Il n’est plus utile de le présenter, Ansible s’est imposé comme un des outils standards pour gérer le déploiement d'infrastructures. Le modèle de connexion qu’il utilise (push), et son opposé (le pull) a suscité beaucoup de débats sur les avantages et inconvénients car c’est un élément clivant dans le choix d’un outil d’Infrastructure as Code. Nous allons parler aujourd’hui d’une fonctionnalité d’Ansible relativement peu connue même si elle existe depuis longtemps. Cette fonctionnalité, nous allons le voir, propose de passer en modèle pull sur lequel Ansible repose et permet ainsi d’annuler quelques contraintes associées.
Nous allons débuter par un petit rappel sur le modèle push, nous présenterons ensuite ce qu’est réellement Ansible-pull de manière théorique puis avec un exemple d’utilisation. Nous creuserons quelques points de détails sur le mode multi-machine et la gestion des secrets. Nous terminerons par un ensemble de limitations qui nous font dire qu’il faut réserver l’utilisation d’Ansible-pull à certains cas.
Les outils d’Infrastructure as Code, dont l’objectif est de définir sous forme de code des infrastructures, sont souvent classés selon différents modèles. Un des modèles régulièrement utilisé est un classement sur le modèle de connexion push versus pull :
Le modèle de connexion push/pull détermine donc le fait que les machines contrôlées sont actrices ou non pour appliquer les changements.
Ci-dessous une illustration du modèle push :
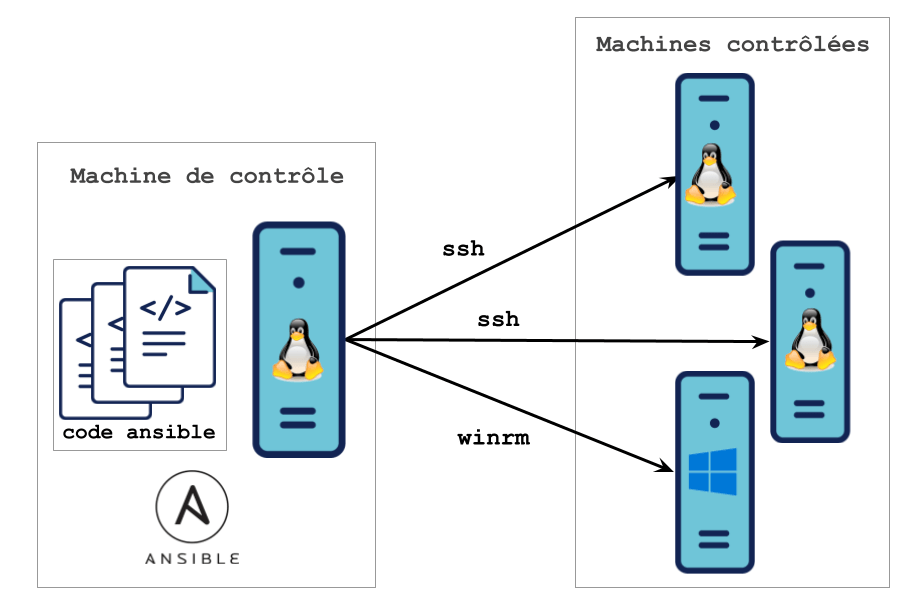
La machine de contrôle est la machine depuis laquelle Ansible est exécuté. Elle contient donc une copie du code source qui définit l’état de l’infrastructure souhaitée. La machine de contrôle peut être un poste de travail (pour des phases de mise au point) ou un orchestrateur dans une usine de développement. Contrainte Ansible oblige, cette machine sera forcément sur un système d’exploitation Linux/BSD (à l’inverse des machines contrôlées qui peuvent aussi être sur Windows).
Quasiment aucun prérequis n’est nécessaire sur les machines contrôlées : la machine de contrôle doit pouvoir se connecter dessus (en SSH, WinRM, ...) et Python doit être installé (il est toutefois possible de l’installer si ce n’est pas le cas via Ansible avec le module raw). Aucun agent spécifique n’est nécessaire.
Voici quelques avantages et inconvénients qui découlent du modèle push. Nous avons fait le choix de ne pas être exhaustifs et de ne cibler que ceux intéressants pour la suite : + faible empreinte sur l’infrastructure : (quasiment) pas de prérequis sur les machines contrôlées (pas d’agent à installer) + modèle simple : une seule machine, la machine de contrôle, réalise l’orchestration des tâches : cela permet de réaliser simplement ce qu’on effectue depuis les postes de travail.
- nécessité d’avoir un accès SSH/WinRM depuis la machine de contrôle sur les machines contrôlées. Cela impose donc d’avoir un flux ouvert entre la machine de contrôle et la machine contrôlée et également d’avoir un compte applicatif avec lequel se connecter.
Cela paraît anodin mais par exemple dans une approche où l’on se positionne comme un cloud provider (cloud interne par exemple), si l’équipe sécurité souhaite utiliser Ansible pour effectuer le durcissement des VMs ou d’installer des agents, cela signifie qu’elle doit avoir accès aux VMs : ce qui ne sera pas forcément accepté par les équipes projet.
Ansible-pull est simplement une commande dans la galaxie des commandes Ansible et non un agent qui s’exécute en tâche de fond sur le système d’exploitation.
Liste des binaires présents dans l’installation du paquet Ansible :

À son lancement, Ansible-pull va télécharger le code qui décrit l’état cible attendu depuis un dépôt de code. La commande se terminera à la fin de l’exécution. S’il n’y a pas un élément (orchestrateur) externe qui relance la commande, Ansible-pull ne se ré-exécutera pas. Nous verrons plus loin les limites inhérentes à ce modèle.
Les machines qui exécutent la commande Ansible-pull deviennent donc « actrices » de leur changement.
Illustration avec Ansible-pull :
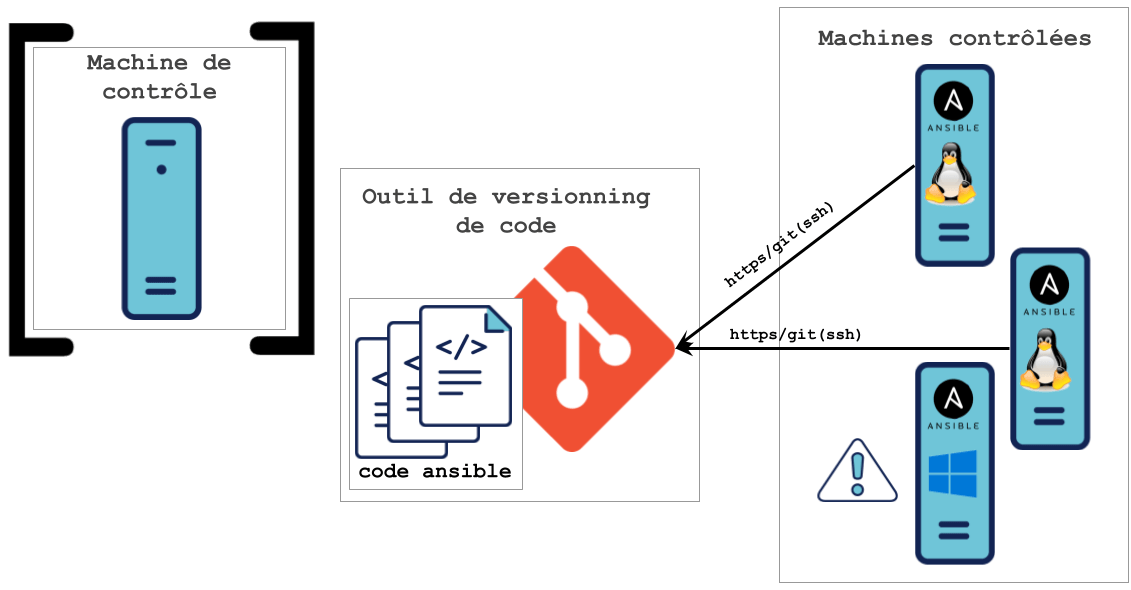
Dans ce modèle, le binaire Ansible-pull doit être installé sur chaque machine contrôlée.
Comme vous l’avez certainement noté, il y a deux points qui peuvent être relevés :
Nous allons provisionner des machines virtuelles sur un cloud provider (AWS ici) puis installer Ansible-pull et configurer une exécution régulière via une tâche planifiée (crontab).
Illustration de l’exemple : 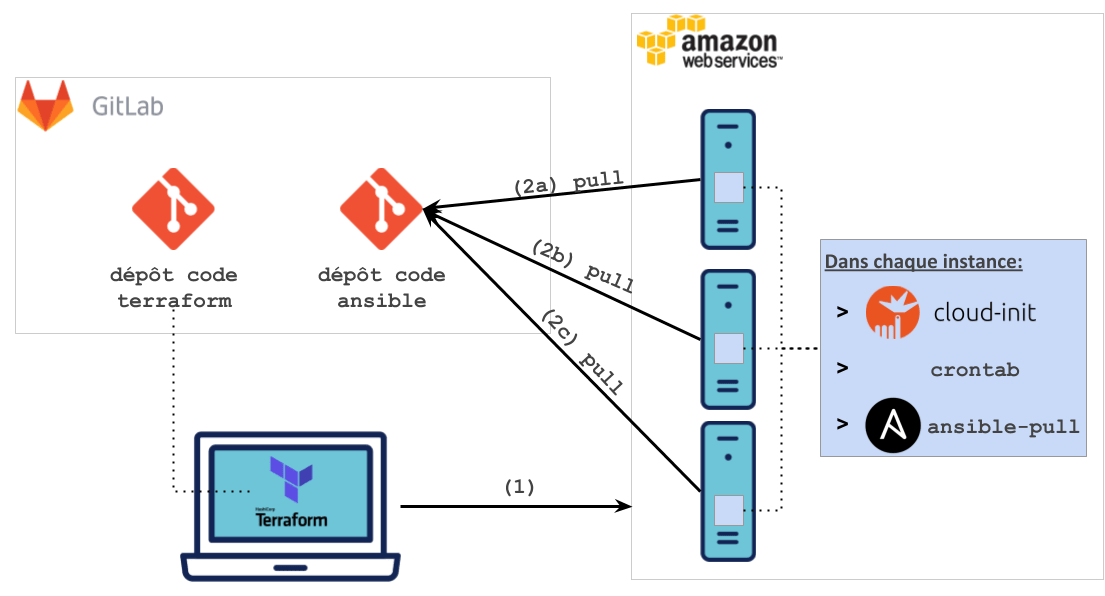
Quelques extrait de code : Template Terraform qui permet de générer le fichier de configuration cloud-init exécuté au démarrage (user_data.tpl):
#cloud-config
apt_upgrade: true
apt_sources:
# PPA shortcut:
# * Setup correct apt sources.list line
# * Import the signing key from LP
#
# See https://help.launchpad.net/Packaging/PPA for more information
# this requires ‘add-apt-repository’
– source: « ppa:ansible/ansible » # Quote the string
packages:
– software-properties-common
– ansible
– git
write_files:
– path: /etc/ansible-pull/cron.sh
owner: root:root
permissions: ‘0744’
content: |
ansible-pull provision.yml –url ${git_repository} –checkout step1 –accept-host-key -i localhost -e node_type=${node_type} -e env=${env}
runcmd:
# do not create this file in write_files part since /etc/cron.d does not yet exists
– [ sh, -c, « echo ‘*/30 * * * * root /etc/ansible-pull/cron.sh > /var/log/ansible-pull.log 2>&1’ > /etc/cron.d/ansible_pull_cronjob »]
Dans ce fichier, les variables incluses dans les marqueurs ${} seront résolues par Terraform lors de la création des machines virtuelles.
Analysons les paramètres fournis à la commande Ansible-pull : 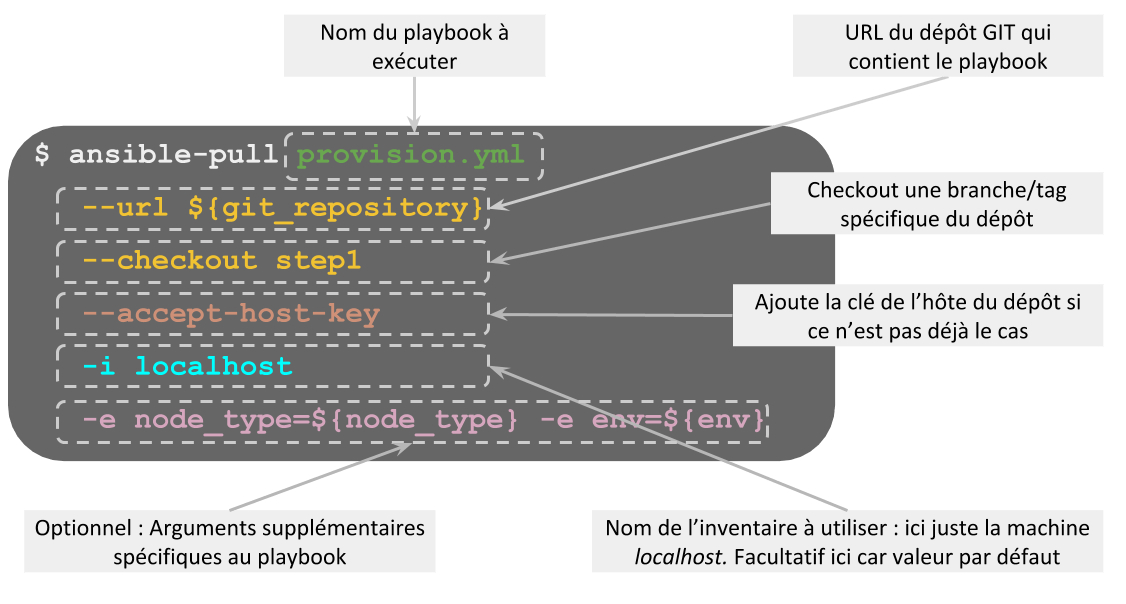
Le code Terraform qui permet de créer les instances est très classique. Ci-dessous l’extrait de code qui permet de définir le template du cloud-init et l’instance AWS qui utilise ce template en tant que via les user_data :
data "template_file" "script-web" {
template = "${file("${path.module}/user_data.tpl")}"
vars {
node_type = "web"
env = "${var.env}"
git_repository = "${var.git_repository}"
}
}
resource "aws_instance" "puller-web" {
ami = "ami-4d46d534"
instance_type = "t2.micro"
key_name = "${var.aws_keypair}"
vpc_security_group_ids = ["${aws_security_group.ansible-pull-demo-almost-openbar.id}"]
associate_public_ip_address = true
source_dest_check = false
user_data = "${data.template_file.script-web.rendered}"
subnet_id = "${aws_subnet.main.id}"
tags {
Trigramme = "${var.aws_trigram}"
Topic = "ansiblepulldemo"
Name = "puller-web"
}
}
Contenu du playbook qui est exécuté par Ansible-pull :
- hosts: localhost
tasks:
- name: Write env_infos file in /etc folder
copy:
content: |
node_role: {{ node_type }}
env: {{ env }}
dest: /etc/env_infos
Le code complet de l’exemple se trouve dans le dépôt https://github.com/ylascombe/ansible-pull-demo sous le tag step1.
Dans cet exemple, le dépôt de code qui contient ce playbook est constitué seulement de ce fichier mais la structure du dépôt cible possédera généralement la structure classique de dépôt de code Ansible :
site.yml # playbook principal
roles/
common/ # rôle qui effectue les tâches communes
tasks/ #
main.yml # <-- fichier contenant les tâches
handlers/ #
main.yml # <-- handlers
templates/ # <-- fichiers templates
ntp.conf.j2 # <------- templates end in .j2
defaults/ #
main.yml # <-- Variables propres aux rôle
webtier/ # rôle qui effectue les tâches spécifiques aux VMs “web”
Comme Ansible-pull est fait pour travailler en local, le mode de connection qu’il utilise par défaut est “local”. Cela évite ainsi d’ouvrir une connection SSH sur la machine elle-même. Faute de documentation claire à ce sujet, nous avons vérifié ce comportement dans des tests et c’est le cas.
Cela signifie que sans précisions, chaque machine décrite dans l’inventaire sera considérée comme locale. Ainsi, si vous souhaitez exécuter Ansible-pull sur des machines distantes, il est nécessaire de préciser pour ces machines distantes le paramètre ansible_connection=ssh. Hormis cette précision, somme toute importante, il n’est pas nécessaire de modifier votre code avec des local_action ou delegate_to pour le faire fonctionner.
Illustration par du code :
Fichier d’inventaire de test
[remote_vms]
10.20.30.40 ansible_connection=ssh ansible_user=ubuntu
[remote_without_ssh_cnx]
10.20.30.41
Pour le playbook ci-dessous :
- hosts: remote_vms remote_without_ssh_cnx
tasks:
- name: Write test-file.txt in /tmp folder
copy:
content: "file content for instance {{ ansible_hostname }}"
dest: /tmp/test-file-{{ ansible_hostname }}.txt
Le même code aura 2 comportements différents pour la machine du groupe remote_vms et celle du groupe remote_without_ssh_cnx :
Cela nous a amené à nous demander s’il est possible d’utiliser les delegate_to avec Ansible-pull. Ici aussi, la réponse est oui mais ce ne sera pas aussi facile qu’en mode Ansible normal. Nous pouvons distinguer 4 cas : le schéma permet de les illustrer : 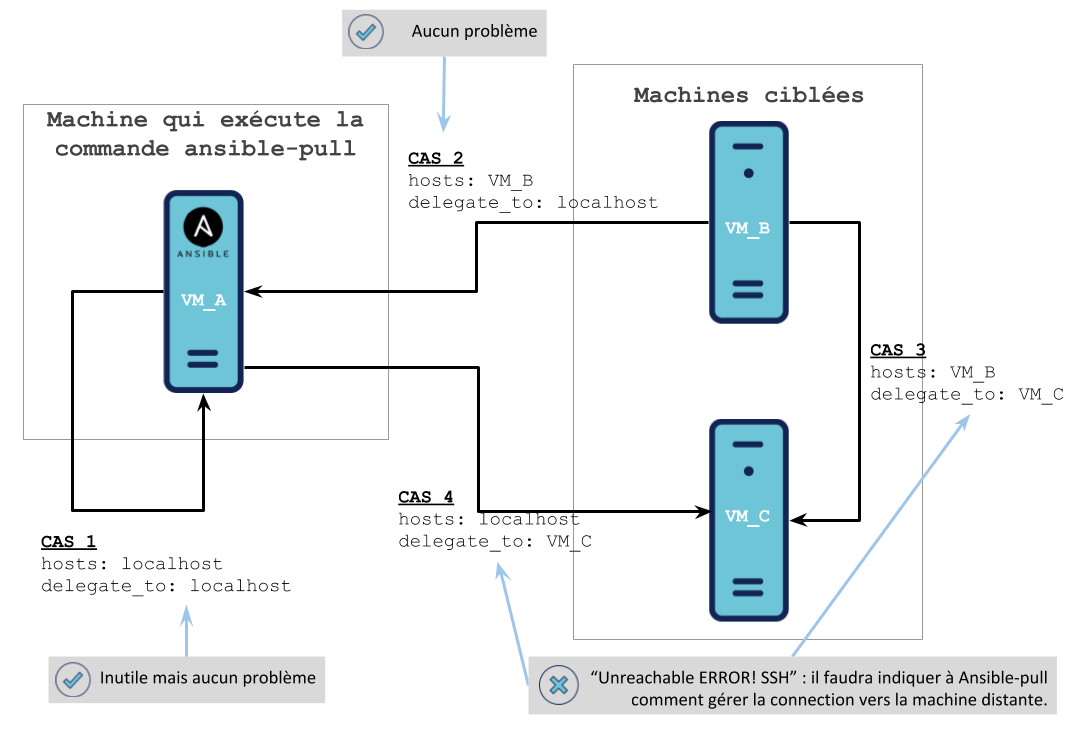
Aucun problème, cela fonctionne. Exemple de playbook :
- hosts: remote_vms[0]
tasks:
- name: Create a test file with a delegate_to localhost
delegate_to: localhost
copy:
content: "file content generated with delegate_to localhost"
dest: /tmp/test-file-delegate-to.txt
Sans surprise, le fichier /tmp/test-file-delegate-to.txt sera généré sur la machine qui exécute Ansible-pull.
Ici, sans aide pour lui indiquer comment établir la connection SSH, Ansible rencontrera une erreur : “Unreachable ERROR! SSH…”
Exemple de playbook :
- hosts: localhost
tasks:
- name: Create a test file with a delegate_to remote_vms[0]
delegate_to: remote_vms[0]
copy:
content: "file content generated with delegate_to remote_vms[0]"
dest: /tmp/test-file-delegate-to.txt

Même si nous venons de voir qu’il est possible de faire de la gestion multi-machines avec Ansible-pull en précisant à Ansible comment le faire, il est important de noter que ce n’est clairement pas le cas d’utilisation attendu : nous vous invitons à challenger la raison pour laquelle vous souhaitez faire cela et essayer de trouver une solution plus simple.
Dans le mode push par défaut d’ansible, ansible-vault est utilisé sur la machine de contrôle pour chiffrer et déchiffrer l’ensemble des secrets. À l’exécution, seul le sous ensemble de secret concernant une machine est envoyé sur les machines. La machine de contrôle constitue donc l’élément principal à sécuriser.
Ansible-pull continue d’offrir la possibilité d’utiliser ansible-vault : il n’y a donc pas de problème technique.
Par contre, le changement de modèle de connection implique que la clé de déchiffrement doit être distribuée sur chaque instance qui exécute Ansible-pull : toutes les machines qui utilisent Ansible-pull doivent donc avoir la clé de déchiffrement.
A minima, il est donc nécessaire de découper le fichier vault qui contenait l’ensemble des secrets en autant de fichiers que de typologies de machine possible, avec bien entendu une clé de chiffrement différente pour chaque fichier. Ce découpage entraînera également des duplication de secrets dans plusieurs fichiers, car plusieurs typologies de machines peuvent avoir besoin du même secret (token de connection au dépôt de binaire par exemple). La duplication de code n’est pas élégante, et implique d’être rigoureux au moment de la mise à jour d’un secret pour ne pas en oublier.
Dans le code source de l’exemple que nous avons déroulé plus haut, les modifications suivantes ont été effectuées pour implémenter un cas fonctionnel :
/etc/ansible-pull/.secret : contient le mot de passe de déchiffrement pour ansible-vault : Il sera référencé au lancement de la commande Ansible-pull avec le paramètre --vault-password-file/etc/ansible-pull/inventory : fichier d’inventaire : il contient 2 groupes qui seront nommés en fonction des variables node_type et env. Cela permettra de référencer les group_vars associées (group_vars/web pour les machines web, group_vars/db pour les machines db), et notamment les fichiers chiffrés avec ansible-vault qu’ils contiennent.Modification de code dans le fichier de configuration de cloud-init:
write_files:
- path: /etc/ansible-pull/.secret
owner: root:root
permissions: '0600'
content: |
${secret}
- path: /etc/ansible-pull/inventory
owner: root:root
permissions: '0600'
content: |
[${node_type}]
localhost
[${env}]
localhost
- path: /etc/ansible-pull/cron.sh
owner: root:root
permissions: '0744'
content: |
ansible-pull provision.yml --url ${git_repository} --accept-host-key -i /etc/ansible-pull/inventory -e node_type=${node_type} -e env=${env} --vault-password-file=/etc/ansible-pull/.secret
data "template_file" "script-web" {
template = "${file("${path.module}/user_data.tpl")}"
vars {
node_type = "web"
env = "${var.env}"
git_repository = "${var.git_repository}"
secret = "${var.web_role_secret}"
}
}
data "template_file" "script-db" {
template = "${file("${path.module}/user_data.tpl")}"
vars {
node_type = "db"
env = "${var.env}"
git_repository = "${var.git_repository}"
secret = "${var.db_role_secret}"
}
Chaque template_file contient les variables qui sont propres au rôle de machine associé.
- hosts: localhost
tasks:
- name: Write env_infos file in /etc folder
copy:
content: |
node_role: {{ node_type }}
env: {{ env }}
my_secret: {{ vault_example_secret }}
dest: /etc/env_infos
Le code complet de l’exemple se trouve dans le dépôt https://github.com/ylascombe/ansible-pull-demo sous le tag step3.
Une approche basée sur l’utilisation d’un tiers de sécurité comme Hashicorp Vault (à ne pas confondre avec ansible-vault) reste en revanche tout à fait pertinente : chaque instance porte sa propre identité auprès de Vault et peut donc accéder uniquement aux secrets qui la concerne. La mise en place d’un tel outil dépasse largement le cadre de cet article, nous ne détaillerons donc pas ce point.
Le fait qu’Ansible-pull soit relativement peu connu n’est peut-être pas anodin : il constitue un réel apport mais présente plusieurs limites importantes :
L’utilisation du mode pull d’Ansible n’est pas aussi simple qu’avec des outils nativement prévu pour cela. En revanche, il permet tout de même de répondre à des besoins spécifiques et précis, nous vous proposons 3 exemples d’utilisation :
cloud-init est souvent utilisé par les cloud providers pour offrir aux utilisateurs la possibilité de modifier/configurer les instances à leurs création et/ou démarrage. cloud-init permet d’effectuer de nombreuses tâches simple (création d’utilisateurs, de fichiers, configuration réseau, dépôt de clés SSH, …) ou plus complexes (installer certains utilitaires ou renforcer certains paramètres de sécurité). Les tâches les plus complexes sont souvent effectuées via des scripts shell appelés depuis le cloud-init.
Avec les différents systèmes d’exploitations et versions, il est assez difficile de maintenir et tester l’ensemble des scripts cloud-init/shell. Effectuer ces tâches avec du code Ansible plutôt que cloud-init permet d’améliorer la maintenabilité. Ici, utiliser Ansible-pull via cloud-init pour effectuer les tâches plus complexes est un bon cas d’utilisation.
S’il n’est pas possible de donner accès à des instances mais qu’il est tout de même nécessaire d’assurer la conformité avec un ensemble de règles, Ansible-pull peut-être installé et configuré au démarrage de la VM pour effectuer ces tâches.
Par exemple, dans un entreprise où l’équipe qui gère un middleware (agent de logs par exemple) souhaite effectuer l’installation et la configuration de cet agent sans avoir de compte applicatif sur celles-ci : ces actions peuvent être effectuées avec Ansible-pull.
C’est indéniable, Ansible possède de super atouts, et cette fonctionnalité contribue à en réduire ses points faibles. Cependant, nous pensons qu’il faut toutefois essayer de limiter l’utilisation d’Ansible-pull pour des cas précis et ne pas essayer de systématiser son utilisation en challengeant chaque cas d'utilisation potentiel.
L’utilisation du mode pull implique également de perdre la facilité d’orchestrer des tâches entre plusieurs machines, qui est une réelle force du mode push d’Ansible.
Lien vers le dépôt de code pullé par Ansible-pull