l’effort sur des éléments inutiles à terme.

“On est toujours en train de gérer entre faire immédiatement ce qu’il faut et en même temps se projeter”
La loi de Conway est bien connue des architectes. Aussi, quand nos conférenciers en étape de cadrage ont vu que l’ancien SI était maintenu par deux ensembles d’équipes distinctes qui communiquaient peu entre eux, ils n’ont pas été surpris par l'hétérogénéité de pratique et d’outils.
Face à ça, ils en sont donc arrivés à regrouper les équipes sous un même train agile (au sens SAFe : https://scaledagileframework.com/agile-release-train/).
A mesure que les équipes au sein du programme de modernisation ont continué à grossir, la frontière entre les deux anciens SI a commencé à réapparaître - dû au fait que ces SI avaient des périmètres d’application distincts qui ont perduré avec les nouvelles applications. Les équipes de chacun de ces deux périmètres demandaient logiquement à pouvoir s’isoler, notamment pour ne pas perdre de temps lors des rituels SAFe (PI planning, démonstrations, inspect, etc.), alors que la stratégie du programme était justement de les unifier. La séparation a finalement eu lieu, mais les équipes transverses redoublent d’effort pour minimiser les divergences et renforcer la communication entre les 2 groupes ; comme le dit Maxence “Même si on sait qu’on va avoir des problèmes, on est obligé d’y aller”.
J’en suis autant convaincu que Thomas, plus on est proche d’un problème, mieux on sait y réagir. Ce que cela traduit dans le cadre d’un programme, c’est que les bonnes idées pour les résoudre vont émerger localement.
Le but est donc d’arriver à faire émerger les solutions en local et de les généraliser pour qu’elles deviennent globales. Ils nous donnent alors deux exemples, un succès et un échec pour eux :
La mise en place d’un composant intermédiaire pour répondre aux problèmes de surspécialisation des APIs, qui est devenu un standard qui n’a jamais été généralisé du fait des retours mitigés à long terme et de perte de connaissance
Le changement de la stack de provisionnement d’infrastructure pour une stack plus simple et standardisée qui s’est généralisée petit à petit à tout le programme
Il s’agira donc d’arriver à négocier le virage pour passer de local à global sans pour autant le forcer si les retours terrains sont finalement mitigés.
Réurbaniser, c’est aussi faire plus simple. Mais pour ça, on doit modifier l’existant, ajouter des composants, les faire cohabiter ensemble et on passe alors par une étape intermédiaire où le SI est bien plus complexe que ce qu’il n’était à l’initial.
Thomas conclut cette partie en mettant en avant que cette transition est nécessaire et que le but reste bien à la fin de supprimer cette complexité pour répondre aux enjeux initiaux.

“La stratégie de double-run permet de diminuer le risque, mais elle n’est pas gratuite”
On arrive à la fin de la conférence et voici les points qu’ils nous proposent de retenir :
Ayez une vision à long terme sur votre SI, sur qui sont vos utilisateurs cible et sur le service que vous voulez leur apporter
Ayez un Product Manager de SI avec une vision métier, technique et financière dont le but est d’améliorer le SI à chaque nouveau projet
Evitez l’effet tunnel et allez en prod le plus vite possible
Embarquez les sachants sur le système historique pour éviter les écueils sur le nouveau système et vous aider sur les interconnections lors de la phase d’hybridation
Faites primer le métier sur la technique, et travaillez avec lui pour arriver à mettre en place des évolutions plus stratégiques pour le SI