J’ai découvert le Makefile et ses concepts début janvier, lors de mon arrivée sur ma première mission. Cet outil et ses concepts m’ont séduit, me permettant d’orchestrer des actions de manière claire. C’est pourquoi je vous présente cet article.
Historiquement utilisé pour compiler du C, le Makefile est, encore de nos jours, vu sous cet angle. Il n’en est rien! Oubliez le C, gcc et tous ces outils associés au Makefile.
Le Makefile me permet d’ordonnancer des tâches pour créer des fichiers ou d’associer un groupe d’instructions à une commande. Son utilisation est donc totalement agnostique du langage utilisé : il peut être utilisé pour faire autre chose que compiler des projets en C.
Un Makefile est un fichier interprété par l’utilitaire make.
Un Makefile est un fichier contenant une liste de cibles (targets), permettant de définir des groupes de commandes.
Une target peut dépendre de plusieurs targets, permettant ainsi d’orchestrer les tâches entre elles.
https://gist.github.com/luxvex/eb58ef978833e346a81358570f299c97
où target désigne le nom de la cible que l’on veut créer, dependency-i désigne les dépendances (autres targets) requises pour exécuter la target, command-i désigne l’ensemble d’instructions composant la target.
Par défaut, une target est associée à un fichier. Le fichier porte le même nom que la target.
Dans le cas où l’on veut créer une commande qui ne dépend d’aucun fichier, il suffit ajouter le mot clef .PHONY (qui signifie factice) avant la target pour spécifier à Make de ne pas se baser sur un fichier.
Pour en savoir plus sur .PHONY, ces ressources m’ont été utiles:
https://stackoverflow.com/questions/2145590/what-is-the-purpose-of-phony-in-a-makefile
https://maex.me/2018/02/dont-fear-the-makefile/#phony
https://www.gnu.org/software/make/manual/make.html#Phony-Targets
Déclaration de la commande
https://gist.github.com/luxvex/8b4f1f1a1582e51888ef847f90bbdcd3
Appel de la commande -> résultat
make hello → “Hello World”
Les groupes d’instructions peuvent contenir des commandes shell1 diverses, telles qu’un simple echo; ou bien une commande maven avec des paramètres propres au projet (que l’on veut éviter de taper à chaque fois…)
Une aparté sur la gestion des dépendances dans Make
Prenons cet exemple.
J’ai un fichier mytarget qui dépend d’un script shell myScript.sh
https://gist.github.com/luxvex/31465973de50a6c9a20752908c977821
Lors de la première exécution de la target, tout se passe normalement: la target fait son job en copiant le script vers mytarget.
Si je relance la target, elle affichera
make: ‘mytarget’ is up-to-date.Si je modifie le script shell (un simple touch suffit) et que je lance à nouveau ma target, elle sera exécutée.
Au lieu de dépendre d’un fichier (ici le script shell), une target peut dépendre d’une autre target. En généralisant cet exemple, on peut optimiser le séquencement des tâches. Si les dépendances d’une target n’ont pas été modifiées, elle ne sera pas exécutée; à l’inverse, si les dépendances ont été modifiées, la target sera relancée.
Pour avoir plus de détails sur la gestion des dépendances et sur les possibilités du Makefile, je vous invite à parcourir ces articles :
https://blog.mindlessness.life/2019/11/17/the-language-agnostic-all-purpose-incredible-makefile.html
https://maex.me/2018/02/dont-fear-the-makefile/
1 Tout dépend du contenu de la variable .SHELL qui définit l’interpréteur avec lequel les commandes vont être exécutées (bash, zsh, ...).
De nos jours, l’utilisation de technologies diverses au sein d’un même projet est de plus en plus populaire: par exemple, une application Java qui s’appuie sur un cluster Kafka.
Pour faciliter le développement, ce type de stack est souvent modélisée avec Docker pour être exécutée en local.
Pour un projet utilisant Docker, il est souvent nécessaire de relancer le container avec le code mis à jour. Une target make remplit facilement ce besoin.
Par exemple, une commande reload peut compiler une application java en jar pour ensuite déposer ce jar sur un container docker et ainsi relancer ce container.
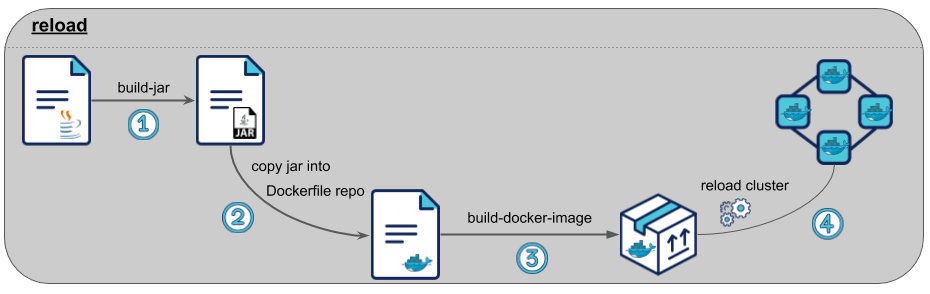
Visualisation des différentes tâches exécutées par la commande reload
Voilà un exemple de Makefile associé à ce use-case:
https://gist.github.com/luxvex/9b586aa4a3689c695e6706c8e5b65cb8
Grâce à ce Makefile, on peut abstraire toutes ces commandes pénibles et redondantes en une ou plusieurs commandes compréhensibles. Interagir avec le projet et la stack technique devient plus simple et intuitif.
Dans le cadre d'une de mes missions, nous utilisions une PIC (plateforme d’intégration continue) pour lancer nos jobs Jenkins, déployer nos développements, versionner notre code avec Gitlab ou le résultat de nos builds avec Nexus.
Dans le contexte de cette mission, la PIC souffre de quelques limitations :
Pour pallier ces problèmes, nous utilisons un Makefile. Les targets de ce Makefile encapsulent chaque étape de chaque job.
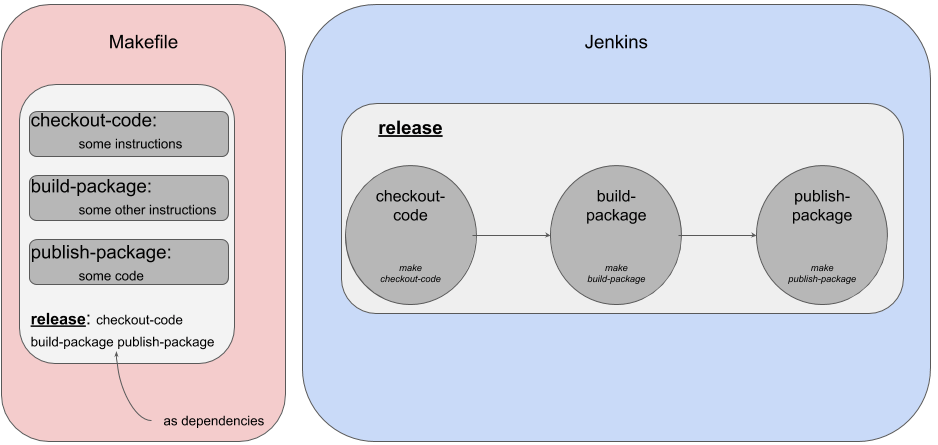
Equivalent target make et stage jenkins
Ici, notre Makefile contient quatre targets: checkout-code, build-package, publish-package et release.
Notre job jenkins release contient trois stages: checkout-code, build-package et publish-package qui font directement appel aux targets du Makefile.
Ainsi, si les jobs Jenkins ne sont pas exécutables car la PIC est indisponible, ils peuvent quand même être lancés avec le Makefile en local (avec make release).
Cela permet aussi de faciliter le développement de ces jobs puisqu’on peut les tester en local. Le feedback est alors beaucoup plus rapide.
L’un des inconvénients est la complexité à débugger seulement via Jenkins. (par exemple, un ops qui n’a pas accès au code ne peut pas corriger facilement l’erreur car les logs Jenkins ne sont pas explicites (`make package`, `make publish`, …).
Cette pratique est ainsi à discuter au sein de l’équipe technique pour débattre de ses avantages et de ses inconvénients.
Toujours dans le cadre de ma mission, une des problématiques est de déployer le même code sur des environnements différents: un environnement de développement, un d’intégration, un de qualification et un de production.
Le comportement du code est identique par environnement, seule la configuration change (adresse des brokers, noms des topics kafka, etc…)
Ansible répond parfaitement à cette problématique. Malheureusement, il ne nous était pas accessible… C’est pourquoi nous nous sommes tournés vers le Makefile pour contourner cette limitation.
Le Makefile est pratique pour ce genre de situation. Il est possible de passer des paramètres à une target Make. (par exemple: make install ENVIRONMENT=INTEG).
Notre architecture de code dispose d’un fichier de configuration par environnement. En précisant cette variable, la target Make saura de quel fichier de configuration elle aura besoin.
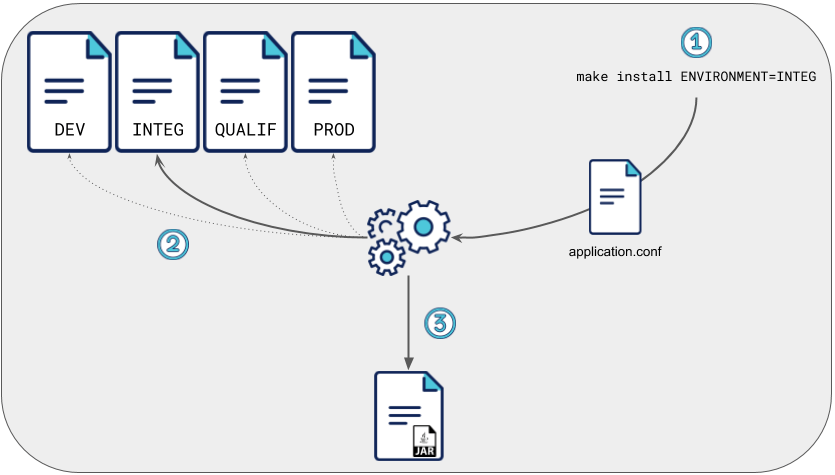
Agrégateur de configuration en fonction de la variable ENVIRONMENT (description simplifiée)
Dans le cas où Ansible n’est pas disponible, je trouve cette utilisation du Makefile très puissante: elle permet d’avoir le même code en fonction de différentes configurations et rend l’installation du code sur un environnement particulièrement facile.
Lors de mon stage chez Octo, quelques mois avant ma première mission, je devais déployer des pods Kubernetes pour effectuer des tests de charge sur des noeuds de bases de données.
Le lancement des tests se faisait à la main: il fallait chaîner quatre ou cinq commandes à la suite, avec des flags particuliers. Régulièrement, j’oubliais un flag, ou bien je me trompais d’ordre dans les commandes à exécuter..
Si je devais le refaire, j’utiliserais un Makefile pour automatiser le lancement des tests de charge, avec des paramètres sur le nombre de pods que je veux lancer et la localisation de ces pods.
Je conseille cet outil pour toutes tâches identiques et répétées.
Le Makefile me permet d’orchestrer des tâches qui mélangent différentes technologies et d’avoir une manière simple et efficace d'interagir avec les actions à faire sur mon projet.
Je trouve qu’il apporte une cohérence (et évite les oublis) lors de l’exécution de commandes. Il permet aussi de rester concis; à l’inverse d’un script bash qui peut rapidement devenir un fourre tout.
Même s’il existe des outils plus spécialisés pour chacun des use cases décrits, dans un environnement contraint comme celui de ma mission, le Makefile sert de couteau suisse super pratique qui ne faillit jamais.
Makefile n’est pas la seule solution pour répondre à ces besoins, il existe d’autres alternatives, comme scons ou waf, qui proposent une autre manière d’orchestrer les tâches, notamment en utilisant python. Vous trouverez ici un aperçu des différentes solutions existantes.
Exemple ici d’une équipe qui raconte son aventure avec le Makefile. Après avoir commencé par utiliser le Makefile, il est devenu trop complexe donc l’équipe a switché vers un script bash. Plus tard, l’équipe apprend qu’il y a une manière plus propre de rédiger son Makefile et elle décide de migrer une nouvelle fois sur cet outil, avec cette fois-ci pour objectif d’être générique, concis, facile à utiliser et indépendant des stacks technologies.