L’écosystème Kafka peut s’avérer difficile à appréhender dans beaucoup de projets de delivery. KsqlDB offre une abstraction intéressante en permettant de consommer des flux de données en SQL, comme sur une base de données classique.
Cette simplification permet d’initier rapidement une nouvelle application sans connaissance préalable de la plateforme.
Cet article parcourt les fonctionnalités des différents outils de l’écosystème Kafka, détaille KsqlDB et tente de répondre aux questions suivantes :
Les articles intitulés Le B-A-BA Kafka et Kafka streams sont disponibles sur le blog Octo et décrivent plus en détails les bases de cet écosystème.
Kafka est principalement utilisé comme “broker” de messages, ce qui signifie qu’il facilite le passage de messages entre les services émetteurs et récepteurs, donnant la capacité de communiquer de manière asynchrone entre le client et le serveur. Considéré par ses concepteurs comme un système optimisé d’écriture, il est conçu pour des objectifs de performance et de résilience.
Kafka Streams est une bibliothèque cliente qui traite les données entrant dans Kafka à destination des développeurs.
Un “Stream” ou “flux de données en continu” est une séquence non finie d’éléments. Un traitement de type “Stream” analyse un flux à la volée et traite les données au fur et à mesure de leur disponibilité.
Le temps est un concept central dans le traitement de flux. Chaque élément est associé à un ou plusieurs horodatages (timestamp) qui peuvent indiquer quand l’élément a été intégré, la validité de son contenu ou s’il est devenu indisponible pour le traitement.
Les bases de données doivent stocker les données avant que ces dernières ne soient disponibles. Si des données sont ajoutées, elles ne seront visibles que lors d’une prochaine requête (requête dite “ponctuelle”). La notion de flux n’est pas possible dans ce paradigme fortement séquentiel.
KsqlDb effectue des transformations (agrégations et jointures) en continu des données qui entrent dans Kafka. Le résultat d’une requête n’aura donc théoriquement pas de fin. Celui-ci est une évolution de KSQL, un moteur SQL permettant d’abstraire la consommation de données en flux émanant de Kafka stream. Il fournit une interface SQL interactive, facile à utiliser et puissante pour le traitement de flux de données Kafka. Il est également élastique et tolérant aux pannes.
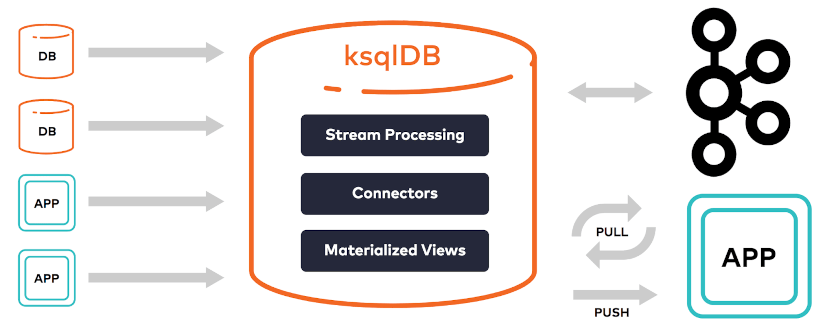
KSQL permet les actions suivantes :
KSQLDB apporte en plus le support de :
Avant l'arrivée de Ksql, l’utilisation du connecteur natif ou l’API Kafka stream restait la seule possibilité de consommer les flux de Kafka, sans la possibilité d'utiliser des requêtes SQL et les jointures devaient être explicitement écrites.
Cet exemple montre comment en Java Spring il est possible de consommer ces topics :
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Bean
public NewTopic topic() {
return TopicBuilder.name("topic1")
.partitions(10)
.replicas(1)
.build();
}
@KafkaListener(id = "myId", topics = "topic1")
public void listen(String in) {
System.out.println(in);
}
}
Puis avec KafkaStream :
final Serde<String> stringSerde = Serdes.String();
final Serde<Long> longSerde = Serdes.Long();
KStream<String, String> textLines = builder.stream("streams-plaintext-input", Consumed.with(stringSerde, stringSerde));
KTable<String, Long> wordCounts = textLines
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, value) -> value)
.count();
wordCounts.toStream().to("streams-wordcount-output", Produced.with(stringSerde, longSerde));
Les premières versions de Ksql ne proposaient pas encore de connecteur. La seule façon d'interagir depuis une application était au travers d’une API REST de type POST , le point d’entrée “/query” et la requête SQL dans le corps.
curl -X POST \
http://localhost:8088/query \
-H 'content-type: application/vnd.ksql.v1+json; charset=utf-8' \
-d '{"ksql":"SELECT * FROM MY_TABLE;", "streamsProperties": {
"ksql.streams.auto.offset.reset": "earliest"
}}'
Depuis la version 0.10 de KsqlDb, un connecteur Java est disponible.
Celui-ci utilise la librairie “reactive stream” permettant de consommer les résultats des requêtes SQL. Reactive Streams est une initiative visant à fournir une norme pour le traitement de flux asynchrone non bloquant.
Cet exemple illustre la capacité du connecteur KsqkDB à requêter des topics Kafka directement dans le code de manière asynchrone.
client.streamQuery("SELECT * FROM MY_STREAM EMIT CHANGES;")
.thenAccept(streamedQueryResult -> {
System.out.println("Query has started. Query ID: " + streamedQueryResult.queryID());
RowSubscriber subscriber = new RowSubscriber();
streamedQueryResult.subscribe(subscriber);
}).exceptionally(e -> {
System.out.println("Request failed: " + e);
return null;
});
Les cas d’usages de stream SQL ne sont pas les mêmes qu’avec une base de données relationnelle traditionnelle. Kafka stream, de manière générale, répond aux besoins de traitement de flux.
Analyse de logs
Données émanant de capteurs / IOT
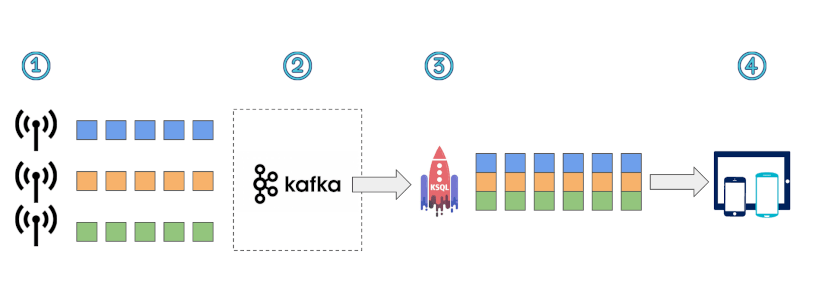
De manière générale, il ne faut pas essayer de faire avec KsqlDb ce que l’on ne ferait pas avec Kafka stream. KsqlDB repose sur ce dernier et hérite donc de ses avantages mais aussi de ses problèmes.
Kafka n’est pas adéquat pour la transformation de données à la volée comme les ETL. La partie Transform nécessiterait la mise en place d'un pipeline complexe de stream. Mieux vaut dans ce cas utiliser un ETL classique.
En cas d’utilisation de plusieurs partitions, l'ordre des messages reçus par les consommateurs n'est pas garanti. Kafka n'est donc pas adapté pour une utilisation de file d'attente de tâches ordonnées. Dans ce cas de figure, RabbitMQ est plus adapté car il garantit l’ordre des messages.
Les prérequis lors d’une jointure sur deux streams
Lorsque les messages sont produits, ils sont envoyés aux partitions en fonction de leur clés et de leur stratégie de partitionnement. L’API stream affecte les mêmes partitions pour chaque topic afin que tous les messages ayant la même clé soient traités dans le même processeur.
Le concept de partitions, un principe de base de Kafka, permet la résilience et la montée en charge. Kafka distribue les partitions sur plusieurs serveurs ou Brokers. En utilisant plusieurs partitions, plusieurs consommateurs peuvent se connecter aux topics et accroître la performance.
L’application productrice doit utiliser la même stratégie de partition. De cette façon, la même clé se retrouvera sur les mêmes partitions qui doivent être jointes.
Les topics doivent utiliser la même stratégie de “timestamp” (horodatage) pour les messages (LogAppendTime ou CreateTime) plus de détails ici. Ceci doit être pris en compte pour les jointures en “windowing” (fenêtres).
Le windowing, ou représentation du temps, permet d’effectuer de manière cohérente des opérations d’agrégation sur des flux et des tables.
Pour les jointures de type “windowing”, les “timestamps” des messages sont pris en compte pour les traitements. Dans cette fenêtre particulière, le résultat apparaîtra une fois la jointure terminée.
Contrairement à une base de données traditionnelle, KsqlDB n'effectue pas de recherche mais uniquement des transformations continues des données entrant dans Kafka. Suite à une requête, la liste des résultats est théoriquement infinie et bornée dans le temps. Tant que des messages entrent dans Kafka, la requête retourne des résultats indéfiniment, contrairement à une requête SQL traditionnelle qui retourne un nombre fini de résultats.
Le fonctionnement de Kafka diffère des autres bases de données. Il ne les remplace pas, il faut le voir comme un outil complémentaire.
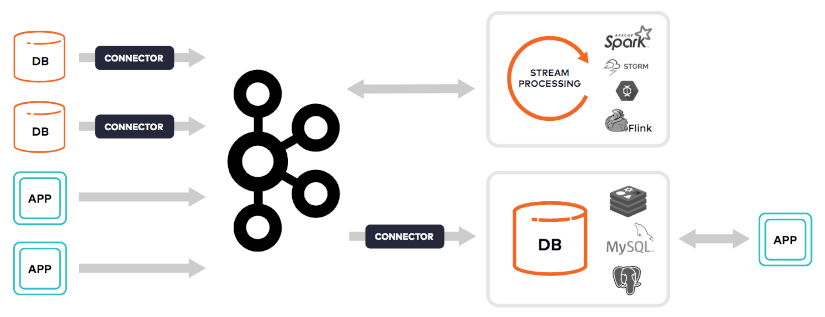
Apache Spark Storm et Flink
Ces produits proposent un framework distribué de stream permettant de consommer un flux de données en entrée, de le traiter (filtres, agrégations …) et de le renvoyer vers un autre moteur de flux.
De par leur capacité de streaming distribué et de consommation de données en SQL, les réelles alternatives à KsqlDB sont du côté de Presto Spark SQL et Flink.
Dès lors que les besoins de requêtage restent relativement simples et que les données à traiter sont en mode flux, KsqlDb fournit une abstraction à la complexité de la plateforme Kafka. Il permet de simplifier le code et d’accélérer le démarrage d’un projet tout en profitant des capacités de montée en charge et de résilience.
Au fur et à mesure de l’avancée du projet la complexité a tendance à augmenter et l’utilisation de l’API Kafka stream peut alors s’avérer plus adaptée.
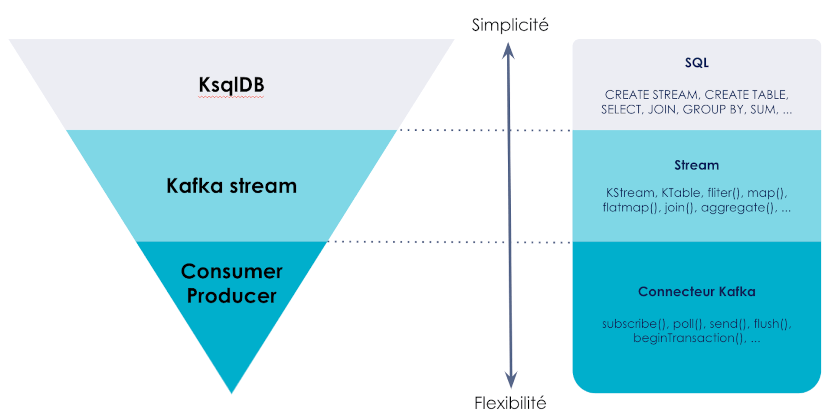
Dans tous les cas, il reste important de bien analyser les cas d’usages métiers avant de se lancer dans un choix technique. KsqlDB, comme beaucoup de produits, ne répond pas à tous les besoins métier.