Dans l'article « Bêta perpétuelle », nous avons vu que les géants du Web améliorent leur produit de façon permanente. Mais comment arrivent-ils à livrer fréquemment ces améliorations alors que dans certaines DSI, la moindre modification peut prendre plusieurs semaines à être déployée en production ?
La plupart du temps, ils ont instauré un processus de déploiement continu (continuous deployment), selon deux modalités possibles :
Evidemment, la mise en place de ce pattern demande certains pré-requis…
Mais pourquoi déployer en continu ?
La motivation première du déploiement continu est d’améliorer le Time To Market, mais aussi de se donner autant d’occasions de tester des hypothèses, de les valider et au final d’améliorer son produit.
Effectivement, imaginons une équipe qui met en production tous les 1er du mois (ce qui est déjà une fréquence élevée pour beaucoup de DSI) :
J’ai une idée le 1er.
Avec un peu de chance, les développeurs peuvent l’implémenter pendant les trente jours qui restent.
On met en production comme prévu dans le plan de release mensuel le 1er du mois suivant.
Pendant un mois, on collecte les données pour finalement s’apercevoir que l’on doit améliorer l’idée de base…
Il faut alors attendre un nouveau mois pour mettre en œuvre cette future amélioration, soit trois mois au final, pour avoir la fonctionnalité stabilisée.
Dans cet exemple, ce qui nous empêche d’aller vite, ce n’est pas le développement, mais bien le processus de livraison, et le plan de release.
Déployer en continu permet donc d’améliorer le Time To Market, mais aussi d’accélérer les cycles d’amélioration du produit.
On peut ainsi améliorer le cycle bien connu du Lean Startup :
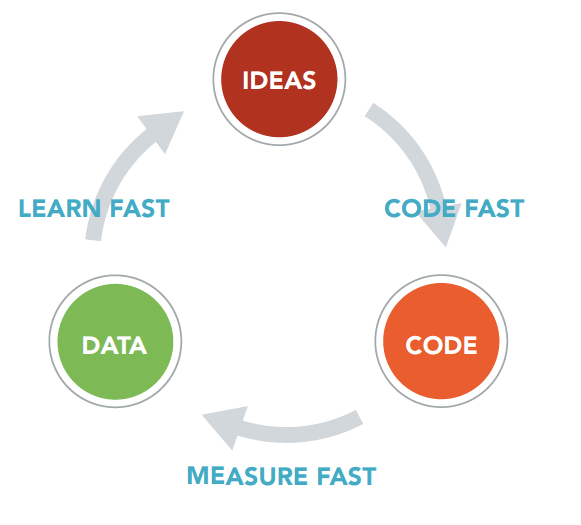
Figure 1.
On entend souvent parler indifféremment de « Continuous Delivery » et « Continuous Deployment », pour éviter les erreurs d’interprétation, voici notre définition.
À chaque commit (ou par intervalle de temps), le code est :
Attention, il ne s’agit pas ici de dire que le Continuous Delivery et la Continuous Integration ne servent à rien. Bien au contraire, ce sont des étapes essentielles, et le Continuous Deployment n’est que l’extension naturelle du Continuous Delivery qui est lui-même l’extension naturelle de la Continuous Integration.
L'une des objections courantes lorsque l’on parle de Continuous Deployment est le manque de qualité : ne risquons-nous pas de livrer quelque chose d’incorrect, de livrer des bugs ?
Tout comme avec la Continuous Integration, on ne bénéficiera pleinement du Continuous Deployment que si l’on est capable d’être sûr du code à tout moment. Ceci implique d’avoir une couverture de tests (unitaires, d’intégration, de performances, etc.) très complète. Outre les tests unitaires, inévitables, on trouvera donc toute une série de tests automatisés comme :
L’automatisation des tests peut sembler coûteuse, mais quand l’objectif est de les exécuter plusieurs fois par jour (IMVU lance 1 million de tests par jour), le retour sur investissement est très rapidement positif. Certains, comme Etsy, n’hésitent pas à créer et à partager des outils pour coller aux mieux à leur besoin d’automatisation et de test[1].
De plus, lorsqu’on déploie tous les jours, la taille des déploiements est évidemment plus petite que lorsqu’on déploie tous les mois. Et sur des petits déploiements, le TTR (T_ime To Repair_ ou temps de réparation) est plus petit, comme on peut le voir sur la figure 2.
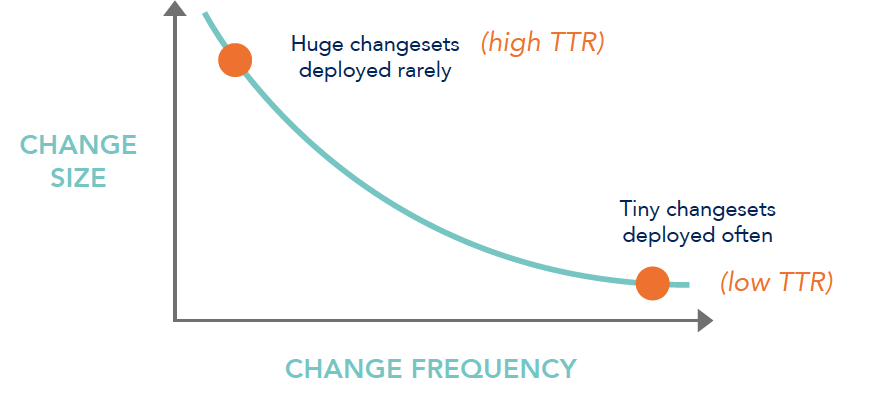
Figure 2 . Source : http://www.slideshare.net/jallspaw/ops-metametrics-the-currency-you-pay-for-change-4608108, modifiée.
Etsy donne une bonne illustration de la confiance que l’on peut avoir dans le code et dans la capacité de corriger rapidement. En effet, ils ne prévoient pas de mécanismes de rollbacks : « We don’t roll back code, we fix it » (« on ne fait pas de retour arrière sur le code, on le corrige »). Selon un de leur employé la plus longue durée de réparation d’un bug critique fut de quatre minutes.
Les gros changements créent de gros problèmes, des petits changements créent de petits problèmes.
De nombreux géants du Web ont implémenté avec succès le Continuous Deployment, voici quelques chiffres des plus représentatifs
Tout d’abord, estimez (ou mieux, mesurez !) le temps nécessaire à vous et votre équipe pour livrer une simple ligne de code jusqu’en production, en respectant le processus standard évidemment.
La mise en place d’une « Usine de Développement » est la première étape du Continuous Deployment.
Afin de pouvoir aller plus loin, il est essentiel de s’assurer que l’ensemble des tests réalisés couvrent une large part de l’application. Si certains acteurs n’hésitent pas à coder leur propres frameworks de tests (Netflix a initié le projet « Chaos Monkey » qui éteint des serveurs aléatoirement), on peut se baser sur des frameworks existants allant de JUnit à Gatling en passant par Selenium. Afin de réduire le temps d’exécution des tests, IMVU répartit ses tests sur pas moins de 30 machines. D’autres utilisent les services Cloud comme AWS afin d’instancier des environnements de test à la volée et paralléliser l’exécution des tests.
Une fois que l’usine de développement produit des artefacts suffisamment testés, celle-ci peut être étendue afin de livrer ces artefacts à l’équipe qui va déployer l’application sur les différents environnements. À cette étape, on est déjà dans le Continuous Delivery.
Maintenant, cette dernière équipe peut enrichir l’usine afin d’y inclure les tâches de déploiement. Ceci nécessite évidemment que différentes tâches soient automatisées, comme la configuration des environnements, le déploiement des artefacts constituant l’application, la migration des schémas de bases de données et bien d’autres encore. Attention aux scripts de déploiement ! Il s’agit de code, et comme tout code, il doit répondre aux standards de qualité (utilisation d’un SCM, tests, etc.).
Une solution plus radicale mais intéressante est de forcer le rythme de livraison, par exemple toutes les semaines, afin de provoquer les changements.
Lorsque l’on met en place le Continuous Deployment, plusieurs patterns sont inévitablement tirés et notamment :
Retrouver toutes les pratiques des Géants du Web sur le site dédié (www.geantsduweb.com) : pdf de l'ouvrage à télécharger, vidéo et compte-rendu de la présentation "Décrypter les secrets des Géants du Web"
• Chuck Rossi, Ship early and ship twice as often, 3 août 2012.
• Ross Harmess, Flipping out, Flickr Developer Blog, 2 décembre 2009 .
• Chad Dickerson, How does Etsy manage development and operations?, 04 février 2011.
• Timothy Fitz, Continuous Deployment at IMVU: Doing the impossible fifty times a day, 10 février 2009.
• Jez Humble, Four Principles of Low-Risk Software Releases, 16 février 2012.
• Fred Wilson, Continuous Deployment, 12 février 2011.