Les conteneurs sont une manière de plus en plus courante de packager et de déployer les applications. Un conteneur comprend tout ce qui est nécessaire au fonctionnement de l’application: le code source ou le binaire de l’application, les fichiers de configuration, l’environnement d'exécution (Java, Python, Nodejs, …) et les bibliothèques.
Il serait difficile de suivre manuellement tous ces éléments. Et autant dire qu’il serait impossible de suivre les vulnérabilités associées. Mais heureusement, il est possible d'automatiser cette tâche fastidieuse avec des outils d’analyse des vulnérabilités.
Dans cet article, nous vous présentons Trivy. Contrairement aux autres solutions, Trivy a l’avantage de s'exécuter directement dans votre UDD (Usine de Développement). Vous n'avez donc pas besoin de serveurs pour vous lancer dans l'analyse de vos conteneurs. D'autant plus que l'initialisation de la base de données s'effectue très rapidement (moins de 5 minutes).
Note: Trivy peut également effectuer l'analyse de dépendances applicatives, mais cela ne sera pas abordé dans cet article. Il existe déjà de nombreux outils en mesure d’assurer pleinement cette fonctionnalité contrairement à Trivy. Un point que l’on pourrait reprocher à cet outil est qu’il n’est pas en mesure de distinguer les dépendances de développement des dépendances de production dans un package.json.
Avec Trivy, l'analyse de votre premier conteneur peut s’effectuer très rapidement :
Etape 1: télécharger la dernière release sur GitHub en fonction de votre système d’exploitation (linux / Windows) et de votre processeur (x64, ARM, …). En téléchargeant directement le binaire, il n’est pas nécessaire d’installer un environnement Go sur votre ordinateur.
Etape 2 : effectuer un scan
$ ./trivy \ --cache-dir .cache/ \ --format table \ --output report.md \ --vuln-type os \ ubuntu:xenial-20190515
Pour effectuer ce scan, les options utilisées sont les suivantes :
Pour plus d’information, l’option --help permet d’obtenir la liste complète des options proposées par Trivy.
Voici un extrait du résultat obtenu sur l’image d’un conteneur particulièrement vulnérable :
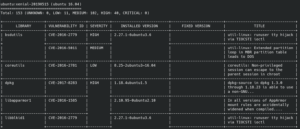
La durée de l'analyse dépendra de la puissance de votre ordinateur et surtout du débit votre connexion pour télécharger le conteneur et la base des vulnérabilités.
Pour effectuer l'analyse d'un conteneur, Trivy doit constituer sa base des vulnérabilités. Cette opération est totalement automatisée et presque transparente pour l'utilisateur. Mais il est essentiel d'en comprendre le fonctionnement pour l'intégrer correctement dans une UDD (Usine De Développement).
L'import des vulnérabilités s'effectue en 2 phases.
Phase 1 : collecte et préparation des données
Cette phase est réalisée par l'outil vuln-list-update qui collecte les données à partir des sources suivantes :
Les données sont ensuite transformées au format JSON puis sauvegardées dans le repository vuln-list.
En tant que simple utilisateur de Trivy, vous n'intervenez pas dans cette phase. Tout cela est effectué par une tâche planifiée sous Travis CI. Cette tâche est exécutée régulièrement pour actualiser le repository vuln-list.
Néanmoins nous pourrions nous interroger sur l'authenticité et l’intégrité de cette base de vulnérabilités. En effet, l’outil vuln-list-update pourrait ignorer certaines vulnérabilités que les auteurs souhaiteraient exploiter. Mais ce scénario aurait peu d’intérêt pour les auteurs puisqu’à partir du moment où une vulnérabilité est détectée, le responsable du conteneur mettra à jour son conteneur, corrigeant par la même occasion les vulnérabilités masquées.
En cas de doute, le code source et le journal d’exécution des tâches sont librement accessible et vous pouvez l’exécuter sur votre serveur.
Phase 2 : création de la base des vulnérabilités
La seconde phase a pour objectif de constituer votre base des vulnérabilités au lancement de Trivy en effectuant les tâches suivantes :
Si Trivy détecte la présence d’une base de données existante, il procédera uniquement à sa mise à jour à chaque lancement.
Au final, le dossier de cache atteint tout de même 3 Go ou 600 Mo en compressant les données. C’est un paramètre à prendre en compte lors de l’intégration de l’outil dans votre Usine de Développement.
La documentation de Trivy propose des exemples d’intégration avec TravisCI et CircleCI. Dans cet article, nous présentons l'intégration de Trivy dans Gitlab.
Pour exécuter la tâche, un simple runner Docker sera nécessaire :
$ gitlab-runner register -n \ --url https://gitlab.com/ \ --registration-token <REGISTRATION_TOKEN> \ --executor docker \ --description “Runner for Trivy” \ --tag-list "trivy" \ --docker-image "docker:stable"
Pour analyser un conteneur, Trivy ne dépend pas de Docker car il utilise la bibliothèque “Fanal”. Cela simplifie la configuration du runner car il n’est pas nécessaire de lui attribuer des privilèges (--docker-privileged) ni de monter le socket docker (--docker-volumes /var/run/docker.sock:/var/run/docker.sock).
Le tag “trivy” permet d’identifier le runner sur lequel sera conservé la base de vulnérabilités. Cela doit être ajusté en fonction du contexte.
Avant l’analyse de l’image, il faut la créer, avec Kaniko par exemple, puis la publier sur un registry, par exemple “registry.gitlab.com”.
Il serait certe plus élégant d’effectuer le scan avant de publier l’image. Pour cela, il faudrait construire l’image dans un fichier TAR (avec kaniko par exemple) puis de l’injecter dans Trivy qui accepte ce format de fichier. Mais un tel fichier atteint une taille importante puisqu’il regroupe à lui seul, l’ensemble des layers. Le transfert du fichier TAR nécessite plus de temps car vous devez télécharger l’ensemble des layers à chaque fois.
Pour la suite de l’article, l’image doit être publiée sur le registry avant l'analyse. Cela permet de bénéficier du système de cache pour ne télécharger que les layers modifiés. A noter que les précédentes version de l’image publiée sur le registry doivent être, elle aussi, vulnérables.
L’analyse de l’image sera effectuée par une tâche intégrée dans le pipeline GitlabCI. La configuration de cette tâche s’effectue dans le fichier “.gitlab-ci.yml” avec la description suivante :
La configuration de la tâche nécessite quelques compléments d’information sur les différentes sections du fichier :
scan image:
stage: scan
image:
name: knqyf263/trivy
entrypoint: [""]
variables:
TRIVY_AUTH_URL: $CI_REGISTRY
TRIVY_USERNAME: $CI_REGISTRY_USER
TRIVY_PASSWORD: $CI_REGISTRY_PASSWORD
tags:
- trivy
script:
- trivy --cache-dir .cache \
--exit-code 1 \
--severity HIGH,CRITICAL \
--format table --output report.md \
--vuln-type os \
$CI_PROJECT_PATH_SLUG:$CI_COMMIT_SHORT_SHA
cache:
key: trivy-cache
paths:
- .cache
artifacts:
name: "Container Scan Report ${CI_COMMIT_SHA}"
paths:
- report.md
expire_in: 7 days
when: on_failure
La configuration de la tâche nécessite quelques compléments d’information sur les différentes sections du fichier :
1/ Définir les variables d’environnement (Lignes 6 à 9)
variables:
TRIVY_AUTH_URL: $CI_REGISTRY
TRIVY_USERNAME: $CI_REGISTRY_USER
TRIVY_PASSWORD: $CI_REGISTRY_PASSWORD
Dans le cadre d’un registry privé, Trivy doit être en mesure de s’authentifier sur le registry. Inutile de lui confier votre mot de passe ou même un “deploy Token”. Gitlab génère des identifiants et des mots de passe pour chaque job.
2/ Sélectionner le runner (lignes 10 à 11)
tags:
- trivy
Le tag indique que le job doit s’effectuer sur un runner dédié à Trivy et qui dispose de la base des vulnérabilités en cache. Aucun autre Runner ne pourra exécuter ce job.
3/ Exécuter Trivy (Ligne 13)
script:
- trivy --cache-dir .cache \
--exit-code 1 \
--severity HIGH,CRITICAL \
--format table --output report.md \
--vuln-type os \
$CI_PROJECT_PATH_SLUG:$CI_COMMIT_SHORT_SHA
Pour une exécution au sein d’un pipeline, Trivy est exécuté avec options supplémentaires :
Les données générées par Trivy (base de vulnérabilité et rapport) doivent être dans le répertoire courant, à savoir le dossier /builds/namespace/projectname. Seuls les fichiers présents dans ce dossier pourront être mis en cache ou en artifact.
4/ Mise en cache (Ligne 14 à 17)
cache:
key: trivy-cache
paths:
- .cache
Ce cache permet de conserver en local la base des vulnérabilités, améliorant ainsi la rapidité d’exécution des prochaines analyses.
Néanmoins, il faut savoir que :
5/ Enregistrer le rapport (Lignes 18 à 23)
artifacts:
name: "Container Scan Report ${CI_COMMIT_SHA}"
paths:
- report.md
expire_in: 7 days
when: on_failure
L’artefact sera une archive zip contenant le rapport au format Markdown. Cet artefact sera généré uniquement en cas d'échec du job, c’est-à-dire lorsque Trivy a trouvé une vulnérabilité. Dans le cas contraire, le rapport n’est pas nécessaire.
Après l’analyse, Trivy génère un rapport au format Markdown (ou JSON). Il faut alors prendre en compte les vulnérabilités et mener les actions correctives. La mise à jour des composants sera généralement la solution mais nous pouvons identifier des cas particuliers :
En synthèse, voici les 4 options possibles pour traiter une vulnérabilité :
Trivy est une alternative intéressante par rapport aux outils existants (Clair, Anchore, …) pour identifier les vulnérabilités connues dans un conteneur. Il est utilisé notamment par “vulnerablecontainers.org” qui analyse les 1000 images les plus utilisées.
Trivy a l'avantage de s'exécuter entièrement dans votre UDD (Usine De Développement). Même si les solutions alternatives (Xray, clair, …) peuvent s'intégrer dans votre UDD, elles nécessitent, à minima, un serveur applicatif et un serveur de base de données. Trivy vous évite ainsi la mise en oeuvre de cette infrastructure. Vous n'avez donc plus d'excuse pour ne pas faire l'analyse de vos conteneurs!
L'autre avantage de Trivy est sa rapidité pour constituer sa base de vulnérabilités même lors de sa première exécution. Vous pouvez donc effectuer votre première analyse en moins de 5 minutes.
Néanmoins, Trivy n’est pas conçu pour surveiller en permanence l’apparition de nouvelles vulnérabilités. Par conséquent, il n’est pas capable transmettre des notifications “temps réel” en cas de nouvelle vulnérabilité sur un conteneur. Suivant le contexte, il faut exécuter Trivy régulièrement, par exemple via des tâches planifiées, ou utiliser un autre outil plus adapté (exemple : Anchore, Harbor, ...).