This article is part of a series designed to demonstrate the setup and use of the Confluent Platform. In this series, our goal is to build an end to end data processing pipeline with Confluent.
Disclaimer: While knowledge of Kafka internals is not required to understand this series, it can sometimes help clear out some parts of the articles.
In the previous articles, we set up two topics, one to publish the input data coming from PostgreSQL and another one to push the data from to AWS S3. But we have yet to connect the two topics together and it is exactly what we will do in this article.
To that end, we are going to use Kafka Streams, do a bit of processing and expose the data for what could be a real-time web UI. Our pipeline will then look more like this
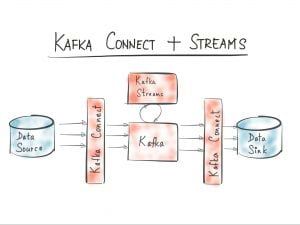
Kafka Streams is a set of lightweight stream processing libraries enabling application design without worrying about the infrastructure behind it.
Using Kafka Stream, your application will be deployed with your Kafka brokers making it highly scalable, elastic, distributed and fault tolerant. Because Kafka Stream is tightly integrated with Kafka, the parallelism of your application will be determined by the number of partitions for your Kafka topics (more specifically the number of partitions of the input stream topic).
Kafka Stream processes event in real time (no micro-batching like Spark Streaming) and allows you handle the late arrival of data seamlessly.
By default, every Kafka Stream application is stateless which allows you to scale it automatically using your favourite process management tools (Kubernetes, Mesos, YARN) but we’ll see there is some way you can actually manage a state with Kafka Stream.
In this article, we are going to use this feature to maintain a state which will be exposed for querying through RPC calls.
Kafka streams defines the following logical components:
Streams and tables are used extensively within Kafka Stream. It introduces the concept of stream-table duality where we view a stream as a changelog of a table continuously updating and a table as a snapshot of a stream.
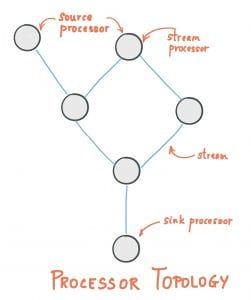
At API level, these components are modelled like this:
At least once processing is guaranteed because the offset is not committed every time a record is read. Thus, it is possible that while recovering from a failure, a record is read twice.
Exactly once semantics (or EOS) is available with Kafka 0.11.0 but is limited to specific use cases when ingesting data although it works with Kafka Streams. It works using compacted topics but that could be the object of a whole other article by itself.
Now that we’ve established the basics, let’s start coding our Kafka streams application ...
Note: the code for the server is available at https://github.com/ArthurBaudry/kafka-stream-basket
If you followed our previous article, you should be able to stream data in a Kafka topic with Kafka Connect, now let’s create a Kafka Streams application that is going to process it.
First, let’s start a Maven project in your favourite IDE and add the dependencies from the pom.xml.
We’ll reuse the classes SpecificAvroSerde, SpecificAvroSerializer and SpecificAvroDeserializer from the schema registry. Those classes are wrapping KafkaAvroSerializer and KafkaAvroDeserializer which extend AbstractKafkaAvroSerializer and AbstractKafkaAvroDeserializer which in turn are directly using Avro libraries to serialise and deserialise data.
We’ll tell Kafka Streams how to deserialise the data published in confluent-in-prices by adding the SpecificAvroSerde as the way of deserialising the values on the <key, value> messages on this topic
settings.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); settings.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG, SpecificAvroSerde.class); settings.put(AbstractKafkaAvroSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG, SCHEMA_REGISTRY_URL);
The Schema Registry URL is important because it will be used to get the Avro schema and deserialize the data into a POJO. Once this is done, we will then be able to manipulate typed objects through the KafkaStream API rather than parsing messages ourselves.
Note: There are two ways to serialize/deserialize with Avro, the one we are using which generates POJO and a generic one which only allows GenericRecord object manipulation and is, therefore, less convenient (no type-safety). This second method is using the embedded schemas in Avro data and therefore is not dependent on the Schema Registry.
To automatically generate POJO from Avro schema files (*.avsc) for development purposes, you need to add the kafka-registry-maven-plugin and avro-maven-plugin to your pom.xml:
<plugin> <groupId>io.confluent</groupId> <artifactId>kafka-schema-registry-maven-plugin</artifactId> <version>3.2.1</version> <configuration> <schemaRegistryUrls> <param>http://<ec2-ip>:8081</param> </schemaRegistryUrls> <outputDirectory>src/main/avro</outputDirectory> <subjectPatterns> <param>^confluent-in-[a-z0-9]+-(key|value)@@ARTICLE_CONTENT@@lt;/param> </subjectPatterns> <subjects> <confluent-in-prices-value>src/main/avro/confluent-in-prices-value.avsc</confluent-in-prices-value> </subjects> </configuration> </plugin> <plugin> <groupId>org.apache.avro</groupId> <artifactId>avro-maven-plugin</artifactId> <version>1.7.7</version> <executions> <execution> <phase>generate-sources</phase> <goals> <goal>schema</goal> </goals> <configuration> <sourceDirectory>src/main/avro</sourceDirectory> <outputDirectory>${project.build.directory}/generated-sources/avro</outputDirectory> </configuration> </execution> </executions> </plugin>
The schemaRegistryUris parameters should point to the public IP of your instance. Make sure port 8081 is actually open.
The registry plugin download maven goal will allow you to download schemas from the schema registry and therefore be up to date on the latest schema version used to produce data.
mvn schema-registry:download
You should see a file created in src/main/avro containing the schema we used to produce data to the confluent-in-prices topic
{ "type" : "record", "name" : "prices", "fields" : [ { "name" : "id", "type" : "int" }, { "name" : "item", "type" : "string" }, { "name" : "price", "type" : "float" } ], "connect.name" : "prices" }
Note: If you chose to change this schema as a reader you could use the test-compatibility goal and check if your schema described in <subjects></subjects> is compatible with the one stored in the Schema Registry.
Note 2: You can also choose to register a new schema from your application.
Once you actually got the avsc file from the Schema Registry you can use the avro maven plugin schema goal to generate POJO classes.
mvn avro:schema
Check out the generated class called prices under target/generated-sources/avro. We can directly use this class in our code.
Note: Since this class is auto-generated during the Maven project compile or package phase, there is no point in maintaining it inside src/, any modification made would be erased every time you would package your application.
Once you got your class, here price, we can deserialize any incoming avro formatted message from the input topic to a price object and manipulate it as is using the KafkaStream API.
Here’s the code base to actually build a Kafka Streams application using our objects
Nothing complicated here, we have a configuration to define our serde and our services like the Schema Registry and our broker. We then create a stream from the topic confluent-in-prices and we push this data back to the confluent-out-prices topic without any processing.
Transformation/aggregation have yet to be implemented. If we were to run the application now, we would have a simple pass through where messages are taken from one topic and pushed to the next.
Note: Depending on how your incoming data is formatted you might be able to save a few CPU cycles by connecting Kafka Streams directly to you Kafka Connect connector. More info at https://www.confluent.io/blog/hello-world-kafka-connect-kafka-streams/.
One of the big advantages of Confluent, as we’ve seen before, is to allow the duality between tables and streams, as a result, we will use a KTable as a snapshot of a stream and provide, through interactive queries, a visualisation layer of our table state.
Interactive queries are a useful feature of Kafka Stream that allows other applications including other Kafka Stream applications to tap into state(s) of a particular application (i.e. tables).
Because states are usually spread across different state stores (especially if your application is deployed across multiple brokers), you need to gather states from all state stores in an application to get a full snapshot.
State stores in Kaka Streams are powered by RocksdB and come in two flavours depending on how you construct them, key-value stores and window stores.
The main difference between the two is that a particular key can have multiple values associated depending on the window while in a key-value store, that same key will only be there once and its value continuously updated over time.
Interactive queries are read-only, the processor topology which created it is the only one to have a write access to the state store. You will never be able to write data from another application into a Kafka Stream state store.
Let’s insert this piece of code in our program to create a state store
Here we are processing our prices object, aggregating by item names and adding the prices of the same items together to get a total per item.
The aggregate operation is actually creating a KTable maintaining a state of the total per item adding the price of incoming items to the existing ones.
Note: When running the application which is going to scale out to many nodes, it’s important to remember that every time you create a state store by using a KTable you are actually creating an instance of a state store on each of the nodes where your application runs.
Now that we have a persisted state for our items, we need to be able to query the aggregates.
There are two ways to query state stores, locally to get the state to a local store or remotely to get the full state of your application, possibly to expose it to other application.
The first method requires less coordination but does not correspond what we want to achieve. We’ll use the first one because we only have one store. The second one is heavier and requires setting up an RPC endpoint which we will do anyway to simulate how we would query state stores over the network from another application. But we won’t implement the discovery part necessary to get the full state of an application over multiple state stores.
Kafka Streams will discover each RPC endpoint through a property called application.server which has to match with the port you are exposing your endpoint on, here we use port 9090.
Let’s design our RPC endpoint first. We have chosen to use Thrift which is a scalable lightweight cross-language service development stack. It uses a compact and fast data serialization as well as its own binary protocol to send the data over the network. It has been designed by Facebook and used by several Big Data technologies. It performs code generation on a thrift file describing the functions and data types a service i.e. the endpoint should expose.
First of all, install Thrift 0.9.3 not 0.10.0 using this documentation
Note: If you encounter a problem with openssl on Mac, follow this link
We are going to add the following properties to our pom.xml to perform code generation with the maven thrift plugin
<plugin> <groupId>org.apache.thrift.tools</groupId> <artifactId>maven-thrift-plugin</artifactId> <version>0.1.11</version> <configuration> <thriftExecutable>/usr/local/bin/thrift</thriftExecutable> </configuration> <executions> <execution> <id>thrift-sources</id> <phase>generate-sources</phase> <goals> <goal>compile</goal> </goals> </execution> <execution> <id>thrift-test-sources</id> <phase>generate-test-sources</phase> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin>
Create a file named prices.thrift
namespace java prices
typedef i64 long // We can use typedef to get pretty names for the types we are using
service KakfaStateService { map<string,long> getAll(1:string store) }
We declare one method that is going to be exposed by our endpoint for anyone to query. This getAll method is going to return the total prices per item.
Run the thrift code generation using the plugin
mvn thrift:compile
A service class should have been generated under target/generated-sources/thrift/prices. We need to implement the actual code of the getAll method in a handler class using the generated interface.
Our implementation is using the Kafka Streams API.
Next, implement the state server class that will boot the thrift server and expose our endpoint i.e. our getAll method.
Add the property application.server to your Kafka Streams configuration and make it point to the same port you’ve configured for your Thrift server.
settings.put(StreamsConfig.APPLICATION_SERVER_CONFIG, "localhost:" + String.valueOf(KafkaStateServer.APPLICATION_SERVER_PORT));
We also need to add the line that will start the server in our Kafka Streams application
KafkaStateServer.run(streams);
Next, let’s package our application
mvn package
Send the jar file to the server and run the application
java -jar yourjar.jar
You should see you Kafka Streams application start. Now we need a client to actually query our aggregates.
Note: If you were to publish an updated version of your Kafka Streams application and there are already some old instances running, Kafka Stream would reassign tasks from the existing instances to the updated one.
The same happens when shutting down an instance of the application, all the tasks running in this instance will be migrated to other available instances if any.
Note: The code for the client is available at https://github.com/ArthurBaudry/kafka-stream-basket-client
Let’s design our client. The whole point of using Thrift is to be able from the same thrift file to generate multiple clients or servers in a different language. We’ll stay in the same language and generate a Java client in the same exact way we’ve done for the server.
Create a new project and use the same thrift file called prices.thrift to generate your thrift service class.
This time, we’ll use the client part to query our remote state store. Make sure port 9090 is open on your instance.
Our getAll method returns a map of total and their total price so our code will simply display the content of the map. Let’s run our code from our IDE. The client should connect to the thrift server without any trouble.
Now let’s go back to our RDS instance and insert more values inside. Let’s make sure we insert the same item several times to witness the results.
psql -h <rds-end-point-url> -U <user> -d <database> INSERT INTO PRICES VALUES ('laptop', 2000); INSERT INTO PRICES VALUES ('laptop', 2000); INSERT INTO PRICES VALUES ('laptop', 2000); Key is laptop and value is 6000
We inserted three times the same item and my client display the total for this item.
Congratulations! You now have an end to end pipeline which carries data from a database to S3 for archiving or further processing while exposing real-time data to third parties application.
Sources: