Les données textuelles en grande quantité sont difficiles à traiter et à interpréter. Il est possible de leur faire dire une chose et son contraire, de telle sorte que des statistiques calculées sur du contenu de réseaux sociaux n’ont de fait aucune valeur si on ne comprend pas la méthode par laquelle elles ont été obtenues. Dans son talk, Nicolas Cavallo nous propose de construire ensemble un cas d’usage d’analyse de tweets portant sur l’élection présidentielle de 2022.

Les élections présidentielles de 2022 surviennent dans un contexte où le poids des réseaux sociaux dans les décisions de vote fait surgir de plus en plus de polémiques, et ce, d’autant plus qu’on estime que 58% de la population mondiale utilise au moins un réseau social. Encore aujourd’hui, Twitter reste le réseau social le plus utilisé en politique. Le projet lavoixdeselections.fr est né d’une volonté de construire un outil pour comprendre ce qui se dit sur Twitter en temps réel.
Le site lavoixdeselections.fr comporte différentes sections qui permettent de visualiser les données Twitter entourant l’élection présidentielle. On peut y voir le vocabulaire de la veille, les tweets et hashtags les plus populaires, ainsi que l’évolution du poids des grandes thématiques, comme le climat, l’éducation, l’immigration, dans le débat. Nicolas nous propose d’écrire cette histoire ensemble, pour comprendre ce que disent les candidats à l’élection présidentielle sur Twitter.
Tout commence avec un tweet. Il s’agit du contenu diffusé par une personne à un instant donné, et qui peut mener à diverses formes d’interaction, comme des retweets et des likes. Notre travail de data scientist consiste à en extraire des informations clés par traitement automatique des langues (TAL, aussi connu comme NLP).
Comme le tweet est formé de texte non structuré, la première étape consiste à le nettoyer pour le rendre plus facile à analyser. Cette étape implique généralement une réduction volontaire du niveau d’information contenu dans le texte.
Les données nettoyées sont consommées par des modèles qui serviront à enrichir et à structurer leur contenu. Dans l’exemple proposé, ils serviront à identifier les thématiques et les candidats qui sont (ou ne sont pas) mentionnés dans le tweet.
Il existe différents types de modèles qui peuvent être implémentés, et chacun nécessitera un nettoyage différent au préalable.
Bag of words : Ce modèle simple travaille à partir du vocabulaire contenu dans le tweet.
Transformers : Ce modèle plus complexe s’appuie sur des réseaux de neurones et est en mesure d’encoder la sémantique des mots ainsi que la structure des phrases.
Les tweets sont collectés en continu par le biais de l’API de Twitter en filtrant les tweets qui contiennent des hashtags parmi une liste préétablie, ou qui proviennent de comptes spécifiques (notamment ceux des candidats et des partis politiques). Les retweets qui suivent sont également collectés. Des dizaines de tweets sont ainsi extraits et traités chaque seconde par le système, pour un total de 29 millions en un an d’activité.
Maintenant que nous avons accès à un flux de données et que nous savons la structurer et l’enrichir d’information intéressante, il nous reste à découvrir comment faire parler cette donnée.
Pour ce faire, Nicolas nous présente une première visualisation de l’évolution de la thématique du climat dans les tweets récoltés chez les huit principaux candidats.
À partir du graphique présenté, il lance la conclusion suivante :
« Le climat ne concerne que 5% du débat politique. »
L’absence de réaction dans la salle montre que l’auditoire ne saisit pas tout à fait le piège que nous tendent les statistiques présentées sans explication.. Nicolas nous rappelle qu’il ne faut pas faire confiance aveuglément à des chiffres, peu importe les qualifications de celui qui les présente. Il faut s’intéresser à la méthodologie employée, car elle nous informe, tout autant que le résultat lui-même, sur l’objet d’étude.
« Selon la méthodologie qu’on choisit, le message va être légèrement différent. Il faut apprendre à retirer de l’information de la façon dont on va faire parler les données. »
La première question à se poser est : Qu’est-ce qu’on observe ?
Pour y répondre, il convient de définir la population à étudier. Ensuite, comme on n’observe souvent qu’un échantillon de cette population, une fonction d’extrapolation est nécessaire pour généraliser les résultats observés.
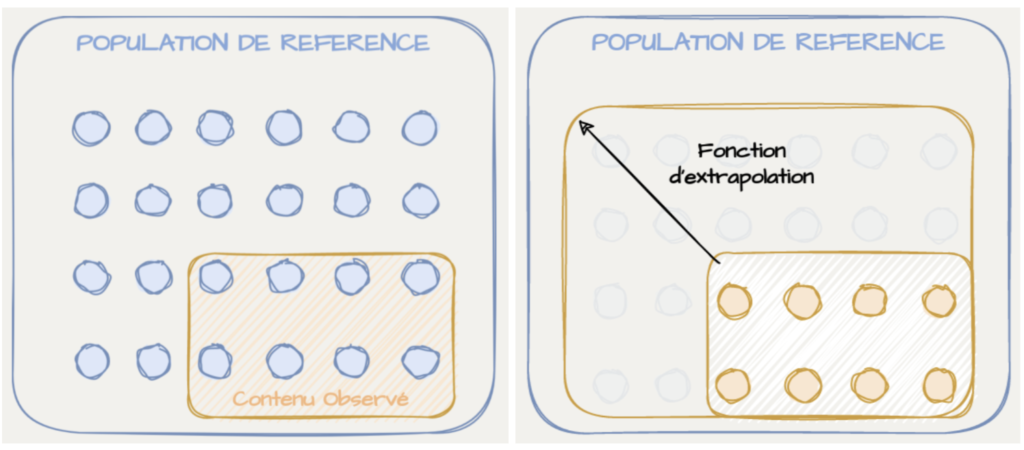
Le point à retenir ici est que la fonction d’extrapolation peut être grandement simplifiée si l’on restreint la population de référence. Nicolas nous montre qu’en spécifiant plus strictement cette dernière, il s’évite la tâche difficile de devoir extrapoler les résultats obtenus sur Twitter à la société française dans son ensemble.
| 1. « Activité politique française » | 🤔 |
| 2. « Activité politique française sur Twitter » | 🙂 |
| 3. « Activité politique française sur Twitter des principaux candidats » | 😄 |
La réflexion sur la population de référence est importante en amont, mais en fait, c’est le choix des éléments et leur fonction d’extrapolation qui permettra de vraiment fixer la population de référence. Il nous propose quatre formes de représentations, ainsi que la population de référence qui en ressort.
Les fonctions d’extrapolations proposées se complexifient de plus en plus, et on remarque que plus on essaie d’obtenir une population de référence grande et intéressante, plus la fonction d’extrapolation devient instable. En effet, dans la quatrième forme de représentation, baptisée INTENTIONS, la fonction d’extrapolation dépend de résultats de sondage qui sont collectés par un tiers et qui peuvent fluctuer. Sans s’avancer sur une préférence pour l’une ou l’autre des formes, Nicolas nous propose de les appliquer à un cas d’usage de comparaison du poids de différentes thématiques dans le débat politique.
L’analyse permet d’évaluer le poids, en pourcentage, de trois thématiques sur Twitter: le climat, l’éducation et l’immigration.
On remarque qu’en fonction de la représentation choisie, on peut générer des messages totalement différents sur le poids. Or, Nicolas nous précise que l’important n’est pas tant le nombre dans l’absolu, comme 3% ou 5%. Lorsque nous avons bien fixé le périmètre, les tendances peuvent être assez proches, quelle que soit la représentation, comme le montre le graphique suivant.
Par l’entreprise de son projet lavoixdeselections.fr, Nicolas nous a fait découvrir une des problématiques majeures que l’on rencontre avec des données politiques tirées des réseaux sociaux : comment faire parler la donnée. On a vu que ce n’est pas trivial, car il y a une rigueur méthodologique nécessaire si on ne veut pas faire n’importe quoi.
« Avec une seule façon de faire parler la donnée, on est capable de créer 1001 façons de raconter une histoire. »
En paraphrasant George Box, Nicolas affirme que « toutes les façons de faire parler la donnée sont fausses… Mais certaines sont utiles. » L’utilité ici se révèle par le fait qu’on arrive à en tirer un message. Et ce message, pour qu’il soit clair et que les résultats soient compréhensibles, demande que nous ayons décrit la méthodologie appliquée. Nicolas nous a convaincus que la meilleure façon d’être capable de lire correctement des résultats est de savoir en refaire l’analyse et ainsi pouvoir poser les bonnes questions méthodologiques lorsqu’on est confronté à des statistiques.. Nicolas conclut en nous invitant à ne pas s’aé/rrêter à la forme du discours et de la présentation pour juger de la qualité du message, ni à faire confiance aux chiffres qui sortent de nulle part, mais plutôt à vérifier la façon dont ces derniers ont été produits.