Depuis quelques années, quand je découvre un projet je vois régulièrement des répertoires qui s'appellent :
Je me suis interrogé sur le sens de ces mots. Est-ce qu’ils sont liés à un pattern en particulier ? J'ai eu des réponses diverses en fonction des projets :
Quelle est la bonne réponse ? D'où viennent ces mots ? Quel intérêt à les utiliser ou ne pas les utiliser aujourd'hui ? Je me suis documenté sur le sujet et je vous propose un voyage dans le temps pour y voir un peu plus clair.
J'ai commencé à entendre les mots Application, Domain et Infrastructure quand je me suis intéressé à des projets qui illustraient soit le Domain-Driven Design, soit l'architecture hexagonale, soit la Clean Architecture.
Dans ces projets, j'ai plusieurs fois observé des répertoires racines nommés soit Application, Domain et Infrastructure,
. ├── application/ ├── domain/ └── infrastructure/
Soit simplement Domain et Infrastructure.
. ├── domain/ └── infrastructure/
Voir en annexe pour un exemple de code.
Curieusement, les mots Application, Domain et Infrastructure ne sont pas particulièrement mis en avant :
Pourquoi cette absence ? D'où viennent alors ces mots ? Il faut remonter plus loin dans le passé.
Dans mes recherches vers le passé, la première mise en évidence de ces mots se trouve dans le livre "Domain-Driven Design" d’Eric Evans (2004). Ci-dessous, une illustration du début du chapitre 4 (Isolating the Domain).
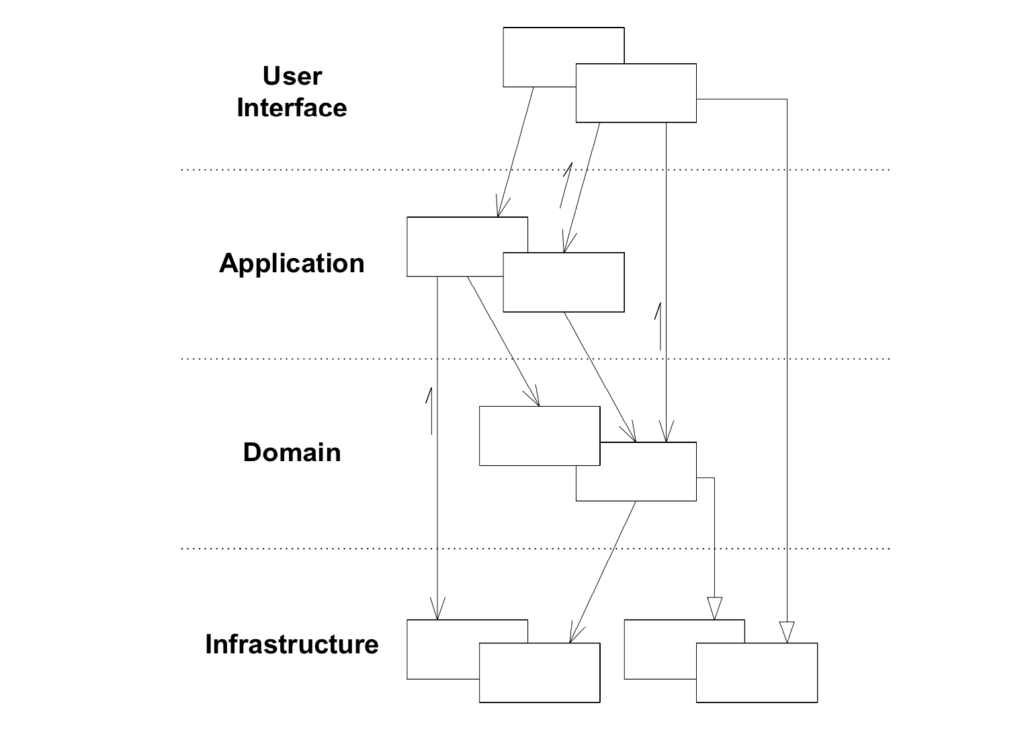
User Interface, Application, Domain, Infrastructure. Dans un premier temps, j'ai cru avoir tout compris : ces architectures ont, comme DDD, l'intention de mettre le métier en avant. Les partisans de ces architectures utilisent donc le vocabulaire du livre "Domain-Driven Design". Et d'ailleurs le mot Domain semble le confirmer.
En réalité, il faut remonter encore un peu plus loin dans le temps. Que décrit donc cette section illustrée du chapitre Isolating the Domain ? Elle décrit une architecture plus simple et encore antérieure : une architecture en couches. C'est d'ailleurs le titre de la section : Layered Architecture.
Un an avant, dans "Patterns of Enterprise Application Architecture"__ de Martin Fowler, on trouve aussi une description de la Layered Architecture. Cette version utilise des mots et une séparation un peu différents :
Ici la couche Presentation correspond à la couche User Interface vue dans Domain-Driven Design. Cette couche inclut les commandes de l’utilisateurs mais aussi les requêtes HTTP et ligne de commande. Également, dans ce livre, Martin Fowler parle de Service Layer pour désigner ce qu'Eric Evans appelle Application Layer.
En remontant encore quelques années dans le temps, j'ai trouvé deux références connues dans les années 90, période où cette architecture a gagné en popularité.
Dans "Pattern-Oriented Software Architecture, A System of Patterns, Volume 1" de Frank Buschmann, Regine Meunier & al. (1996), on trouve une description du pattern Layers. Ce pattern est généraliste et montre beaucoup d'exemples dans des contextes très variés, en commençant par les 7 niveaux des protocoles réseau du modèle OSI.
Un des exemples, intitulé Information Systems, utilise ces couches :
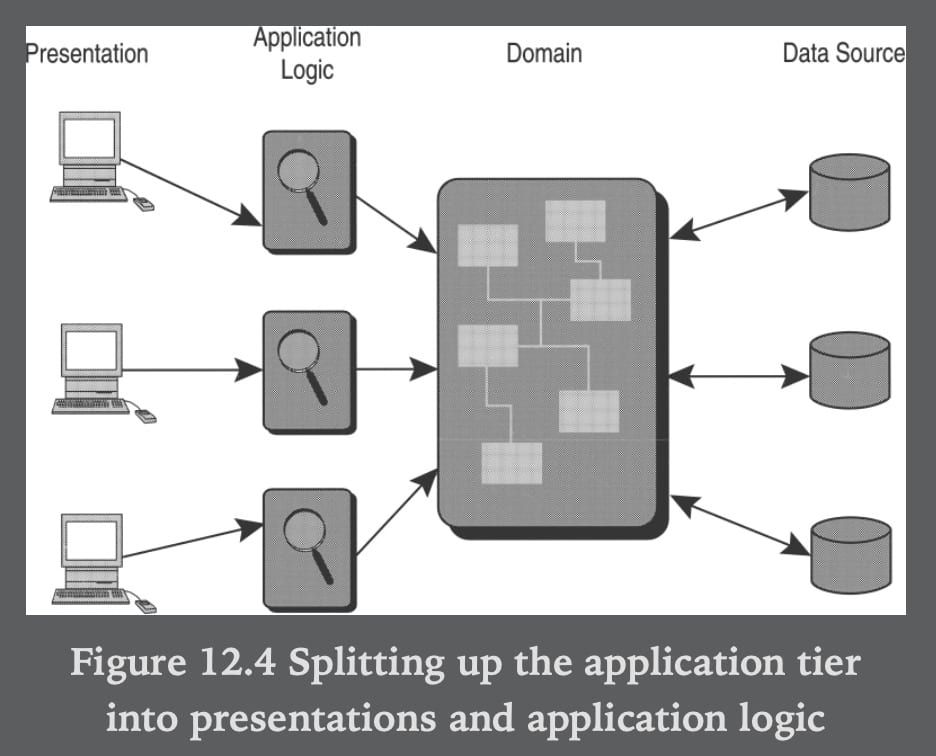
La même année, dans "Analysis Patterns: Reusable Object Models" de Martin Fowler, le chapitre 12 décrit la Layered Architecture for Information Systems. En particulier des architectures à deux niveaux, trois niveaux (Three-tier Architecture) puis quatre niveaux très similaires :
L’idée elle même, avec un vocabulaire différent, est même plus ancienne que ça. Martin Fowler nous parle d'une Three-schema Architecture datant de 1978 avec :
Je pense donc que, d’une part, l’idée des séparations de type Application, Domain, Infrastructure remontent à la fin des années 70 puis ont été popularisées au milieu des années 90, et, d’autre part, que ces mots en particulier ont pris de l’importance entre 1996 et aujourd’hui, probablement aidés par les trois livres "Analysis Patterns", "Pattern-Oriented Software Architecture" et "Domain-Driven Design" dans sa description de la Layered Architecture.
Pourquoi le livre "Domain-Driven Design" nous parle d'architecture en couches ? Comme on a pu le voir il se trouve que c'était une architecture solide, populaire et bien documentée au moment de son écriture. C'était l'état de l'art qu'Eric Evans proposait en 2004. Mais depuis la publication du livre, l'architecture hexagonale en 2005, puis d'autres patterns comme CQRS et des architectures orientées événements sont devenus bien plus populaires dans la communauté DDD, qui à ma connaissance en 2020 ne parle plus d'architecture en couche.
Sachant tout ça, est-ce que c’est pertinent aujourd’hui d'avoir des répertoires nommées Application, Domain, Infrastructure ? Même si, en 2020, vous n'utilisez probablement pas une architecture en couche telle que décrite dans le livre "Domain-Driven Design" ?
. ├── application/ ├── domain/ └── infrastructure/
Je pense que ça peut très bien fonctionner à condition de bien connaître l’architecture qu’on a choisie, et d’expliciter clairement dans notre contexte ce qu’on met dans chaque répertoire.
Par exemple :
infrastructure/api/ et un répertoire infrastructure/persistence/.Pour une présentation de l’architecture hexagonale, voir :
Par exemple :
Pour une présentation de la Clean Architecture, voir :
Avec d’autres architectures dont le principe est d’isoler le code métier, ça fonctionnera probablement aussi bien.
D’expérience, il est utile de bien expliciter ce qu’on met dans le répertoire "application" : dans les exemple qu’on a vu, c’est très souvent dans le sens de “application logic” ou “application business rules”, une fine couche d’orchestration de logique au sens métier.
Attention certains frameworks comme Ruby on Rails ou certains frameworks front comme Ember appellent “application” ou “app” leurs points d’entrée dans notre code ou leur répertoire racine.
Malgré l’usage du même mot, ce n’est pas du tout notre répertoire application. La place de notre code qui est appelé par ces frameworks est bien de la présentation, à ranger dans l’infrastructure. Ou à la rigueur, on peut ajouter un répertoire “presentation” à la racine, c’est cohérent avec tout ce qu’on a vu.
. ├── presentation/ ├── application/ ├── domain/ └── infrastructure/
. ├── domain/ └── infrastructure/
Une option qu’on voit aussi beaucoup et qui fonctionne est de n’avoir que “domain” et “infrastructure”. On isole le code métier dans “domain”, et on met tout le reste (code lié à la présentation et adaptation associée, code lié à la persistance et adaptation associée) dans un répertoire “infrastructure”.
Encore une fois, à nous de bien structurer ce qu’on met dans “infrastructure”.
Enfin, nous sommes tout à fait libres d’utiliser d’autres mots pour ranger notre code, l’important est que nos répertoires racines soient cohérents pour notre équipe dans notre contexte.
Par exemple, ce projet en architecture hexagonale montre une arborescence très claire sans utiliser ces mots "application", "domain", "infrastructure" :
Ce serait intéressant de l'analyser, peut-être dans un autre article ?
On a identifié l’origine probable des mots Application, Domain, et Infrastructure, observé comment ils ont évolué dans le temps, et vu comment ils peuvent rester pertinents aujourd’hui. On a aussi vu qu'il y a beaucoup de variantes de vocabulaire, et évoqué qu’on peut très bien ne pas utiliser ces mots, ce n'est pas une recette à appliquer partout.
J’espère que cette exploration vous aidera à mieux comprendre du code récent ou ancien en fonction du contexte, et aussi que ça vous aura donné un peu envie d’explorer l’histoire des mots qu’on utilise dans notre code.
Par exemple, en plus de ces mots, Application, Domain, Infrastructure, je vous invite à bien connaître les mots de l’architecture que vous avez choisie, que ce soit User-Side et Server-Side pour l’Architecture Hexagonale, ou Frameworks and Drivers, etc. pour la Clean Architecture.
Enfin, pour plus de détails, je vous invite à lire les descriptions des architectures qu'on a évoquées dans les livres et articles de références cités dans ce tour d'horizon spatio-temporel.
Ce repository qui illustrait le Domain-Driven Design, initié vers 2008 par une équipe comprenant Eric Evans, utilise ces mots application / domain / infrastructure :
Dans src/main/java/se/citerus/dddsample, on trouve les répertoires :
. ├── application/ ├── config/ ├── domain/ ├── infrastructure/ └── interfaces/
Le répertoire application contient l'interface de programmation du code métier, une fine couche qui orchestre le code métier :
src/main/java/se/citerus/dddsample/application/ ├── ApplicationEvents.java ├── BookingService.java ├── CargoInspectionService.java ├── HandlingEventService.java └── impl/ ├── BookingServiceImpl.java ├── CargoInspectionServiceImpl.java └── HandlingEventServiceImpl.java
Dans domain, on trouve les objets et les règles métier, par exemple pour les marchandises (cargo) :
src/main/java/se/citerus/dddsample/domain/model/cargo ├── Cargo.java ├── CargoRepository.java ├── Delivery.java ├── HandlingActivity.java ├── Itinerary.java ├── Leg.java ├── RouteSpecification.java ├── RoutingStatus.java ├── TrackingId.java └── TransportStatus.java
Et le répertoire infrastructure contient le code de persistance et de messaging :
src/main/java/se/citerus/dddsample/infrastructure/ ├── messaging/ │ └── jms/ ├── persistence/ │ └── hibernate/ └── routing/ └── ExternalRoutingService.java
Cet autre exemple de Kamil Grzybek utilise des répertoires Application / Domain / Infrastructure dans ses modules, qui correspondent chacun à des bounded contexts :
Vous pouvez inspecter chaque module :
Source image :