Cet article fait partie de la série Accélérer le Delivery de projets de Machine Learning, traitant de l’application d’Accelerate dans un contexte incluant du Machine Learning. Si vous n’êtes pas familier avec Accelerate, ou si vous souhaitez avoir plus de détails sur le contexte de cet article, nous vous invitons à commencer par lire l’article introduisant cette série. Vous y trouverez également le lien vers le reste des articles pour aller plus loin.
Certains termes techniques sont numérotés. Vous trouverez leur définition à la fin de l’article.
“Working in small batches”, que nous traduisons par “travailler par petits incréments” est une des capacités (capabilities) de la famille “Lean Product Management" du livre Accelerate [1]. Pour Nicole Forsgren et ses co-auteurs, travailler par petits incréments consiste à découper ses tâches en petits lots qui peuvent être finis en moins d’une semaine. Ils soulignent que ce découpage fin est applicable à la fois :
Travailler par petits incréments permet de réduire le délai de leurs réalisations et ainsi de nous confronter à l’utilisateur final au plus vite. Une approche expérimentale de la conception de produits devient alors plus facile : nous pouvons observer rapidement la réaction de notre utilisateur face à un nouveau produit ou face à une nouvelle fonctionnalité, et savoir au plus vite s’il est pertinent de continuer le développement et dans quel sens. Nous réduisons ainsi la boucle de feedback.
Pour illustrer cette démarche, prenons un cas d’usage où le besoin métier est de créer un moyen de locomotion. Il serait pertinent de d’abord développer un skateboard. Le besoin de se déplacer est comblé, le skateboard est rapide à construire et apporte déjà de la valeur. On itèrera ensuite afin d’améliorer ce premier moyen de locomotion. Et si, après avoir mis dans la main de nos premiers utilisateurs ce skate, le principal retour que nous avons est “J’adore la sensation de la brise dans mes cheveux, mais j’aimerais aller plus vite”, on a là une bonne indication concernant la construction de notre voiture : elle sera décapotable !
Si nous avions directement commencé par développer une voiture, nous serions très certainement passés à côté de ce besoin utilisateur et peut-être d’une plus grande part de marché.
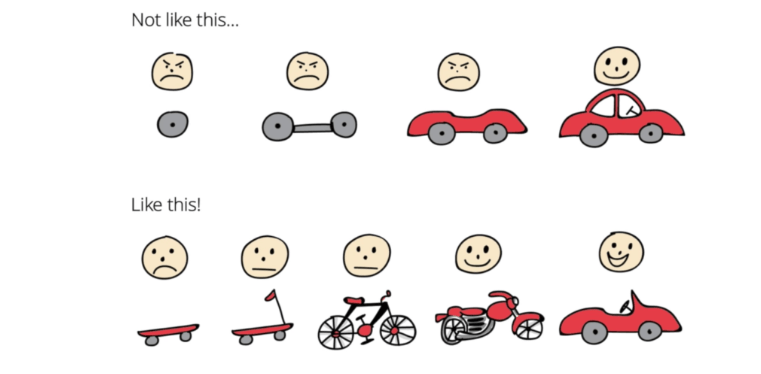
Henrik Kniberg, What is Scrum?
Accelerate a mis en évidence un cercle vertueux entre le lean product management2 et le delivery de logiciel. Améliorer son delivery permet d'être plus “lean" : comme la mise en production n’est plus un sujet, on peut se donner le luxe de travailler par petits incréments et ainsi réduire le délai entre l’hypothèse et sa vérification en conditions réelles. Cela permet de revoir rapidement sa stratégie produit si besoin.
De la même façon, implémenter le lean product management permet d'améliorer son delivery. En effet, ces pratiques ont un impact positif sur la performance de delivery et sont plutôt liées à des cultures génératives au sens de Westrum et à moins de burnouts dans l’organisation .
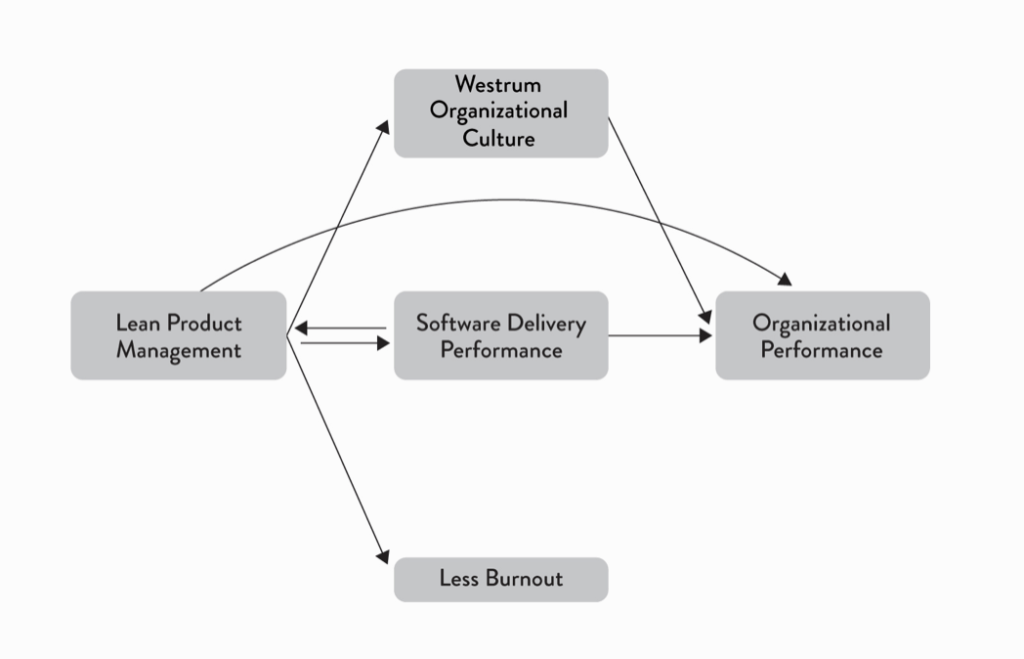
Les impacts du Lean Management - source : Accelerate. Figure 8.2
Dans cet article, nous proposons une démarche permettant de travailler efficacement par petits incréments dans un projet de delivery de ML :
Une particularité des logiciels de ML est qu’ils intègrent des Data Scientists, dont le profil est souvent plus proche de celui d’un chercheur que d’un développeur. Ils ont de ce fait parfois tendance à travailler par cycles plus longs, notamment lors des phases d’expérimentation des modèles. Ces phases d'expérimentation peuvent se transformer en tunnels : les équipes passent des mois à comparer des modèles hors ligne, c’est-à-dire en dehors de leur environnement de production, afin d’optimiser des métriques de Data Science5. On a alors une boucle de feedback qui s’étale et on commence à se demander : quand est-ce qu’on finira par aller en production ?
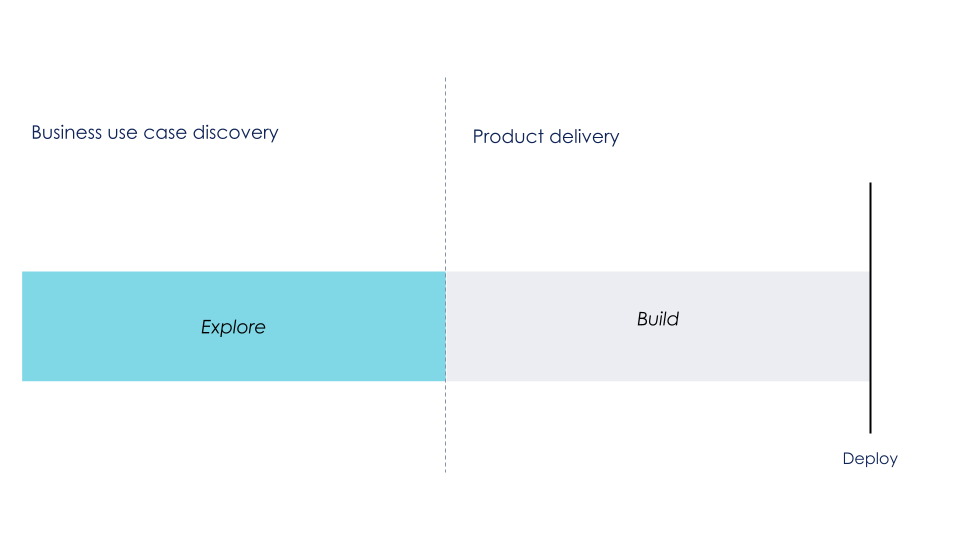
Phase d’exploration tunnel débouchant sur un delivery
Le processus de d_elivery de ML_ ressemble alors plus à un cycle en V ou Waterfall qu’à de l’agile. Pour travailler par petits incréments, il nous semble primordial de passer d’un mode de pilotage basé sur des métriques de Data Science, mesurées hors ligne, à un pilotage basé sur des métriques métier6, mesurées en production. Nous ne pouvons juger la pertinence de notre modèle qu’à partir de ces dernières, les premières étant néanmoins utiles pour décider de passer de la phase d’expérimentation à celle de développement et déploiement. De plus, ce mode de fonctionnement nous permet d’ajuster régulièrement notre cap afin d’éviter de faire partie d’un “projet au cours duquel personne n’a eu de meilleure idée que ce qui était initialement prévu” (Mike Cohn).
Une bonne façon d’y arriver est d’aligner les parties prenantes autour d’un objectif en co-construisant des KPIs7 ensemble. Cela permet de mettre d’accord métier, PO et équipes techniques sur un cap et de suivre l’avancement en direct via leur mesure. De plus, un des objectifs principaux du travail par petits incréments étant de récolter du feedback utilisateur au plus vite, des KPIs centrés sur la valeur qu’on leur apporte nous permet de mieux quantifier ce feedback.
Retour d’expérience au pass Culture
“Le pass Culture est une application qui permet aux jeunes de 18 ans de découvrir les offres culturelles géolocalisées et de les réserver grâce à un crédit de 500 euros”.
Ce projet est une mission de service public qui poursuit deux objectifs à l’égard des jeunes de 18 ans : renforcer et diversifier leurs pratiques culturelles.
Un des leviers identifiés pour atteindre ce double objectif est le développement d’un algorithme de recommandation personnalisé afin :
En partant de cette raison d’être, nous (métier, Product Owner et Data Scientists) nous sommes assis autour d’une table afin de traduire ces objectifs en KPIs, traduisant les enjeux de :
pertinence des offres recommandées par :
diversification par :
performance (au sens du temps de réponse) par :
Ainsi, nos modèles sont jugés en mesurant ces KPIs sur des données de production, notamment via des tests A/B et la création de tableaux de bord. Cela nous incite à mettre en production en cycles courts, afin d’obtenir du feedback. Les métriques de data science ne servent ici que de sanity check.
Exemple de dashboards pour l’algorithme de recommandation du pass Culture (les données ont été cachées par des rectangles bleus par souci de confidentialité)
Avoir des parties prenantes alignées sur la nécessité du travail par petits incréments est un très bon début pour que les choses se passent bien. Il nous semble néanmoins que cela est beaucoup plus facile à condition de respecter quelques pré-requis techniques.
Pour travailler par petits incréments, il nous faut une architecture modulaire et évolutive. En effet, si la moindre évolution dans les fonctionnalités nous oblige à reprendre tout notre code parce qu’il est trop intriqué, une tâche, même petite, peut impliquer un temps de développement très important. Inversement, travailler en petits incréments et découper les tâches plus finement aboutit plus naturellement à une architecture modulable, rappelant la loi de Conway.
Nous discuterons de comment mettre en place une loosely coupled architecture (autre capacité Accelerate) dans un delivery de ML dans un autre article de cette série.
Comme pour le logiciel en général, travailler en petits incréments dans un projet de delivery de Machine Learning est très difficile si le processus de CI / CD est lourd et compliqué, pour ne pas dire inexistant. En effet, avoir un pipeline de CI / CD qui ne marche pas toujours, qui ne teste pas notre système dans sa totalité (front, API, ML, traitement des données…) et qui n’est pas automatisé rend la mise en production laborieuse et douloureuse.
Les équipes auront donc tendance à déployer le moins souvent possible, donc à livrer les incréments par gros lots. En faisant cela, les chances d’avoir un problème quelque part dans la masse de ce que nous sommes en train de livrer augmentent très fortement. On passe ainsi un temps monstre à chercher l’aiguille qui a causé le bug dans la botte de foin de notre release… rendant les mises en production encore plus infernales.
Il est donc essentiel de sortir de ce cercle vicieux - ou, encore mieux, de ne jamais y entrer. Il faut donc travailler sur les capacités de Continuous Deployment, afin de se donner les moyens de travailler en petits incréments. Plusieurs articles de cette série traiteront de leur adaptation au delivery de Machine Learning.
Dans Accelerate, développer par petits incréments permet à la fois de se confronter à l’utilisateur au plus vite et d’éviter l’accumulation de code à mettre en production. Le découpage des tâches doit donc prendre en compte ces deux conditions pour être pertinent. Comment découper alors ses tâches de Machine Learning en respectant ces deux contraintes ?
D’un point de vue fonctionnel, le découpage le plus pertinent est le découpage vertical, qui est une des bases de la méthode agile. Il s’agit de déterminer le plus petit incrément possible qui délivre de la valeur pour l’utilisateur et qui permet de récolter du feedback sur ce que l’on fait.
Prenons l’exemple de la préparation d’une comédie musicale. Pour pouvoir la représenter, il nous faut avoir les dialogues, une composition musicale, une chorégraphie, des costumes, et que tous les artistes connaissent leur rôle. Un découpage horizontal dans ce contexte ressemblerait à ceci :
Dans cette configuration, nous ne sommes capables de livrer de la valeur (la comédie musicale) qu'à la toute fin du processus. Nous aurons donc du mal à montrer notre travail à des producteurs potentiels par exemple. En plus, si par malheur nous avons sous-estimé le temps qu’il nous fallait pour produire tout cela, nous ne serons pas en mesure de monter sur scène le jour de la représentation.
Si, au contraire, nous découpons verticalement les tâches à effectuer, nous commencerons, par exemple, par représenter la scène principale de l'œuvre en jouant la mélodie au piano, en imaginant quelques pas de danse et en piochant quelques éléments de costume dans notre garde-robe. Nous pourrons ainsi montrer quelque chose à des producteurs potentiels, qui pourront plus facilement se positionner et nous donner des conseils précieux pour mieux guider l’écriture de notre œuvre. Nous sommes également mieux armés pour rebondir en cas d’imprévu et être en mesure de présenter quelque chose lors de la représentation.
Sur un projet de ML Delivery, dialogues, musique, chorégraphie, costumes et performance deviennent base de données, pipelinedata, modèle, API, et front. Un découpage horizontal dans lequel il est commun de tomber est de commencer par perfectionner son modèle, puis l’intégrer à une application. Nous préférons livrer, à chaque incrément, des évolutions visibles par l’utilisateur car embarquant toutes les composantes de notre code.
Retour d’expérience au pass Culture
Dans le cadre du pass Culture, nous avons déployé puis amélioré notre algorithme de recommandation en plusieurs étapes, que nous avons choisies et priorisées selon les retours observés à travers le support et le suivi de nos métriques :


Exemples d’offres visibles sur le carrousel de l’application pass Culture
Les recommandations intégrées à la page d’accueil
En pratique, une bonne façon de réussir ce type de découpage est de regrouper les phases d’expérimentation et d’organiser sa roadmap9 en cycles d’expérimentation / développement, permettant d’adapter une solution technique au contexte du métier. Il faut alors trouver un équilibre entre les expérimentations, essentielles dans un contexte de Data Science, et le delivery, essentiel pour mettre notre produit entre les mains des utilisateurs.
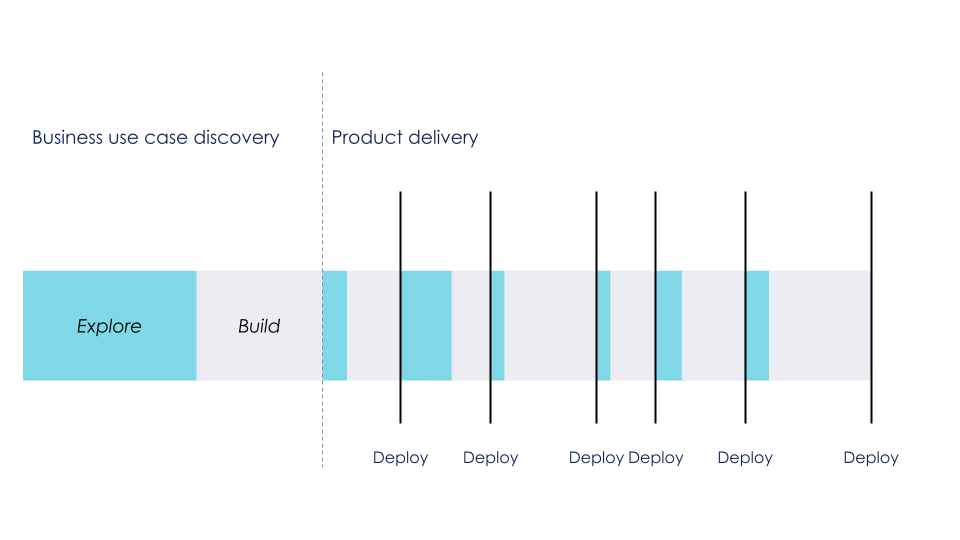
Cycles expérimentation / développement (inspiré de (Agile France) Danse avec les unicorns : la data science en agile, de l'exploration à l'adoption
Le delivery commence par une phase exploratoire pour cadrer le cas d’usage. Le but de cette phase est de s’approprier les données, de valider la faisabilité et de déterminer des pistes d’implémentation. Ensuite, on enchaînera avec des phases d’expérimentations tout au long du delivery, à chaque fois que le développement de nouvelles fonctionnalités nécessite de creuser des sujets de ML.
Retour d’expérience au pass Culture
Après avoir mis en production un premier algorithme de recommandation, nous avons eu de nombreux retours utilisateurs mentionnant leur frustration de se voir recommander des offres loin d’eux. En effet, la première version de notre algorithme ne prenait pas du tout en compte la localisation des offres et des utilisateurs. Nous avons donc identifié notre prochain cas d’usage : la géolocalisation.
Mais, même si nous connaissons notre objectif, il reste une question ouverte : comment proposer des offres culturelles proches de nos utilisateurs sans perdre en diversification ? En effet, si un bénéficiaire habite en haut d’une librairie, nous ne souhaitons pas lui recommander uniquement des livres mais élargir ses horizons culturels. Pour le métier, une distance de plus de 100km ne permettrait pas de répondre à l’objectif de n’avoir que des offres proche de chez soi, mais est-ce suffisant pour proposer à nos utilisateurs des offres diversifiées ? La réponse n’est pas simple, car la densité culturelle varie très fortement à travers le territoire français. Alors, faut-il travailler à une adaptation de cette distance selon la localisation ?
Nous nous sommes mis d’accord avec le métier sur des points de localisation représentatifs des territoires ouverts au pass Culture et avons commencé à explorer les données.
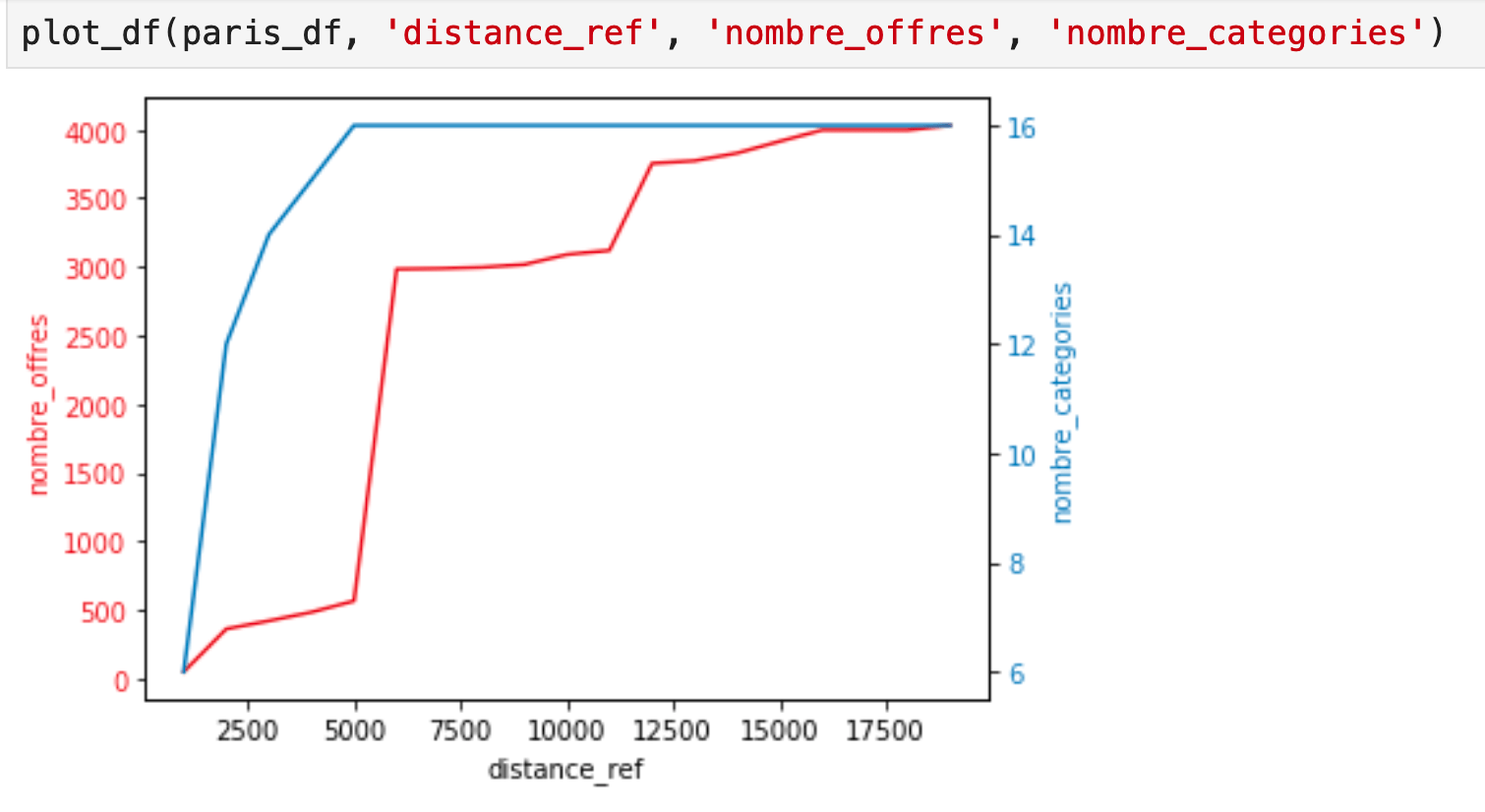
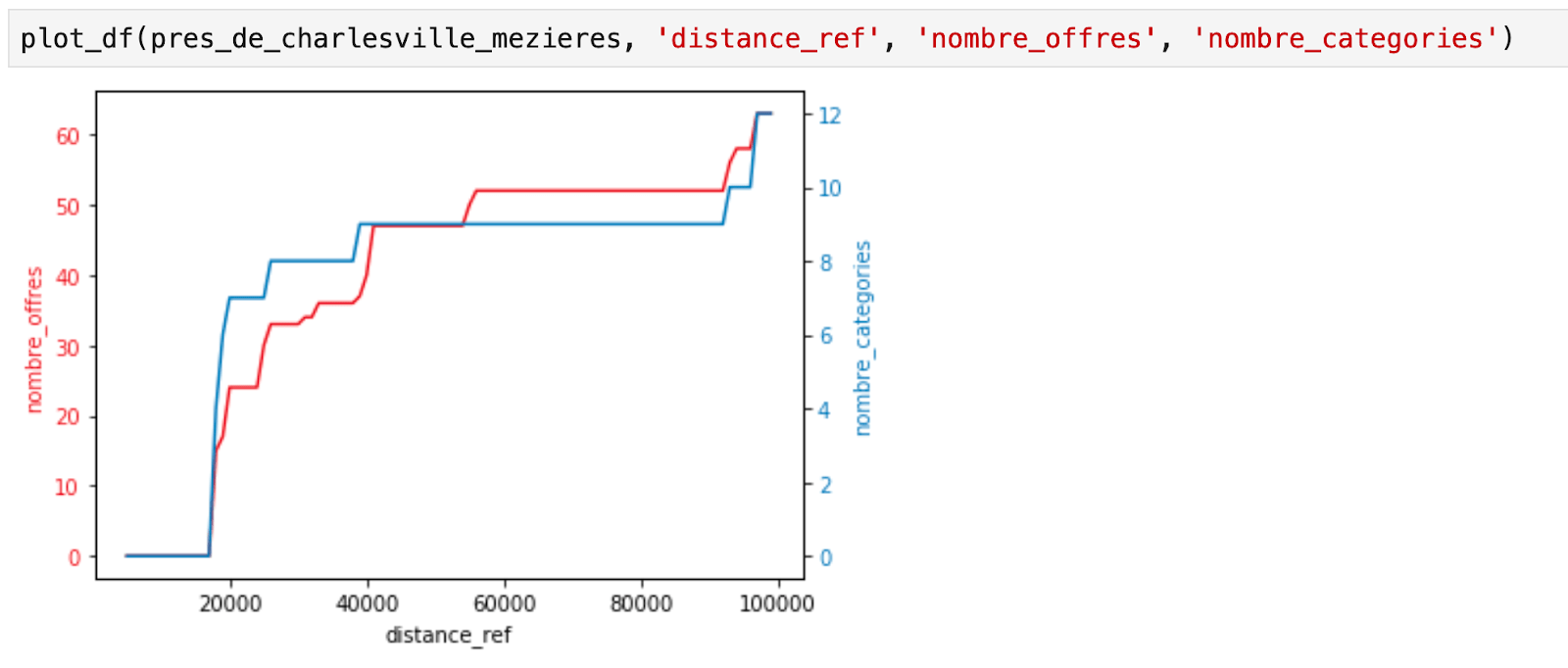
Exemple de graphiques représentant le nombre d’offres et le nombre de catégories en ordonnées et la distance en abscisses pour des points de localisation basés à Paris et à Charleville-Mézières.
Ces expérimentations nous ont permis de voir que, dans les zones moins denses en offres culturelles, chercher des offres à 100km était déjà suffisant pour avoir assez de diversité. Nous avons donc pu cadrer notre tâche pour ne filtrer les offres que selon une distance fixe et déprioriser la personnalisation de la distance.
Privilégier un enchaînement itératif plutôt que séquentiel des phases d’exploration et de développement permet de travailler par petits incréments sur les expérimentations également. Mettre rapidement les résultats d’une expérimentation entre les mains des utilisateurs, leur montrer des maquettes, des notebooks, faire des présentations (selon leur profil : utilisateurs internes, grand public…) rend possible un choix plus éclairé sur les sujets à explorer lors des itérations suivantes, en identifiant ceux qui apportent le plus de valeur.
Dans le même esprit, le découpage vertical des tâches techniques couplé à une mise en production rapide permet de récolter de précieux feedbacks techniques au plus vite. Ainsi, un choix de framework, d’infrastructure ou d’architecture peut être testé afin de le valider ou de revenir dessus avant que cela ne devienne trop compliqué.
Ce concept, développé par Alistair Cockburn dans les années 2000, désigne le produit fonctionnel (i.e. qui “marche”) le plus simple qu’on puisse mettre en production. Il s’agit de l’implémentation minimaliste de notre système de bout en bout, reliant les principales briques de son architecture. Un walking skeleton a comme objectif de s’assurer de la viabilité de l’architecture du projet, en la mettant en place de façon minimaliste dès le début de son implémentation. Il permet de valider des hypothèses d’architecture sans se lancer dans des chantiers hors sol.
Ainsi, dans un projet de ML delivery, un walking skeleton assemble tous les composants permettant de servir un modèle à l’utilisateur final.
Par exemple, pour construire une application recommandant des offres à des utilisateurs, il s’agit de mettre en place :
Notons que dans cette architecture minimale, il n’est pas encore question de Machine Learning. Cet aspect de notre application arrivera progressivementpar l’ajout de fonctionnalités, initialisées notamment en utilisant des tracer bullets.
Cette pratique a comme objectif de lever des incertitudes liées au développement d’une nouvelle fonctionnalité ou à une évolution forte d’une fonctionnalité existante. Il s’agit d’intégrer au code de production une version minimaliste d’une évolution complexe que nous souhaitons intégrer. L’intérêt est de pouvoir tester que cette fonctionnalité marche bien en conditions réelles et pouvoir récolter, en tant que développeur ou data scientist, des feedbacks auprès du métier, des POs, des alpha-testeurs...
Contrairement à un prototype, le code d’un tracer bullet a vocation à être réutilisé en tant que base pour l’implémentation finale, si les tests sont concluants.
Retour d’expérience au pass Culture
Nous avons utilisé des tracer bullets pour lever deux types d’incertitudes :
D’un point de vue technique, un découpage est optimal s’il permet de traiter un petit problème technique à la fois. A première vue, ce découpage horizontal, consistant à mettre en production des incréments par composant applicatif, semble incompatible avec le découpage vertical. La clef d’un bon découpage est en fait de combiner les deux.
La mise en service d’une fonctionnalité de ML nécessite des développements sur plusieurs composants de notre code pour être opérationnelle : la brique d’entraînement, le service du modèle, l’intégration à l’interface graphique, la modification de tables… L’évolution de chacun de ces composants peut ne pas être compatible avec l’état actuel du logiciel. C’est le cas notamment en cas de rupture du contrat d’interface entre deux de ces composants (par exemple, lorsque de nouvelles variables sont ajoutées à notre modèle).
On peut alors être tenté d’attendre d’avoir fini les développements sur tous les composants avant de les mettre en production. Or, cela veut dire laisser notre code fini dormir sur des branches Git le temps de tout finaliser, puis réconcilier toutes ces branches lors d’un merge très douloureux. Cela veut aussi dire déployer beaucoup de choses en même temps. On peut éviter tout cela en utilisant le feature flipping. Il s’agit de décorréler la mise en production de la mise en service en ajoutant un “interrupteur”, permettant d’activer ou de désactiver facilement une fonctionnalité en production. Ainsi, il devient possible de déployer progressivement la fonctionnalité inachevée et de la mettre à disposition des utilisateurs uniquement lorsqu’elle est prête.
Retour d’expérience au pass Culture
Lorsque nous faisons évoluer nos recommandations au pass Culture, nous déployons le code au fur et à mesure que nous finissons les tickets. Pour cela, nous créons une nouvelle route pour les recommandations et une nouvelle interface, que nous mettons en feature flipping OFF. Nous faisons alors évoluer tous les composants de notre application de façon indépendante : cela peut être la base de données, l’algorithme de recommandations, l’affichage… Nous pouvons ainsi intégrer ce nouveau code sans impacter nos utilisateurs. En plus, nous pouvons activer la nouvelle version de notre algorithme, même inaboutie, sur d’autres environnements : testing, staging, ou des environnements éphémères pour faire des tests de charge dans notre cas. Ainsi, nous récoltons du feedback fonctionnel et technique avant la mise en service.
Tout au long de cet article, nous avons vu que travailler par petits incréments est à la fois un problème méthodologique et technique. Dans ce sens, la coopération entre PO et équipe technique, nous semble primordiale.
D’un côté, le PO porte la vision produit et projet. Il fait en permanence le lien avec les équipes métiers, les utilisateurs et l’équipe de développement. Il a un rôle de courroie de transmission : c’est lui qui recueille les besoins, s’occupe de les creuser pour mieux les qualifier et les découper.
Le PO porte également une méthodologie permettant le découpage vertical :
Une fois un sujet cadré, le PO découpe les tâches, tant au niveau des epics10 que des US (user stories11), notamment grâce à la méthode INVEST.
Retour d’expérience au pass Culture
En reprenant l'exemple du pass Culture et de la géolocalisation, on peut par exemple initier un découpage en traitant chaque type de situation. Nous avons ainsi d’abord priorisé une user story pour traiter le cas passant d’un utilisateur géolocalisé en France, puis traité séparément les cas d’utilisateurs non géolocalisés, ou localisés à l’étranger.
Exemple d’user story pour la géolocalisation des offres
De l’autre, l’équipe technique porte la vision technique. Elle a la responsabilité par exemple de mettre en place une architecture modulaire et évolutive ou une CI / CD permettant de mettre en production sereinement un modèle de machine learning. Elle a également l’expérience terrain nécessaire pour anticiper le découpage horizontal : quels composants seront concernés par une fonctionnalité ? Comment découper un gros problème technique en plus petits problèmes ?
Des points de cadrage récurrents, réunissant PO et équipe technique permettent de mettre en commun ces compétences complémentaires et d’aboutir à un découpage fin et pertinent à la fois d’un point de vue fonctionnel et technique.
Nous avons tout d’abord évoqué deux pré-requis permettant le travail par petits incréments :
Nous avons ensuite souligné l’importance d’un découpage des tâches orienté mise en production, c’est-à-dire produisant le plus petit incrément déployable. Cette démarche allie deux visions : le découpage orienté produit (vertical) et le découpage orienté technique (horizontal). Il nous semble donc primordial que PO et équipe technique travaillent main dans la main afin de pouvoir déployer souvent et rapidement - et ainsi produire de la valeur dès le début - avec la promesse d’une amélioration continue.
Le travail par petits incréments est essentiel pour faire sortir le Machine Learning du labo. Il s’agit de sortir du paradigme où on fait du ML parce que c’est innovant et une tendance technologique, pour le mettre au service de l’amélioration du produit.
1 MVP : minimal viable product. Le produit le plus simple répondant aux besoins de l’utilisateur.
2 Lean : méthode de développement produit issue du monde automobile cherchant à minimiser le gaspillage dans la production. La déclinaison du lean dans le monde du software a été théorisée dans Lean software development : an agile toolkit [2].
2 Lean product management : Groupement de quatre capacités d’Accelerate liées au développement produit dans une logique lean :
3 PO : Product Owner. C’est un chef de projet en mode agile. Il est le garant de la vision fonctionnelle d’un produit .Il est chargé de satisfaire les besoins des utilisateurs en menant à bien la livraison d'un produit de qualité. Il sert d'interface entre l'équipe technique, l'équipe métier et les utilisateurs.
4 Équipe technique : composée de profils divers (data scientists, data engineers, développeurs, OPS…), l’équipe technique est responsable de livrer du code de qualité de façon fluide. Pour cela, elle doit porter des convictions sur les pratiques de développement, de déploiement, l’architecture et elle doit savoir trancher lors des choix technologiques. Elle doit apporter au PO une vision de la complexité technique des tâches fonctionnelles.
5 Métriques de Data Science : fonction permettant de mesurer la performance d’un modèle en comparant ses prédictions à ce qu’on appelle en Data Science la ground truth. Il s’agit par exemple d’accuracy, précision, rappel, erreur quadratique moyenne, R2, AUC ROC, parmi d’autres noms barbares
6 Métriques métier : synonyme de KPI dans cet article
7 KPI : key performance indicator
8 CI / CD : Continuous Integration / Continuous Deployment. Il s’agit de la pipeline d’automatisation des tests, de création d’artefacts et de déploiement en production.
9 Roadmap : Feuille de route d’un produit qui sert à porter sa vision
1O Epic : Un ensemble de tâches qui peuvent être subdivisées en plus petites user stories.
11 User Stories : Une description simple d’un besoin ou d’une attente exprimée par un utilisateur. Elle est utilisée dans le domaine du développement de logiciels et de la conception de nouveaux produits pour déterminer les fonctionnalités à développer. C’est un incrément plus petit que l’epic.
[1] Forsgren, N., Humble, J., & Kim, G. (2018). Accelerate: the science of lean software and DevOps: building and scaling high performing technology organizations. IT Revolution.
[2] Poppendieck, M., & Poppendieck, T. (2003). Lean software development: an agile toolkit. Addison-Wesley.